こちらの記事をご覧いただきありがとうございます。
ちゃんと内容が伝わるようなタイトルを考えたらラノベみたいになってしまい、かえってわかりにくい気がしてきました。
以前からいくらかSUUMO物件について機械学習を用いたデータ分析を行っています。
今回は、10万件以上の物件データを与えてなかなか高精度な家賃予測が可能となった機械学習モデルが、クソ失礼にも家賃が安いと査定した高額物件がいくらかあったので、何を考えてクソ失礼な査定となったのかを調べます。
もしかしたらボッタくりかもわかりませんからね。楽しみですね。
モデルの学習について
基本的には前回記事と同じです。
使用した機械学習モデル
以前から引き続き LightGBM を使用しています。
使用したデータ
SUUMOからスクレイピングした物件データ 196093 件を使用しています。
うち137265件を学習データ、58828件をテストデータとしています(7:3に分けています)。
説明変数は12種類、前回記事で厳選した変数から一部を変更して使用します。
SHAPについて
先に参考にしたページを貼っておきます。
詳しくはこちらをご覧ください。
今回は、私が最近勉強して習得した「SHAP」という技術(?)を使用します。
詳しい説明は割愛しますが、機械学習モデルが何を考えているのかを教えてくれます。
ちょっと長いですが大事なので説明を見ていってください。
例えば下の図について、こちらの物件に対して機械学習モデルがどう判断したのかをSHAPによって可視化したものです。

図の見方を説明します。
まずグラフの横軸が 家賃の予測値 です。
ただし、モデルには家賃を10を底にした対数に変換して与えています。
実際の家賃は20万ですが、$ log_{10}20 \fallingdotseq 1.284 $ であり、グラフの上にある色付きx軸の1.284のところと繋がっています。
グラフの左にあるのが変数です。
例えば一番上にあるのが 面積 の変数です。折れ線が面積のところで0.95くらいのところから1.284に変化しています。また(81.84)と書いてあるのは、この物件が81.84[m2]であることを表しています。
これはつまり、この物件は面積が81.84[m2]であるおかげで予測値が0.95くらいから1.284まで向上したことを表します。
(実際は変数の情報を順番に利用しているわけではありませんが)
変数は上のものほど影響力が高いです。
一番下は見切れていますが 最寄駅からの距離 です。最寄駅からの距離は査定にほとんど影響していません。
一番上が 面積 で、査定に最も影響を与えています。
$ 10^{(1.284 - 0.95)} \fallingdotseq 2.16 $ ですので、予測値におよそ2.16倍の影響を与えています。結構エグいですね。
駅 の(145)ってなんやねんってお思いだと思いますが、実際は大森駅です。
機械学習モデルは数字じゃない情報を使えないので、駅ごとに対応する数字を割り当てています(ラベルエンコーディングといいます)。
0.95あたりにある縦線は、家賃の予測値の平均です。
対数の状態で 約0.978 、対数から戻して 約9.51万 です。
↑の説明をグラフに書き足すと、こうなります。

まあ上にいる変数が強いってのがご理解いただければたぶん大丈夫です。
クソ失礼な査定をした物件
ここからSHAPを使って、機械学習のクソ失礼な査定を分析します。
家賃69万、予測値28.1万
こちらの物件です
実際の家賃は 69万 ですが、クソ失礼にも機械学習モデルは 28.1万 と査定しました。41万 程の差があります。
なぜこのような査定を下したのでしょうか?
SHAPを使用して、機械学習モデルの判断を確認します。

間取り と 面積 が査定をあげていますが、築年数 や 市区町村 がマイナスとなっているようです。
物件情報を確認すると、
- 面積:219.33 [m2]
- 間取り:5LDK
- 築年数:築31年
- 市区町村:杉並区
となっています。

この物件デカすぎんだろ…
さすが1戸建て、かなりデカい物件です。10人くらい住んでも問題なさそうです(たぶん)。
しかしこれでも 築31年 と 杉並区 であるおかげで査定を下げているようです。
賃貸って古いってだけでも結構家賃に影響するんですね…。恐ろしい。
実際住んでみればほとんど気にならないような気がするのですが、そうでもないのでしょうか?結構気にする人多いんですかね?
あと杉並区で結構家賃下がるんですね。杉並区はお得な物件多いかも?
見た感じは良さげな物件に見えますが、結構古めなのと立地の影響で予測が下げられていました。
いいと思うんですけどね。クソ広いし。都心に出るもの新宿まで電車で15分くらいですか?そんなに悪くないような気がします。
家賃150万、予測値64.1万
こちらの物件です.

