




こんにちは。ZOZOテクノロジーズの廣瀬です。
弊社ではサービスの一部にSQL Serverを使用しています。先日、「普段は数10ミリ秒で実行完了するクエリが、たまに5秒間実行され続けて最終的にタイムアウトするので調査して欲しい」という依頼を受けました。調査方法を整理して最終的に原因の特定とタイムアウト発生の防止まで実現できたので、一連の流れとハマった点、今回のようなケースでの調査に使える汎用的な調査手法をご紹介したいと思います。
SQL Server以外のRDBMSをお使いの方にも、「SQL Serverではこんな情報がとれるのか。MySQLだったら〇〇でとれる情報だな」というように比較しながら読んでいただけると嬉しいです。
初めに浮かんだ仮説
依頼を受けて最初に思い浮かんだのは、「ブロッキングが起きているのでは」という仮説でした。そこで、拡張イベントを使ってブロッキングを検出できる状態にしました。取得するように設定したイベントは以下の4つです。
- blocked process report(ブロッキングが一定時間続いた場合に発生)
- attention(アプリから受け取った途中終了の要求に応じてクエリを停止したときに発生)
- sql_batch_completed(クエリの実行完了時に発生)
- RPC_completed(クエリの実行完了時に発生)
sql_batch_completedとRPC_completedの違いについては、sql_batch_completedはクエリがTransact-SQLバッチとして実行されたときに発生します。一方で、RPC_completedはクエリがリモート プロシージャ呼び出しとして実行されたときに発生します。blocked process reportについてはこちらに詳しく解説されています。今回はプログラム側で設定するタイムアウト値が5秒であるため、blocked process thresholdには3秒を設定しました。また、sql_batch_completedとRPC_completedについてはResult=Abort(異常終了)でフィルタを設定しました。Result=Abortでフィルタしたsql_batch_completedとRPC_completedイベントが起きた同一時間帯でblocked process reportイベントが発生していれば、ブロッキングが原因でタイムアウトした可能性があります。また、blocked process reportイベントの中身を見ることで、Result=Abortで終了したクエリがブロッキングされていたかどうかを特定できます。
調査した結果、Result=Abortでフィルタしたsql_batch_completedとRPC_completedイベントが起きた同一時間帯で、blocked process reportイベントは起きていませんでした。したがって、今回のタイムアウトの原因はブロッキングではないことが分かりました。
次の調査に移るための情報取得
ブロッキングではないことが分かったので、次の仮説を立てようと、考えられる原因について考えました。しかし、「いつもは高速なクエリが突然遅くなる事象」の原因としては考えられるパターンが複数存在します。そのため、次のステップとして、いきなり仮説を立てるのではなく、次の調査に移るためにどういった情報を取得すれば良いかを考えました。
タイムアウトしたクエリが5秒間実行され続けるとき、何らかの「待ち状態」になっていると考えられます。ブロッキングは数ある待ち状態の一つでしかなく、どういった待ち状態であったかを後追いできる仕組みを作ることで調査に必要な情報が取得できるのではと考えました。
そこで、実行中のリクエストを取得できるDMVである、dm_exec_requestsの実行結果を1秒ごとにテーブルにダンプする仕組みを作りました。このテーブルには、実行中クエリの現在の待ち状態と前回の待ち状態が「wait_type」、「last_wait_type」としてそれぞれ格納されています。そのため、1秒ごとにこの情報をダンプしておくことで、タイムアウトにいたるまでの待ち状態の遷移を後から確認することができます。
まず、ダンプするためのテーブルを以下のクエリで作成します。
select getdate() ,a.session_id ,a.request_id ,a.start_time ,a.status ,a.command ,a.database_id ,a.blocking_session_id ,a.wait_type ,a.wait_time ,a.last_wait_type ,a.wait_resource ,a.open_transaction_count ,a.open_resultset_count ,a.transaction_id ,a.cpu_time ,a.total_elapsed_time ,a.scheduler_id ,a.reads ,a.writes ,a.logical_reads ,a.text_size ,a.transaction_isolation_level ,a.lock_timeout ,a.deadlock_priority ,a.row_count ,a.prev_error ,a.nest_level ,a.granted_query_memory ,a.executing_managed_code ,b.login_time ,b.host_name ,b.program_name ,b.client_interface_name ,b.login_name ,b.memory_usage ,b.total_scheduled_time ,b.last_request_start_time ,b.last_request_end_time into dm_exec_requests_dump from sys.dm_exec_requests a with(nolock) join sys.dm_exec_sessions b with(nolock) on a.session_id = b.session_id where 1=1
次に、以下のクエリをジョブなどで実行します。dm_exec_requestsをSELECTした結果を、無限ループで1秒ごとにテーブルにINSERTしていきます。
set nocount on while (1=1) begin insert into dm_exec_requests_dump select getdate() ,a.session_id ,a.request_id ,a.start_time ,a.status ,a.command ,a.database_id ,a.blocking_session_id ,a.wait_type ,a.wait_time ,a.last_wait_type ,a.wait_resource ,a.open_transaction_count ,a.open_resultset_count ,a.transaction_id ,a.cpu_time ,a.total_elapsed_time ,a.scheduler_id ,a.reads ,a.writes ,a.logical_reads ,a.text_size ,a.transaction_isolation_level ,a.lock_timeout ,a.deadlock_priority ,a.row_count ,a.prev_error ,a.nest_level ,a.granted_query_memory ,a.executing_managed_code ,b.login_time ,b.host_name ,b.program_name ,b.client_interface_name ,b.login_name ,b.memory_usage ,b.total_scheduled_time ,b.last_request_start_time ,b.last_request_end_time from sys.dm_exec_requests a with(nolock) join sys.dm_exec_sessions b with(nolock) on a.session_id = b.session_id where a.session_id > 50 and datediff(s, a.start_time, GETDATE()) >= 1 waitfor delay '00:00:01' end
あとは、タイムアウトしたクエリのセッションIDとタイムアウト時間帯でテーブルをフィルタします。タイムアウトしたクエリのセッションIDは、Result=Abortでフィルタしたsql_batch_completedかRPC_completedイベントを確認することで取得できます。
select top 100 datediff(ms, start_time, collect_date) as duration_ms ,* from dm_exec_requests_dump with (nolock) where collect_date between '2020-04-10 11:59' and '2020-04-10 12:10' and session_id in (559) order by collect_date

タイムアウトしたクエリは上図のように、常にPAGEIOLATCH_SHで待っている状態でした。ここで、PAGEIOLATCH_SHという待ち状態について説明します。SQL Serverでは、必ずメモリからデータを読むのですが、以下のいずれかの流れをとります。
- メモリに欲しいデータがある場合:メモリから直接読む
- メモリに欲しいデータがない場合:ディスクからメモリに読み、その後メモリから直接読む
PAGEIOLATCH_SHは「ディスクからメモリに読む」ときに発生する待ちです。そのため、物理読み取りによる待ち時間が起因して普段よりもクエリ実行に時間がかかっている状況だったといえます。ブロッキングのように他のリクエストと競合しているわけではありませんでした。
