6万個のHTMLの文字コードをEUC-JPからUTF-8に変えた話

はじめに
私は、とあるウェブサービス運営会社の開発部でエンジニアとして働いている。
私の会社では様々なサービスを自社で開発および運営している。私の会社の開発部では、システムのレイヤーごとに部署が分かれていて、
サーバーやネットワークなどのインフラ環境を整えるインフラ部
サーバー上でウェブアプリケーションの開発・運用を行なうアプリ部
ウェブアプリケーション上で実際の画像や文章などのコンテンツやフロントエンド周りを製作する製作部
の主に3つの層がある。その中で私は、アプリ部に所属するアプリケーションエンジニアである。
これは、私が仕事で経験した「6万個のHTMLの文字コードをEUC-JPからUTF-8に変えた」ときの話である。
経緯
私が担当している自社サービスの一つに、自社のキャンペーンコンテンツなどの膨大な数の静的なウェブページを提供するサーバーがある。静的ページ(=同じURLなら誰が見ても同じ)なので、サーバーサイドにアプリケーションは存在せず、ただ単にApacheがHTMLをユーザーに返すだけの単純なサーバーである。
この静的ページ群は自社のサービスの中では歴史が古く、自社の各種キャンペーンの案内、特集コンテンツ、他社とのコラボ企画ページなど多岐にわたるコンテンツを提供してきた。現在この静的ページ群を主に運用しているのは、総勢数百名におよぶ製作部の人たち(社外委託も含む)である。一方で、アプリ部の担当エンジニアは今は私1人だけである。サーバー上にアプリは無いのだから、アプリ部が薄くなるのはまぁ当然である。
この静的ページ群は長年ほとんど何の問題も無く運営されてきた。製作部がコンテンツを作ってひたすらリリース…をくり返すだけなのだから、コンテンツ自体に誤りなどが無い限り、トラブルなど何も起きないのである。
しかし、長年関係者全員が目を背けてきたことが一つあった。
そう、全てのHTMLの文字コードがEUC-JPだったのである。
EUC-JPとは日本語の文字コードの一種で、現在主流のUTF-8が普及するより前にShift_JISなどと並んでよく使われていたものである。UTF-8が普及する前は、ウェブページで使う日本語の文字コードと言えば、事実上Shift_JISかEUC-JPの二択だった。Shift_JISの方がWindowsやMacなどの一般の環境では普及していたものの、EUC-JPにはプログラムで扱いやすいという特徴があったため、この静的ページ群の運用が始まったとき(おそらく2000年前後?)に文字コードとして採用されたものと思われる(採用したのは私ではない)。
それから何年の月日が流れたか。今ではUTF-8(Unicode)で世界中の言葉や絵文字が自在に表示できるようになり、世の中のほとんどのウェブサイトもUTF-8を採用するようになったというのに、この我が社の静的ページ群は未だに全てのHTMLがEUC-JPだったのである。とはいえ、別に問題無く表示はできるので、一般のユーザーにすぐに何か悪影響が出ることはない。しかし、社内では以下のような問題が年々少しずつ顕在化してきていた。
エディタや統合開発環境を始めとする世の中の多くのソフトウェアが、UTF-8を標準にするようになった。
UTF-8で運営している自社の他のサービスとの連携が難しい。
今からわざわざEUC-JPに対応するコストが高いため、新しいアプリやツールの開発ができない。
EUC-JPを知らない外国人エンジニアや若手エンジニアが年々増え、その都度経緯を説明しなければならない。社外委託先にも事情の説明が必要となることがあった。
