Microsoftがたった13億のパラメーターでGPT-3.5超えのHumanEval50.6%をたたき出す「phi-1」を発表

LLaMaやFalconといった小型の大規模言語モデル(LLM)が矢継ぎ早にリリースされる中、Microsoft ResearchのAI研究チームが、プレプリントサーバーのarXivで、Transformerベースのモデル「phi-1」を発表しました。このモデルは、パラメーター数がGPT-3.5の100分の1以下の13億しかないにもかかわらず、テスト用データセット・HumanEvalでGPT-3.5を上回る成績を収めたことが報告されています。
[2306.11644] Textbooks Are All You Need
https://doi.org/10.48550/arXiv.2306.11644
Microsoft Releases 1.3 Bn Parameter Language Model, Outperforms LLaMa
https://analyticsindiamag.com/microsoft-releases-1-3-bn-parameter-language-model-outperforms-llama/
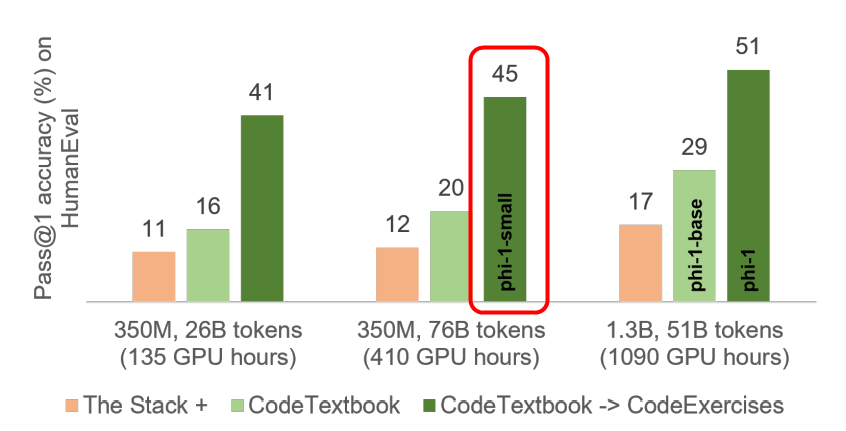
以下は、phi-1のパフォーマンスを他のモデルと比較したものです。phi-1はプログラミング能力を評価するためのデータセットであるHumanEvalで50.6%、MBPPで55.5%と、高い精度を示しました。この結果はGPT-4の67%には及びませんが、パラメーター数が1750億のGPT-3.5を上回るものでした。

phi-1がいかに軽量なのかについて、論文の著者のひとりであるセバスチャン・ビューベック氏は「他のHumanEval50%超えのモデルは1000倍も大きいです。例えば、WizardCoderはモデルサイズが10倍、データセットが100倍でした」と説明しています。
New LLM in town:
— Sebastien Bubeck (@SebastienBubeck) June 21, 2023
***phi-1 achieves 51% on HumanEval w. only 1.3B parameters & 7B tokens training dataset***
Any other >50% HumanEval model is >1000x bigger (e.g., WizardCoder from last week is 10x in model size and 100x in dataset size).
How?
***Textbooks Are All You Need*** pic.twitter.com/lNvqvjkW0w
「Textbooks Are All You Need(必要なのは教科書だけ)」と題された論文によると、このモデルはインターネットから収集された教科書品質のデータセット60億トークンと、GPT-3.5から生成された教科書データセット10億トークンを使い、8台のNVIDIA A100によるわずか4日間のトレーニングで作られたとのこと。
特徴的な論文の題名は、Transformerモデルの基礎を打ち立てた論文「Attention Is All You Need(必要なのはアテンションだけ)」にちなんだものだと考えられます。
研究チームはまた、phi-1と同じパイプラインでトレーニングされたさらに小型のモデル「phi-1-small」も開発しています。「phi-1-small」は、パラメータ数が3億5000万とさらに少ないにもかかわらず、HumanEvalで45%を達成しました。
共著者のロネン・エルダン氏は、「コーディングに教科書品質のトレーニングデータを使用したところ、予想以上の結果が得られました」と述べています。なお、エルダン氏によるとphi-1はまもなくAIプラットフォーム・Hugging Faceで利用可能になるとのこと。
High-quality synthetic datasets strike again. Following up on the technique of TinyStories (and many new ideas on top) at @MSFTResearch we curated textbook-quality training data for coding. The results beat our expectations.
— Ronen Eldan (@EldanRonen) June 21, 2023
For skeptics- model will be on HF soon, give it a try. https://t.co/LSkNuRpLjr
この論文を取り上げたソーシャルニュースサイト・Hacker Newsのスレッドで、「GPTによって生成された高品質の合成データセットがなければこれは不可能でした」と指摘されている通り、phi-1の重要性は「モデルのサイズを大きくする代わりに質を向上させることで高い性能のモデルを得ることができる」という点にあります。
例えば、GPT-4の新たな対抗馬と目されているオープンソースのモデル「Orca」は、パラメーター数が130億と比較的軽量ですが、GPT-4のデータで学習することで、OpenAIの製品を上回るベンチマーク結果を見せました。
一方で、AIが生成した情報をAI学習に用いる手法には懸念も提起されています。2023年5月にarXivで公開された論文「The Curse of Recursion(再帰の呪い)」では、他のLLMのデータで学習することで発生する「データポイズニング」により、新しいモデルの精度が低下することが示されました。ChatGPTのようなプロプライエタリ、つまり非公開の強力なモデルからの出力で弱いモデルをファインチューニングすることによる弊害は、「The False Promise of Imitating Proprietary LLMs(プロプライエタリなLLMの模倣という偽りの約束)」と呼ばれているとのことです。
AI成果物が急増したことで「AI生成コンテンツをAIが学習するループ」が発生し「モデルの崩壊」が起きつつあると研究者が警告 - GIGAZINE

・関連記事
GPUメモリが小さくてもパラメーター数が大きい言語モデルをトレーニング可能になる手法「QLoRA」が登場、一体どんな手法なのか? - GIGAZINE
大規模言語モデルの出力スピードを最大24倍に高めるライブラリ「vLLM」が登場、メモリ効率を高める新たな仕組み「PagedAttention」とは? - GIGAZINE
大規模言語モデルの開発者が知っておくと役立つさまざまな数字 - GIGAZINE
「オープンソースは脅威」「勝者はMeta」「OpenAIは重要ではない」などと記されたGoogleのAI関連内部文書が流出 - GIGAZINE
オープンソースで商用利用可能な大規模言語モデル「Falcon」が登場、オープンソースモデルの中では最高の性能に - GIGAZINE
1600以上のAPIを適切に呼び出してAIに付き物の「幻覚」を大幅に減らす言語モデル「Gorilla」が公開される - GIGAZINE
・関連コンテンツ