実際の家賃はなんと 150万 の超高額物件です。
写真でも大層ご立派な佇まいがうかがえます。
しかし機械学習モデルはこの物件を 64.1万 と査定しました。半額以下です。なんとクソ失礼なのでしょうか。
なぜ機械学習モデルはこのような査定をしたのでしょうか?SHAPを使って確認します。

全体的にプラスの評価が出ています。
さすがは高額物件、素晴らしいですね。
マイナス評価がついているのは 築年数 だけのようです。
築22年ってマイナス評価なんですね…。まだまだ数十年は住めそうなものですが。
いやでも平成と令和の瀬戸際くらいに生まれたと考えると、割と時代のずれもありそうな気がしてきました。時の流れは残酷ですね。
マイナスが築年数だけでしたが、築年数がめちゃくちゃ評価を下げているわけでもなさそうです。
築年数の影響で予測値が 1.1 → 1.0 に変化しています。
$ 10^{1.1-1.0} \fallingdotseq 1.259 $ ですから、査定への影響は 1/1.259倍です。
仮に築年数の影響をなくしても $ 64.1 × 1.259 \fallingdotseq 80.57 $ です。まだまだ予測値の半分にしかなりません。
これはつまり、他の側面も超高額と呼ぶには足りないと評価されている可能性が高いです。
ここで物件情報を確認してみましょう。

立地は 渋谷区代々木 とかなり良さげな気がします。
電車のアクセスも 徒歩10分圏内に小田急線と東京メトロ があります。
間取りは 5LDK とかなり広く、面積も 328.9m2 とバカ広いです。
これだけやってもダメなのか…?
かなり良質な条件がそろっているように見えますが、それでも機械学習モデルは超高額だと思えないようです。
順当に評価が高い高額物件
じゃあ順当に超高額だと予測された超高額物件はどうなっているのでしょうか?
家賃350万、予測310万
こちらの物件を見てみましょう。

家賃は驚愕の 350万 です。
1カ月住むだけでも年収が消し飛びますね…。
機械学習モデルは 310万 と予測しました。 40万 の差がありますが、元が350万ということを考えれば、それなりにうまく予測できているような気がします。
この予測のSHAPを見てみます。

ひえ…。めちゃめちゃ右に伸びていきますね。
先ほどの150万の物件と横に並べてみましょう。
左が150万、右が350万の物件です。
比較してみると、一番大きく影響している面積でも、右のほうが伸びが大きいですね。
ほか、どの特徴を見ても右の350万の物件は伸びが良いように思えます。
物件情報も確認してみましょう。

SHAPの 駅 による伸びが大きいですが、最寄り駅は 目黒駅 です。これまた強そうですね。
それと先ほどはマイナスになっていた 築年数 もこちらでは 築5年 でかなり高評価がついています。
右のグラフで上から6番目が見切れていますが 皇居からの距離 です。350万の物件は6.3kmなので近いとも遠いともなくらいですが、これも加点されていますね。
左のグラフだと上から8番目です。150万の物件では5.9kmですが控え目な加点になっています。
ん?150万の物件では5.9㎞で控え目な加点ですが、350万の物件では6.3㎞でそこそこの加点がもらえています。350万の物件のほうが都心から遠いはずなのですが…。
これはおそらく「相互作用」によるものです。他の情報の影響も含めて考えた結果、同じ値でも評価点が変わることがあります。
今回の事例の場合、350万の物件は品川区の中でも比較的港区や目黒区に近い位置にあることが確認できました。港区は立地最強クラスですので、「港区に近い6.3km」と考えて評価点が上がったのかもしれません。
逆に150万の物件は渋谷区の中でも新宿や杉並区に近い位置にありました。渋谷の中では都心から離れるので、加点が控え目なのかもしれません。
もちろん他の特徴との相互作用の可能性もあります。
逆に評価がやけにクソ高い物件は?
先ほどは実際の家賃よりかなり低い予測をした失礼な例を見てきましたが、逆に実際の家賃よりも高い評価を付けたいかにもお得そうな物件も見てみましょう。
家賃7.7万、予測35.7万
こちらの物件です。

実際の家賃は 7.7万 と平均よりも低いです。これなら私も節約すれば住めそうです。
して、機械学習モデルは 35.7万 と予測を出しました。実際の家賃のおよそ5倍です。破格ですね。
この物件の予測もSHAPで確認してみます。