実行プランが突発的におかしくなり、通常よりも大量のIOを発生させている可能性を考え、タイムアウトしたクエリの実行プランのプロパティを確認してみました。その結果、「十分な数のプランが見つかりました」という理由でクエリの最適化が途中で終わっていました。最適化が途中終了する程度にシンプルなクエリなので、実行プランが突発的におかしくなるわけでもなさそうでした。

別の可能性として、バッチ処理等で大量にデータを読み取る処理が発生したタイミングで、メモリからデータがキャッシュアウトされたことで通常時よりも多くのデータのディスク読み取りが発生する状況を考えました。そこで、[SET STATISTICS IO ON]をつけてタイムアウトしたクエリ実行し、各テーブルの読み取り状況を確認しました。

多少物理IOは発生していますが、通常時は10ミリ秒程度で実行完了します。そのため、仮にキャッシュアウトされたことで全データが物理読み取りになったとしても、5秒もかかるものなのだろうかと疑問に思いました。
以上を踏まえると、キャッシュアウトによる物理ディスク読み取り量が増えたことが原因というよりは、別のクエリが大量のデータを読み取ることで急激な物理ディスク負荷がかかり、ディスクキューの数値が上昇し、1IOあたりの物理読み取りの時間が伸びているのでは、と考えました。

タイムアウトしたときのdm_exec_requestsのダンプ結果を再掲します。上図から、wait_timeが毎回数10ミリ秒になっていることが分かります。これは普段の傾向なのか、タイムアウト時の傾向なのか判断するために、今までの累計値(≒通常時)から、物理ディスク読み取り時の平均待ち時間を確認しました。
select * ,wait_time_ms / waiting_tasks_count as avg_wait_time_ms from sys.dm_os_wait_stats where wait_type like '%pageiolatch%' and waiting_tasks_count > 0

PAGEIOLATCH_SHの平均待ち時間(avg_wait_time_ms)は2ミリ秒でした。このことから、タイムアウトが発生するタイミングでは、1IOあたりの待ち時間が通常時よりも大幅に長くなっていることが分かりました。ディスクまわりのメトリクスを採取することで、このあたりの情報をより詳細に確認できます。したがって、次のステップとしてperfmonで採取したメトリクスを解析してみました。
perfmonで取得したメトリクス解析
20:05:24ごろタイムアウトしたクエリがあったので、その時間帯付近に注目して各メトリクスを確認しました。

メモリ内のデータ保持予測期間を示す「SQL Server:Buffer Manager\Page life expectancy」の値が定期的に大幅に減少しています。これはデータのキャッシュアウトが定期的に発生していると読み取ることができますが、ある程度規則性があり、タイムアウト発生時だけ特異な形状というわけではありませんでした。

「PAGEIOLATCH_SH」待ちがエラー発生の時間帯で突出して高いことが分かります。タイムアウトしていないクエリも、一時的に実行時間が伸びている可能性がありそうです。
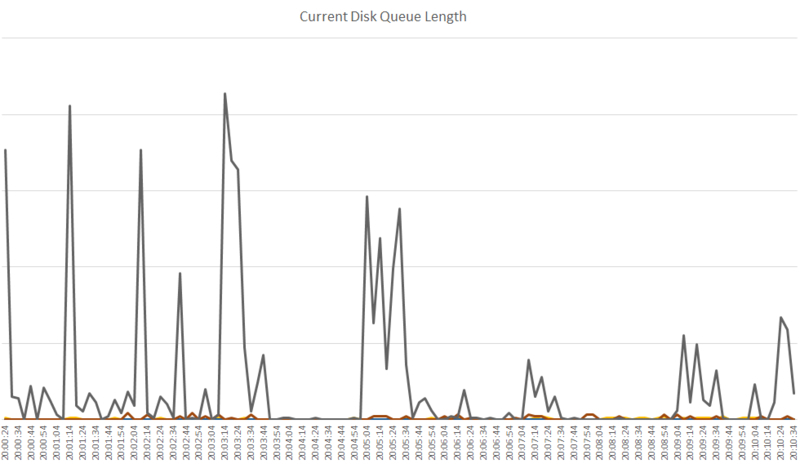
ディスクキューも確認しました。データファイルが格納されているドライブのディスクキューが突出して高くなっていました。タイムアウト時間帯以外もスパイクはみられました。
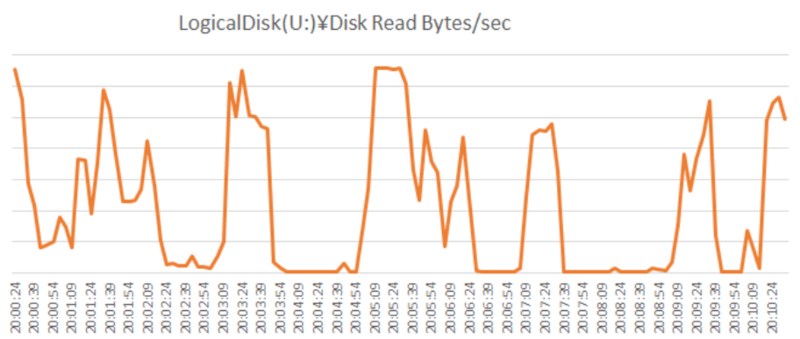
秒間のディスク読み取り量についても、データファイルが格納されているドライブが突出して高く、タイムアウトが起きた時間帯では高い値のまま一定期間推移しているように見受けられます。この値がDBサーバーの物理ディスク性能の上限値である可能性が高そうです。
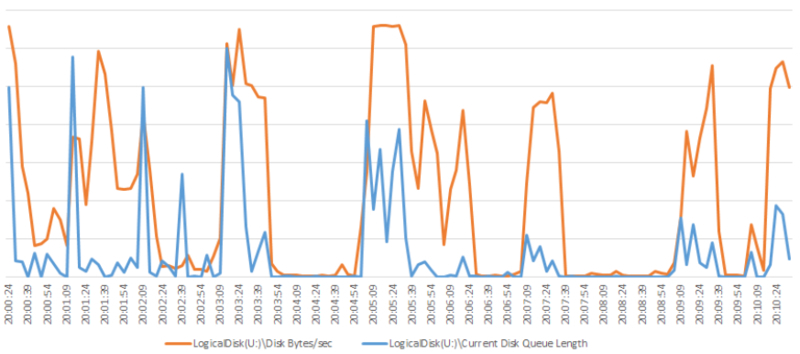
物理読み取りサイズと、ディスクキューの発生状況の関係を見るため重ねてみると、両者には相関関係がありそうです。

物理読み取りサイズとPage IO Latch Waitsにも関係があるようでした。「大量にディスク読み取りを行うプロセスが1つ以上存在し、ディスク性能上限に達するほどの読み取りを行っている状況下で、物理ディスクにアクセスが必要なクエリが実行されることでPage IO Latch Waitsがスパイクする」と解釈しました。
perfmonのメトリクス解析結果まとめ
定期的に物理ディスク読み取り性能の上限に達しており、そのタイミングで物理読み取りが必要なクエリが出てくると「Page IO Latch Waits」が発生するようです。この時点で、「普段は数10ミリ秒で実行完了するクエリが、たまに5秒間実行され続けて最終的にタイムアウトする」原因としては、そのクエリ自身にはなんの落ち度もないことが分かりました。かわりに、別の何らかのクエリがディスク性能の上限に達するほどの大量の物理読み取りを行っているため、他のクエリがわずかな物理読み取りを行う際でも通常時よりかなり時間がかかってしまい、場合によってはタイムアウトに達することもある、という状況でした。