EUC-JPは今では少数派になってしまったので、ブラウザなどがある日突然EUC-JPのサポートを終了するリスクがある(可能性は低いと思うが、近年のHTTPS化の流れなどを見ていると、Chromeとかなら本当にやりかねない)。
専門知識を持つ社外の人からのイメージが悪化する(例えば、転職活動中のエンジニアが「あの会社はサイトが未だにEUC-JPだから行きたくない」となる)。
静的ページ群の規模を考えると、「明日からUTF-8にしよう!」と言って急にできるようなものではないことは誰の目にも明白であった。万が一「来月からChromeでEUC-JPが表示できなくなる!」などという事態になってから騒ぎ出したのでは遅いのである。
こうして、約6万個のHTMLからなる静的ページ群をUTF-8化するというプロジェクトが始まった。
数々の問題点
6万個のHTMLの文字コードをユーザー公開したままどうやって変更するか。それは、さながら毎日の電車の運行を続けながら線路の幅を変更するような難しさがあった。何しろ数が多すぎて「いっぺんにやる」ということが不可能なのである(単純にファイルの数が多いだけでなく、製作担当者の数も膨大なのである)《問題点1》。
初めに出たアイデアは、小さなディレクトリ単位で少しずつUTF-8化していくというものである【アイデアA】。ウェブサーバーは昔ながらのApacheなので、各ディレクトリに.htaccessを置けばディレクトリ単位で文字コードのコントロールはできる。
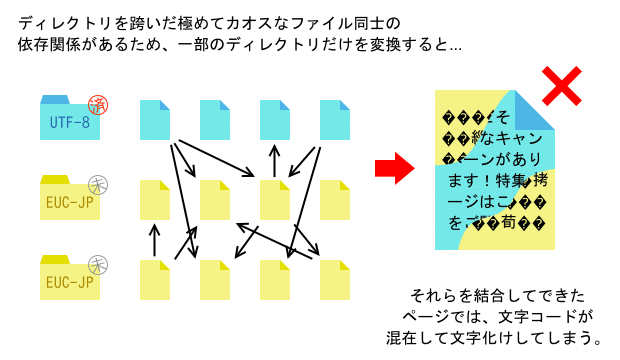
しかし、この静的ページ群では、各HTMLがSSIによって他のHTMLを多数インクルードしているというHTML同士の依存関係があるため、UTF-8化したディレクトリのHTMLが、まだEUC-JPのディレクトリのHTMLをインクルードしたら文字コードが混在して文字化けしてしまう。この膨大なインクルードの依存関係を全て解決しながらディレクトリ単位のUTF-8化を安全に進めるのはほぼ不可能であった《問題点2》。
次いで出たのは、サーバー側でリアルタイムに文字コードを変換してユーザーに提供するというアイデアである【アイデアB】。Apacheには文字コードを変換するモジュールもあるので、このような類のものを利用してサーバー上のファイルはEUC-JPのまま、ユーザーにはUTF-8で返そうというものである。
しかしこのような単純な変換の場合、サーバー上のファイルが必ずEUC-JPでなければ正しい変換が行なわれないため、「UTF-8に変換するためにEUC-JPで作らなければならない」という意味不明な状態が永久に続くことになり、問題解決どころかむしろ混乱が増すだけである。また、実際には、UTF-8化にあたって変換が必要なのは単純に文字コードだけではなく、<meta>タグ、<form>タグ、<script>タグなど他にもいろいろあり、そこまで器用に変換してくれるモジュールは見つからなかった《問題点3》。
ここまでをまとめると、大きな問題点は以下の3つであった。
《問題点1》規模が大きすぎて「いっぺんに全てやる」ということが事実上不可能。
《問題点2》しかし一方で、HTML同士の複雑な依存関係があるため、部分的に少しずつ進めていくことも不可能。
《問題点3》UTF-8化するには、文字コードの変換だけでなく、HTML自体も一部修正が必要。
特に《問題点1》と《問題点2》が激しく矛盾しており、方針決定の時点ですでに困難を極めた。
方針の決定
