




ニューラルネットワークの中身を分割してAIの動作を分析・制御する試みが成功、ニューロン単位ではなく「特徴」単位にまとめるのがポイント

GoogleやAmazonが投資するAIスタートアップのAnthropicの研究チームが、ニューラルネットワークがどのように言語や画像を扱っているのかを解き明かす研究において、個々のニューロンを「特徴」と呼ばれる単位にまとめることでニューラルネットワークの中身を解釈しやすくなるという研究結果を発表しました。
Anthropic \ Decomposing Language Models Into Understandable Components
https://www.anthropic.com/index/decomposing-language-models-into-understandable-components
大規模言語モデルは多数のニューロンが接続されたニューラルネットワークで、ルールに基づいてプログラミングされるのではなく、多数のデータを元にトレーニングを行うことでタスクを上手にこなす能力を身につけています。しかし、個々の単純な計算を行うニューロンが複数集まることでなぜ言語や画像を扱えるようになるのかはわかっておらず、モデルに問題が見つかったときの修正方法を把握したり、モデルの安全性を証明したりするのは困難です。
Anthropicの研究チームはまず個々のニューロンの動作について調査を行いましたが、ニューロン一つ一つとネットワーク全体の動作との間に特別な関係を見つけることができなかったとのこと。例えば、下図左側では83番ニューロンが韓国語や引用、HTTPリクエスト、対話文などさまざまな場面でアクティブになっていることがわかります。
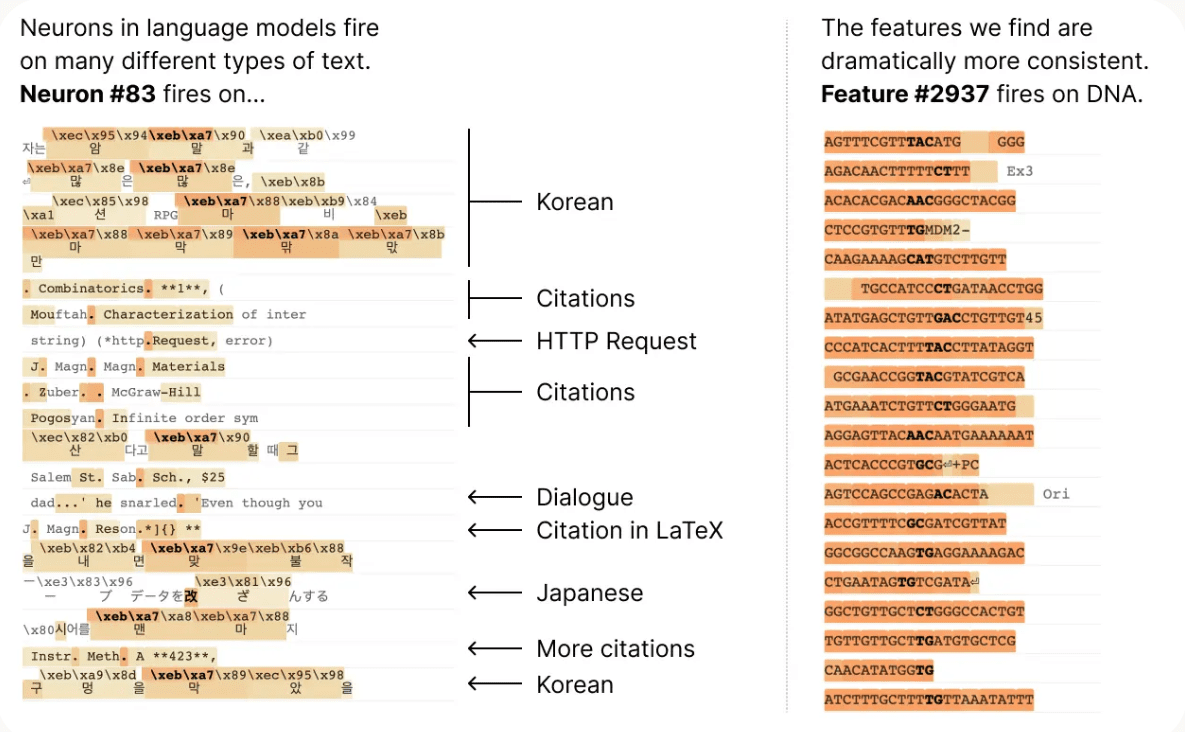
Anthropicの研究チームは2023年10月4日に発表した論文「Towards Monosemanticity: Decomposing Language Models With Dictionary Learning(単一意味性を目指して:辞書学習による言語モデルの分解)」で、個々のニューロンよりも優れた分析単位が存在すると示しました。研究チームは新たな分析の単位を「特徴」と名付けており、小さなトランスフォーマーモデルを「特徴」に分解する機構も開発したとのこと。
下図はトランスフォーマー言語モデルの512個のニューロンを含むレイヤーを4096個の特徴に分解した図です。「法律文章に反応する特徴」「DNA列に反応する特徴」など、個々のニューロンを見る場合よりもさまざまな機能の実現に関わっている部分をうまく示すことができています。