最後に、実際に大量の物理読み取りを発生させているクエリを特定すれば、実際に対策を実施できる可能性があります。
大量の物理読み取りをおこなっているクエリを特定する
タイムアウトが発生した時間帯における物理読み取り量が多い順にsession_idを並び替えるクエリを以下の通り作成しました。
declare @start_time datetime, @end_time datetime set @start_time = '2020-04-14 20:05:10' set @end_time = '2020-04-14 20:05:40' declare @total_reads bigint set nocount on --session_idごとの物理読み取りページ数推移 select (a.reads - b.reads) as reads_diff ,a.* from ( select row_number() over(partition by session_id, start_time order by collect_date) as rownum ,* from dm_exec_requests_dump with(nolock) where collect_date between @start_time and @end_time ) a join ( select row_number() over(partition by session_id, start_time order by collect_date) as rownum ,* from dm_exec_requests_dump with(nolock) where collect_date between @start_time and @end_time ) b on a.session_id = b.session_id and a.start_time = b.start_time and a.rownum-1 = b.rownum where (a.reads - b.reads) > 0 order by a.session_id, a.collect_date --総物理読み取り数を取得 select @total_reads = sum((a.reads - b.reads)) from ( select row_number() over(partition by session_id, start_time order by collect_date) as rownum ,* from dm_exec_requests_dump with(nolock) where collect_date between @start_time and @end_time ) a join ( select row_number() over(partition by session_id, start_time order by collect_date) as rownum ,* from dm_exec_requests_dump with(nolock) where collect_date between @start_time and @end_time ) b on a.session_id = b.session_id and a.start_time = b.start_time and a.rownum-1 = b.rownum where (a.reads - b.reads) > 0 --総論理読み取り数が多い順にリクエストを並べる select a.session_id, a.start_time, sum((a.reads - b.reads)) as reads_diff, sum((a.reads - b.reads)) * 100 / @total_reads as percentage from ( select row_number() over(partition by session_id, start_time order by collect_date) as rownum ,* from dm_exec_requests_dump with(nolock) where collect_date between @start_time and @end_time ) a join ( select row_number() over(partition by session_id, start_time order by collect_date) as rownum ,* from dm_exec_requests_dump with(nolock) where collect_date between @start_time and @end_time ) b on a.session_id = b.session_id and a.start_time = b.start_time and a.rownum-1 = b.rownum where (a.reads - b.reads) > 0 group by a.session_id, a.start_time order by sum((a.reads - b.reads)) desc