私は、HTML6万個、製作部の関係者300人以上、という規模を鑑みて、《問題点1》は本当に無理だと思ったので、《問題点2》をなんとか解消できないか考えた。
EUC-JPとUTF-8という文字コード自体に注目してみると、この2つにはもう一つの有名な日本語文字コードであるShift_JISには無い特徴がある。それは、ASCII(半角英数字)との区別が容易ということである。どちらも7ビットのASCII(0x00~0x7F)と被らない範囲のバイトを使って多バイト文字を構成しているからだ。
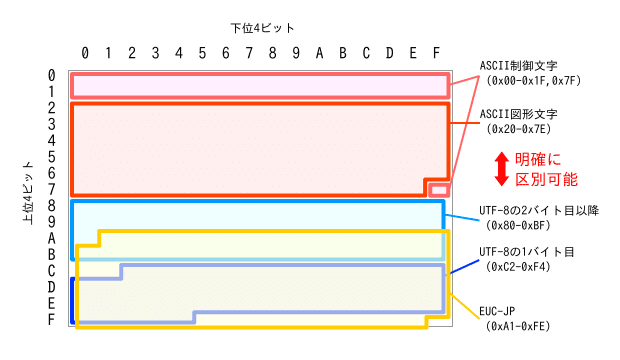
さらに、HTMLという文書は、通常「半角英数字によるタグ」と「タグとタグの間の日本語」が交互に現れるものと考えられる。静的ページ群で使われているSSIのインクルードは、タグとタグの間のキリの良い部分で分割されていることが大半なので、仮にUTF-8のHTMLがEUC-JPのHTMLをインクルードして文字コードが混在したとしても、「EUC-JPの日本語」と「UTF-8の日本語」が隣り合う可能性はほぼ無く、「半角英数字によるタグ」「EUC-JPの日本語」「UTF-8の日本語」の3つは明確に判別可能と考えた。
実際には、特に文字数が非常に少ない場合において、EUC-JPとUTF-8のどちらとも解釈できてしまうバイトの組合せが存在するが、そのような組合せでできる文字は記号付きのアルファベットや第3・第4水準漢字など、通常の日本語のコンテンツでは使われない文字種ばかりなので、事前に調査してホワイトリストを作り、ごく一部の文字に注意しさえすれば、問題になる可能性は極めて低い。
このように、EUC-JPとUTF-8が混在したHTMLから「EUC-JPの日本語」だけを正確に判別して、サーバー上でリアルタイムにUTF-8に変換するしくみを構築できれば、文字コードの混在が可能となるため《問題点2》が解消し、ディレクトリ単位で少しずつUTF-8化を進めていく【アイデアA】が実行できると考えた。オリジナルの変換システムを作れば、《問題点3》で懸念されていたその他の必要な変換箇所も同時に対応できる。
私は、このような変換システムが可能であることを関係者に説明し、ついにこの方針が採用された。
変換システムの構築
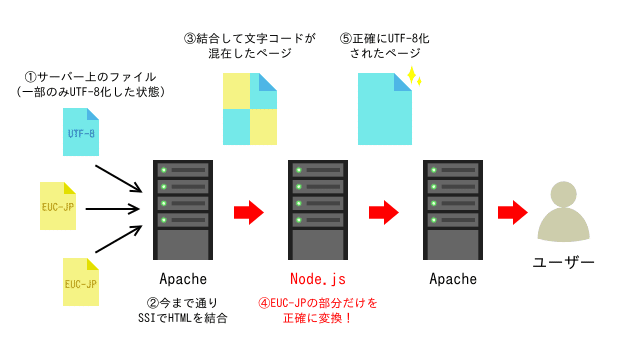
オリジナルの変換システムを構築するにあたって、まずインフラ部の助けを借りてサーバーの構成を変えた。長年Apacheだけという単純な構成だったものに対して初めての変更となる。変換システムはNode.jsでプロキシサーバーとして構築することにし、リクエストを受け付ける外向けのApache、変換システムのNode.jsサーバー、今まで通りSSIでHTMLを組み立てるApache、というNode.jsを2つのApacheで挟む3段構成になった。
Node.jsのプロキシサーバーは私が実装した。レスポンスのバイト列を直接読み取り、「EUC-JPとUTF-8が隣り合うことはない」という重要な前提に基づいてASCIIに挟まれたEUC-JPと推定されるバイト列だけを抽出し、UTF-8のバイト列に変換するようにした(全てをただ無条件に変換するだけの【アイデアB】との決定的な違いはこの部分である)。
他に、必要なHTMLの変換なども独自の実装をした。HTMLのタグだけでなく、自社のAPIに渡す文字コード指定のパラメーターを置換したりといった細かなことも自動で行なうようにした。サーバーの性能も求められたため、処理が重たくならないよう、主に正規表現によるシンプルな文字列置換で実装した。