先ほどとは打って変わって 駅 の情報が最も大きく影響しています。
次いで見切れていますが 最寄からの距離 です。およそ1.2kmと普通に見えますが、評価が高いみたいですね。
これも「相互作用」がありそうです。最寄り駅がとても優秀であるため、それに近いという情報もまた優秀なのでしょう。
他の要素も総じて優秀なようです。
築年数 や 面積 など多くの要素がプラスに働いています。
マイナスになっているのは 間取り くらいです。
物件情報も確認してみます。
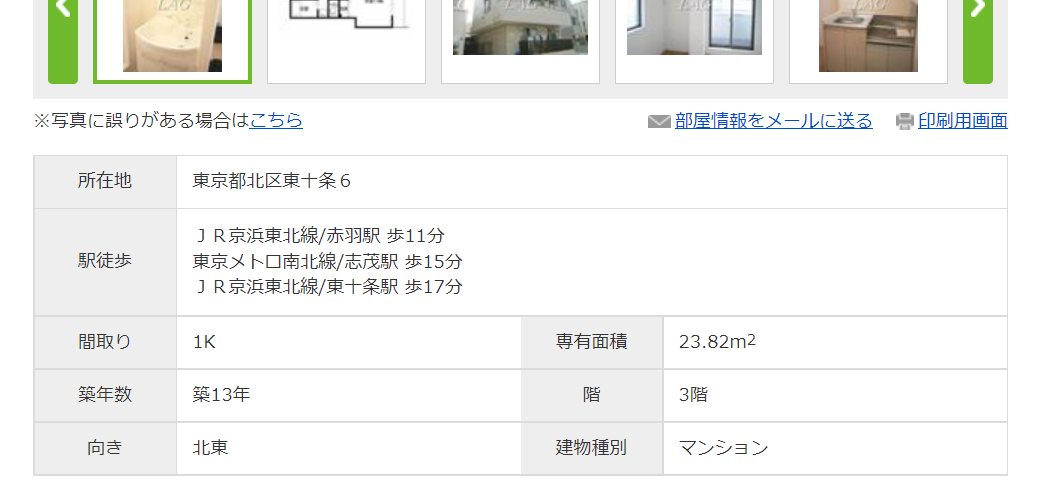
マイナス要素の間取りは 1K です。お安めの間取りですね。
場所は北区、最寄駅が赤羽、面積は23.82m2、築13年、3階…。見るからに普通な気がします。
立地については全然詳しくないですが、北区も赤羽駅も相場が高そうなイメージがありません。
35万クラスの物件を8万で借りられる、とはいかないようです。
実は住んでみるとかなり「住めば都」だったりするのでしょうか?
予測も実際の家賃もクソ低い物件はどうなる?
先ほどまでは各要素がプラス評価の物件が多かったですが、マイナス評価だらけの物件も見たくなりました。
家賃がクッソ安い破格物件だとSHAPはどうなるのでしょうか?
家賃1万、予測値2.7万
※2022/10/17追記
コメントからご指摘いただきました。
家賃1万は期間限定で実際は3万円、また管理費1万5千なので、実際にかかる費用は 4万5千 です。
4.5倍!?表向きの1万と全然違うじゃないですか!
皆さんは私を教訓にして細かいところまでよく確認してくださいね。安い物件は特に。
こちらの物件です。

家賃は驚愕の 1万 です。目を疑いたくなるほどの安さですね。そんな物件あるんだ…。
写真の建物もキレイです。何か訳あり物件だったりするのでしょうか…?
では、SHAPを見てみましょう。

おお、全要素がマイナスですね!
全項目で予測値を下げています。安さへのこだわりを感じます。
実際、家賃1万円を目指して極力コスト削減した結果だとしたら、この物件を作った人は相当やり手なんじゃないでしょうか。
物件情報も確認します。

面積は驚きの 7 m2 です。クッソ狭いですね。
これには理由があり、キッチン、トイレ、シャワーなどは建物内の共有スペースとして作られています。
部屋は本当に「空間」しかないっぽいですね。道理で安いわけだ。
また、共有スペースとかの情報をモデルに与えたわけでもないのに、それなりに近い予測を出せているのも驚きです。面積から判断できるか…?
安い物件にはちゃんと安いと判断できるだけの特徴が備わっていました。
終わり。
いかがでしたでしょうか。
今回はSHAPを用いて機械学習モデルのクソ失礼な判断を可視化してみました。
高いには高いなりの、低いには低いなりの理由が感じられました。なかなか面白かったです。
相互作用のあたりは物件1件ずつ見ても感じにくいですが、SHAPは評価の平均をとったグラフを作ることも出来たり、各特徴の値と相場への影響をグラフにすることもできます。
言葉だとイメージしづらいですね。次回の記事にその辺を使ってみます。相互作用を感じられる結果が見られるといいですね。
個人的には、予測が高い低いよりも、なんでそうなるの?という方が気になったりするので、こういうSHAPとかの技術でそれが知れるのはとても面白いです。
しばらくはSUUMOと戯れますが、いずれ他のデータでも分析したいです。
他のSUUMO記事
まとめ記事書いたのでぜひご覧ください。