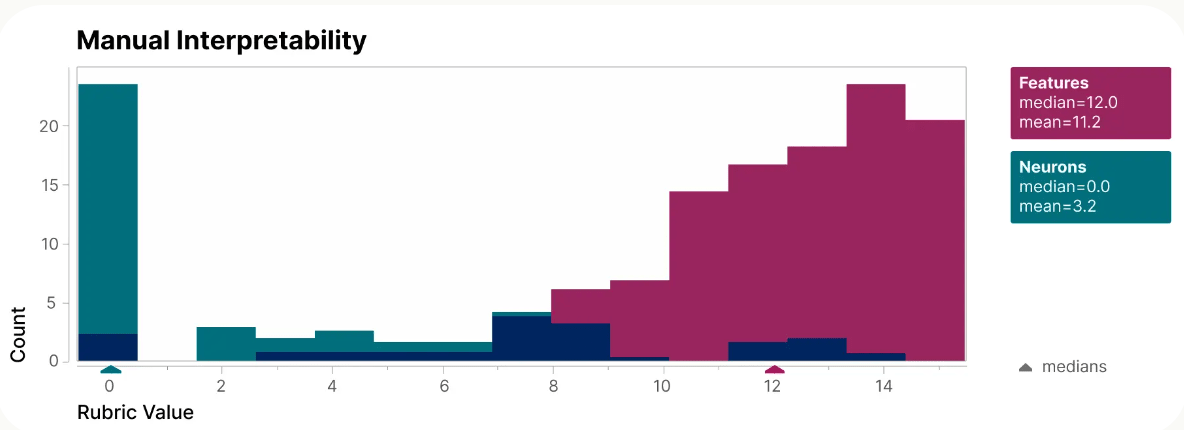
下図は「ニューロン個別の場合」と「特徴で分解した場合」のそれぞれについて人間に「解釈可能性」を評価してもらうブラインドテストを行った結果です。緑色で示された「ニューロン個別の場合」の結果はほぼ0点に集中しているのに対し、赤色で示された「特徴で分解した場合」の結果は高得点を獲得しました。
また、「特徴」の値を高い値で固定することで一貫したテキストを生成することが可能になります。

モデルの解釈可能性を向上させることで、最終的にはモデルの動作を内部から監視・制御することが可能になり、社会や企業での採用に必要不可欠な安全性と信頼性を確保することができます。Anthropicは今回の小規模な実証モデルに続き、何倍も大きく複雑なモデルへスケールアップすることに取り組む予定と述べられています。
・関連記事
AIは人間と同じように言葉の意味を「理解」しているのか? - GIGAZINE
生成AIの飛躍的性能アップの秘密「グロッキング」とは? - GIGAZINE
OpenAIが「言語モデルに言語モデルを説明」させるデモンストレーションツールを公開 - GIGAZINE
AIの台頭で生まれる「新興宗教」とそのリスクとは? - GIGAZINE
AIが生成した絵や文章に著作権は認められるのか?アメリカ著作権局がガイダンスを発表 - GIGAZINE
・関連コンテンツ