当然、HTTPヘッダも変換が必要である。Content-Typeの文字コードだけでなく、UTF-8化によってレスポンスのサイズが変わるため、Content-Lengthも修正が必要であった。
長い道のり
変換システムは無事に必要な機能の実装が完了し、機能テストと負荷テストを経て本番環境に投入された。心配されていた変換によるオーバーヘッドもほとんど無く、許容範囲内であった。
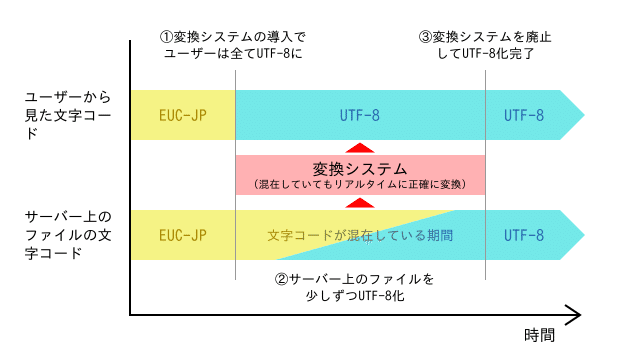
さて、これでユーザーから見ると、ある日突然、静的ページ群の全ての文字コードが一気にUTF-8に変わったことになる(図4の①)。この変化に気づいたユーザーはおそらくほとんどいなかっただろう。私は、「一晩で線路の高架化切り替え工事を成し遂げた鉄道会社」のような気分だった。とにかく、これで明日いきなりChromeがEUC-JPのサポートを終了したとしても、もう大丈夫だ。
静的ページ群の歴史上、非常に大きな一歩となったが、サーバー上のファイルはまだ全てEUC-JPのままである。変換システムにより、サーバー上では文字コードの混在が許される環境になったため、これからサーバー上のファイルを少しずつUTF-8化していき、最終的に「変換システムが何も変換してない」状態になればゴールとなる。
しかし、ここから先の道のりは険しかった。製作部は膨大な人数の担当者がおり、皆日々のコンテンツ製作で非常に多忙であったため、アプリ部の私一人だけで製作部全体の変換作業の指揮を執るのは困難であった。そこで、製作部内をまとめる専任のプロジェクトマネージャーをアサインしてもらい、以下の方法で変換を進めることで合意した(実際には、相手の多さと私の交渉力不足もあって、変換システム導入からこの合意に至るまでほとんど進捗が無いまま1年以上が経ってしまっていた)。
製作部側で変換作業をするのではなく、アプリ部(私)側にて一定のディレクトリ単位でまとめて変換する。
変換のスケジュールや範囲は、プロジェクトマネージャーが製作部と調整する。
進捗状況が一目で分かり、さらに未完了のファイルもワンボタンで変換できるツールを、アプリ部(私)が製作部に提供する。
プロジェクトマネージャーとスケジュールを相談して、6ヶ月で6万個のHTMLを変換することになった。1ヶ月に1万個、毎週数千個ずつ変換していかないといけないペースである。そこで、毎週木曜日を「変換する日」と決めて、スケジュールの合うディレクトリから順に変換していくことにした(図4の②)。
数千個のファイルの変換は、当然プログラムが行なうのだが、それでも毎回数十分から場合によっては数時間かかった。その間、製作部には製作を一時停止してもらう必要があり、毎日切れ目なくコンテンツをリリースしている製作部にとっては、この時間の確保が最も難しいものであった。リリース頻度が低いディレクトリは比較的早期に変換が完了したが、リリース頻度が高いディレクトリはこの時間がなかなか確保できず、終盤まで残ってしまった。こうした「大物」のスケジュール調整がなかなか大変だったが、プロジェクトマネージャーの尽力もあり、6万個のうち99.6%のファイルが予定の6ヶ月間で変換完了した。
完了宣言へ
ここまで来れば、変換システムはもはやほとんど何も変換せず、右から左へただ受け流しているだけの状態(図4の③)で、ゴールは目前である。実際、導入当初は、膨大な変換のログが出力されていたものが、ほとんど何も出力されなくなっているのを見て私は感動するものがあった。
期限に間に合わなかった残りのわずかなファイルも、その後の数週間で全て完了し、これで変換システムは用済みになると思われた。