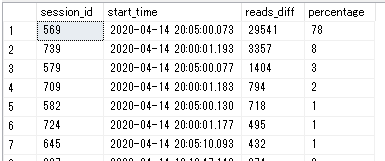
このクエリの実行結果です。該当の時間帯で最も総物理読み取りサイズが大きいセッションでも29541ページ(約230MB)しか読み取っていないという結果になりました。この程度のディスク負荷では、性能上限には達しない印象で、作成したクエリが間違っていそうです。そこで、次に「タイムアウト発生直前の20:05ごろに開始したクエリの中で、総物理読み取り数が多い順」で並び替えてみたところ、以下のクエリをみつけました。
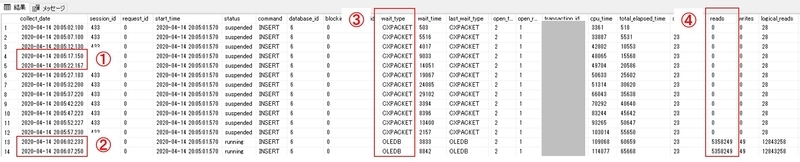
①と④に着目すると、クエリがタイムアウトした時間帯(2020/04/14 20:05:24ごろ)では、物理読み取りページ数(reads)がカウントアップされておらず、ずっと0になっていました。そのため、最初に作成したクエリにはヒットしていませんでした。そして、タイムアウトとは時間的には関係がない時間帯(図中②)において、いきなり「reaeds」が5358249(約41GB)まで跳ね上がっていました。
今回のDBサーバーのディスク性能を考慮すると、数秒で41GBを読み取ることは不可能です。したがって、「readsは常に読み取ったサイズをカウントアップするわけではなく、あるタイミングで一気に累積読み取り数を計上することがある」といえます。この仕様を知らなかったのでクエリの書き方を間違い、結果として根本原因のクエリを見つけることができない状態になっていました。readsが計上されない条件ですが、少なくともlast_wait_type=CXPACKET(③)である場合、つまり並列処理している間はreadsに限らず、writesなど複数項目がカウントアップされないようです。
以上の調査を踏まえ、以下のクエリで大量の物理読み取りを行っているクエリを特定することができました。
declare @start_time datetime, @end_time datetime set @start_time = '2020-04-14 20:04' set @end_time = '2020-04-14 20:06' declare @total_reads bigint set nocount on --session_idごとの物理読み取りページ数推移 select (a.reads - b.reads) as reads_diff ,a.* from ( select row_number() over(partition by session_id, start_time order by collect_date) as rownum ,* from dm_exec_requests_dump with(nolock) where start_time between @start_time and @end_time ) a join ( select row_number() over(partition by session_id, start_time order by collect_date) as rownum ,* from dm_exec_requests_dump with(nolock) where start_time between @start_time and @end_time ) b on a.session_id = b.session_id and a.start_time = b.start_time and a.rownum-1 = b.rownum where (a.reads - b.reads) > 0 order by a.session_id, a.collect_date --総物理読み取り数を取得 select @total_reads = sum((a.reads - b.reads)) from ( select row_number() over(partition by session_id, start_time order by collect_date) as rownum ,* from dm_exec_requests_dump with(nolock) where start_time between @start_time and @end_time ) a join ( select row_number() over(partition by session_id, start_time order by collect_date) as rownum ,* from dm_exec_requests_dump with(nolock) where start_time between @start_time and @end_time ) b on a.session_id = b.session_id and a.start_time = b.start_time and a.rownum-1 = b.rownum where (a.reads - b.reads) > 0 --総論理読み取り数が多い順にリクエストを並べる select a.session_id, a.start_time, sum((a.reads - b.reads)) as reads_diff, sum((a.reads - b.reads)) * 100 / @total_reads as percentage from ( select row_number() over(partition by session_id, start_time order by collect_date) as rownum ,* from dm_exec_requests_dump with(nolock) where start_time between @start_time and @end_time ) a join ( select row_number() over(partition by session_id, start_time order by collect_date) as rownum ,* from dm_exec_requests_dump with(nolock) where start_time between @start_time and @end_time ) b on a.session_id = b.session_id and a.start_time = b.start_time and a.rownum-1 = b.rownum where (a.reads - b.reads) > 0 group by a.session_id, a.start_time order by sum((a.reads - b.reads)) desc
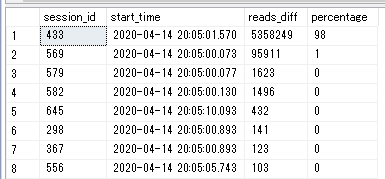
修正版のクエリの実行結果です。修正前は、「タイムアウト発生タイミングでreads=0だけどディスクに高負荷をかけているセッションが存在する場合がある」ということを考慮せずに作成したクエリでした。一方で、修正版ではそれを考慮したうえで作成しているため、こちらのクエリの方が信頼できる結果を得られています。
原因と解決方法まとめ
断続的なタイムアウトの原因
ディスク性能限界まで達するほどの物理読み取りが数秒~数10秒継続した状態において、物理読み取りが必要なクエリが実行されたとき、通常よりも物理読み取りに時間がかかり、タイムアウトに達することもある状況になっていました。
解決方法
理論的には、性能限界まで物理読み取りを発生させなければ大丈夫です。そのためには、大量の物理読み取りを行っているクエリを特定し、特定結果によって以下のAかBいずれかの場合に応じた対応をとれば良いはずです。
A:複数のクエリが同タイミングで実行されることで合算値として性能限界まで読み取る場合
各クエリをチューニングするか、定期的な周期で実行しているクエリがある場合は実行タイミングをずらす。
B:単一のクエリにより性能限界まで読み取る場合
物理読み取り削減という観点でのチューニング(圧縮・クエリチューニング・インデックス等)を実施する。
今回特定した結果はBに該当し、シンプルにインデックスを張ることで該当クエリのIOを劇的に削減できました。結果的にこのクエリ起因でのクエリタイムアウト発生を防ぐことができるようになりました。
クエリタイムアウト発生時の原因調査方法
今回紹介した調査手法を、以下の3ステップとしてまとめます。
- 現在実行中のクエリリストを取得できるDMVであるdm_exec_requestsのSELECT結果を定期的にダンプしておく
- タイムアウトが発生した場合に、該当のクエリがどういった待ち状態で遷移していたかを確認する
- 待ち状態の種類に応じてさらに調査していく
ステップ3については、待ち状態によって手順が多岐にわたりますが、ステップ1と2については調査の初期段階として汎用的に使っていただけると思います。
補足
今回調査したサーバーでは使えませんでしたが、SQL Server 2017以降ではクエリストアを使って各クエリの待ち事象を取得することができるようになっています。そのため、今回ご紹介した調査手法をクエリストアだけで完結させることができます。なお、クエリストア自体は2016から提供されていますが、待ち事象が取得できるようになったのは2017からです。
まとめ
調査依頼を受けたときに最初に思いついた原因はブロッキングでしたが、結果としてまったく違う原因でタイムアウトが起きていました。原因調査では、仮設を立てる前に可能な限り必要な情報を集めることが重要だと感じました。
ZOZOテクノロジーズでは、一緒にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!