はじめに
突然ですが、私(たち)は大阪生まれ、大阪育ちの純粋な大阪人です。
現在は仕事のため東京に在住していますが、大阪の魂を捨てたわけではありません。
先日不意に興味深い論文を見つけました。
エセ大阪弁の音声学的特徴
共通語話者が大阪弁話者に親しみを込めて大阪弁っぽく話したとしても、そのエセ大阪弁に対する大阪弁話者の拒否感、抵抗感、嫌悪感は根強い。共通語や東京弁は認めても、エセ大阪弁だけは許さないという気概すら感じる。
草である。
流石にそのような拒否感や嫌悪感を露わにするほどではありませんが、少なくとも大阪人であれば聞き慣れない関西弁を耳にした時、
「ん?今のエセっぽいな?」

と感じることは少なからずあるかと思います。
決して嫌悪感を抱いているわけではないですが、この論文にあるようにアクセントの違いには敏感であるとは自覚していますし、大多数の大阪人の方々も同じくだと思います。
(例えば、関西以外の方が話す「ユニバ」(ユニバーサルスタジオジャパンの略)って明らかにアクセント違いませんか?)
本論文では共通語話者と関西弁話者の話す言葉の音調と基本周波数曲線を分析して、いわゆるエセと感じられるアクセントを考察されています。
論文では「大阪弁」と称しておりますが、本記事においては「関西弁」と統一いたします。
ひとえに関西弁と言っても、細かく分類されており、それぞれに微妙に違いはありますが、世間一般的に浸透している言葉として本記事では便宜上、「関西弁」と総称させていただきます。
では、このアクセントの違いと言うものを機械学習させ、AIに判断してもらうと非常に面白いのではないかと考えました。
そこで、Pythonによる機械学習を用いて「エセ関西弁警察」を開発いたしました。
「わたしに任せとき〜。ええ加減な関西弁話しとったらえらい目あうで〜。飴ちゃんいらんか?」(CV:大阪のおかん)

音声認識において、「どういった言葉を発したか」と言うものはAmazon AlexaやGoogle Assistant、Siriなど現代においては素晴らしい技術・製品が存在していますが、方言の違いを認識するソフトってあまり目にしませんよね。(需要が無いだけかも知れませんが。)
本記事では「エセ関西弁警察」の詳細とともに、TensorFlowを用いた音声認識、特にアクセントの違いを学習させることは可能なのかという観点を踏まえて得た知見を共有させていただきます。
ただし、そもそもこれまで機械学習を実装したこともない上に、諸事情で製作期間が約2週間と限られていたこともありますので、温かい目で見ていただけますと幸いです。
なお、本アプリはTensorFlow公式のチュートリアルを踏襲して作成しております。
「エセ関西弁警察」の開発のために多くの方の音声データを収集いたしました。今回の開発のため収集したデータは個人を特定しないように取り扱い、開発後速やかに破棄させていただきました。
共同執筆者: @39yatabis , @Miyayan , サカモトさん
目次
謝辞
本開発にあたって、社内外問わず多くの方に音声データ提供のご協力を得ました。
皆様のご協力なしではなし得ない開発となりました。
この場をお借りして御礼申し上げます。
この度はご協力いただき誠にありがとうございます。
エセ関西弁警察
実行環境
- Python - ver.3.9
- TensorFlow - ver.2.8.2
README
エセ関西弁警察はブラウザ上で実行できます。
録音ボタンを押下し、 「何でやねん」 と吹き込み、「判定する」ボタン押下により、あなたの「なんでやねん」が関西弁かエセ関西弁 かを判定します。