しかし、この時点で変換システムは「誤ってEUC-JPでリリースしてしまっても自動的に直してくれるもの」という安心感を与えるお守りのような存在になっていたため、「そのまま残しておけばいいのでは」という意見が多く出るようになっていた。実際、変換作業が完了した次に直面した問題は、せっかく変換したファイルを製作部が誤ってEUC-JPに戻してしまうという「先祖返り」問題だった。
「古いファイルをコピペしてきた」「以前の製作手順を更新せずそのまま実行した」などの理由により、先祖返り問題は頻発した。その度に変換システムは「防衛ライン」となって、文字化けのトラブルが発生するのを防いでいた。とはいえ、本来の大きな役割が無くなったにもかかわらず3段構成のサーバーをずっと運用し続けるのはコストがかかるし、プロジェクトの最終ゴールとしてもやはり変換システムは廃止する方が望ましいと考えられた。
そこで、変換システムの廃止による不安を払拭するため、文字コードにまつわるミスが無いか静的ページ群全体を常に監視するオリジナルのシステムを代わりに実装して導入した。この監視システムは、ブラウザ上でHTMLの問題箇所を具体的に表示する機能を備え、さらに対応方法のドキュメントも完備したため、ミスがあれば誰でもすぐに気づいて修正することが可能となった。これで、ついに変換システムは役割を終えて機能停止することになった。
プロジェクトが始まってから、変換システム導入まで9ヶ月、製作部との合意まで1年3ヶ月、サーバー上のファイル6万個のUTF-8化作業に6ヶ月、変換システム停止まで3ヶ月かかり、ここまで合計2年半以上が経っていた。
振り返って
以前まで、静的ページ群の運用現場では「よく分からないから全部EUC-JPで」という感じで、文字コードの話題を深掘りするのは禁忌だった。それが今回のプロジェクトにより、「この部分は文字コード指定を省略できる」「ここの文字コードを誤るとこのような現象が起きてしまう」「ここに文字コードが指定されている理由は○○である」…という具合に、文字コードに関する様々な理解が進んで、あらゆる物事がクリアになった。
さらに、6万個のファイル全てを対象にしたことで、各ディレクトリの担当者が明確になったり、担当者不明のディレクトリがあぶり出されたり、不要なファイルが削除されないまま残されていることが発見されたり、といった副次的なメリットも多数生まれることとなった。これらも、今まで「規模が大きいから分からない」と目を背けていたせいで曖昧になっていたものである。
「長年変えていないものはよく分からないのでそのままにする」という「触らぬ神に祟りなし」的な思想は開発現場にありがちであるが、私はそういった「触ることすらできない管理不能なもの」こそが異常であり祟りの原因だと思っている。常に余計なコストがかかり、改善できるはずのものもできず、膨大な「見えない機会損失」が発生してしまうのだ。そういう問題点を「見て見ぬふり」するのではなく、ちゃんと向き合ってこそ、将来起きるトラブルを未然に防げるのだと思う。
静的ページ群はとにかく古くて規模が大きく、管理がなかなか隅々まで行き届いていないため、まだまだ問題点は多い。文字コードの問題は氷山の一角にすぎないのだ。長年変わらなかったものであっても、問題であればしっかりと向き合い、「触れぬ神」は「触れる普通のシステム」に変えていかなければならないと、このプロジェクトを通して考えさせられた。
(長文をお読みいただき、ありがとうございました。)
この記事が気に入ったらサポートをしてみませんか?