前処理
音声データはモノラルのwav形式で扱いました。
サンプリングレートは48kHzとし、長さは最大2秒としました。
データの先頭に無音部分があると、その無音部分の長さの違いが学習に悪影響を与えていたので、カットしておきます。
# 平均的に考慮して、静寂を2000以下に設定。あまりに静かなデータはすべてカットされる可能性に留意
thres = 2000
amp = np.abs(data)
b = amp > thres
# 声の認知開始ポイント
start_voice = b.tolist().index(True)
# 認知後の配列を取得
voice = data[start_voice:]
また、データの Augmentation によって教師データを増やします。
外部ライブラリのAudiomentationsを使用します。
from audiomentations import (
Compose,
AddGaussianNoise,
AddGaussianSNR,
AirAbsorption,
TimeStretch,
PitchShift
)
Augmentationの設定は下記の通りです。
augment = Compose([
AddGaussianNoise(p=0.4),
AddGaussianSNR(p=0.7),
AirAbsorption(p=0.6),
TimeStretch(p=0.4),
PitchShift(min_semitones=-2, max_semitones=2, p=0.7),
])
今回は1つの音声データを50倍にAugmentationしました。
n = 50
for j in range(n):
augmented = augment(samples=data, sample_rate=sample_rate)
print(" ", j, augmented, len(augmented))
with wave.open(os.path.join(augmented_dir, f"augmented{i * n + j:0>4}.wav"), "w") as w:
w.setnchannels(channel)
w.setsampwidth(sample_width)
w.setframerate(sample_rate)
w.setnframes(frames)
w.writeframes(augmented.astype("int16").tobytes())
データによって長さが違うのでゼロパディングして揃えておきます。
これらの音声データをスペクトログラムに変換したものを、CNN(畳み込みニューラルネットワーク)で学習させます。
def get_spectrogram(waveform):
input_len = 48000
waveform = waveform[:input_len]
zero_padding = tf.zeros(
[48000] - tf.shape(waveform),
dtype=tf.float32)
waveform = tf.cast(waveform, dtype=tf.float32)
equal_length = tf.concat([waveform, zero_padding], 0)
spectrogram = tf.signal.stft(
equal_length, frame_length=255, frame_step=128)
spectrogram = tf.abs(spectrogram)
spectrogram = spectrogram[..., tf.newaxis]
return spectrogram
スペクトログラムは、平均と標準偏差に基づいて各ピクセルを正規化しておきます。
その他の前処理については チュートリアルと同じにしました。
norm_layer = layers.Normalization()
norm_layer.adapt(data=spectrogram_ds.map(map_func=lambda spec, label: spec))
model = models.Sequential([
layers.Input(shape=input_shape),
layers.Resizing(32, 32),
norm_layer,
layers.Conv2D(32, 3, activation='relu'),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(num_labels),
])
学習
学習には単純なCNNを使いました。
チュートリアルと同じく、バッチサイズ 64、エポック数は 10 としました。
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],
)
EPOCHS = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=EPOCHS,
callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)
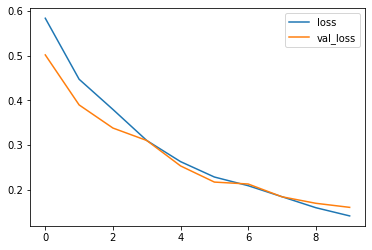
評価
テストセットでモデルを実行し、パフォーマンスを確認します。
混同行列は下図のようになりました。
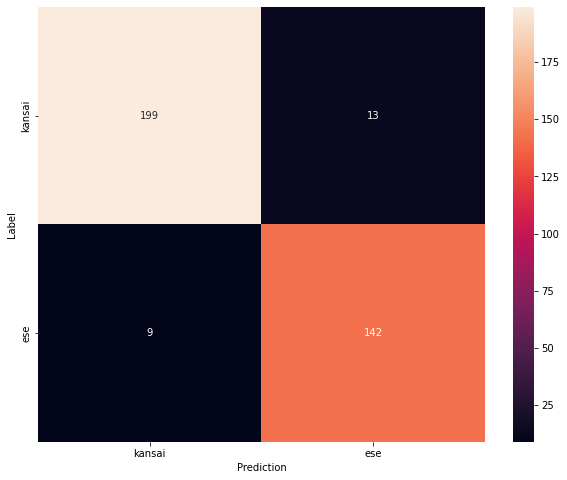
正答率は 94% となりました。
課題
- 今回は2週間と言う限られた時間の中で、本業の生産性をなるべく落とさずに取り組んだこともあり、学習のために十分なデータを収集できなかった。(今回ご協力いただいた方には本当に本当に感謝しております。)
今後
- もっとデータを集めて、より精度の高いソフトに仕上げたい。
- 「なんでやねん」以外の関西弁も認識させたい。
- 関西弁は大阪弁、河内弁、泉州弁、滋賀弁、京都弁、播州弁、三重弁、淡路弁などなど意外と細かく分類されるので、それらの聞き分けもできると面白そう。(そもそもこれらにアクセントの違いがあるのか・・・)
参考文献
おわりに
ここまでお読みいただきありがとうございました。
最後に「エセ関西弁警察」に自分の声を改めて読み込ませてみます。
冒頭でも述べましたが、私は大阪生まれ大阪育ち、東京在住歴1年ですが関西弁は捨ててません。
当然、ハイスコアを叩き出し関西弁と認識してくれるはずです。
〜結果〜
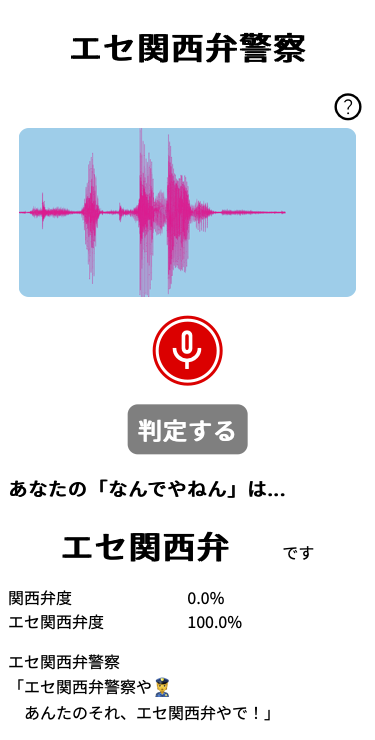
なんでやねん