How do you imagine a building? You consciously create each aspect, puzzling over it in stages.
Inception
型なし言語に馴染みはあるものの型付言語をいざ使ってみたらどういう気持ちで書いたらいいのかわからなかったと同僚から相談があり, それをきっかけにして社内の勉強会で以下の話をしました.
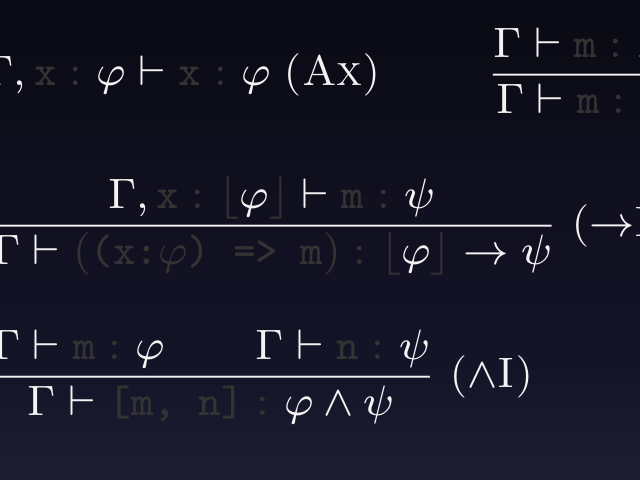
よく型なし vs. 型付の文脈では「型を書くのは面倒だ」「安全の方が大事だ」「でも面倒だ」「それは型推論を前提にしていないからだ」などの議論になりがちな気がしますが、これはあくまで「計算ありきの型」を考えているからで, 「型ありきの計算」だと全く見え方が違います. 「型はある種の仕様」とおもえば, 型ファーストであることと, 型なし言語でテスト駆動開発(TDD)するときに最初にテストを書くこととは, 同じなんだよなぁと思っていました. そして型ファーストが重要な理由をつきつめていくと, Curry-Howard同型対応があるからだなぁという結論に至ったので, それを言語化しました. せっかくなのでスライドを公開するとともに、口頭で補ったところも含めて丁寧に記事として書き起こしました。
TDDとの共通性からもわかる通り, 型なし言語を腐す話ではありません. 筆者も, 型付と型なしを混ぜる漸進的型付け(gradual typing)について, 型なし言語に型を導入するのではなく型付言語から型を取り除くアプローチで研究していた人間なので, 型のない言語に恨みはなく, メリットも十分に理解しています. 単に, 型付言語でばりばり書いていて何も困っていない人たちはこういう気持ちで書いています, という話です.
計算ファーストで考える型
「型ファースト」について考える前に, 「計算ファースト」で考えた場合に型をつけるとはどういうことなのか, 整理しておきましょう.
型がない場合
型がない場合, 意図とは違う誤った使い方を防げなかったり, 誤った使い方をしていても実行してみるまで誤りに気づけなったりします. 例を2つほど見てみましょう(例はJavaScriptで書いています).
let apply2 = (f, n) => f(f(n)) apply2(1, 3)
Uncaught TypeError: f is not a function
本来は関数を渡すべきところに関数以外のものを渡してしまった例です. こんな単純なミスはしないかもしれませんが, 呼び出し関係が複雑になってくれば「関数が渡ってくると思っていたら意外とそうでもなかった」となり, 関数でないものを「関数しか渡してはいけないところ」に渡してしまうかもしれません.
実行時エラーなのでapply2の関数本体がエラー発生箇所になってしまっている点は特筆すべきです. 悪いのは呼び出し側のはずですが, あたかもapply2の実装が悪いかのようなエラーメッセージになってしまっていますね.
let omega = (x) => x(x) omega(omega)
Uncaught RangeError: Maximum call stack size exceeded
この例はなんかめちゃくちゃですね. なんの役に立つのかよくわからないものがよくわからない使われ方をしています.
型がないとこういったものを書こうと思えば書けてしまいます. いい意味では自由になんでも書けますが, 自由には代償をともないます.
書いてよい式を型で制限する
計算ありきで考えたときの型の役割は「めちゃくちゃなことができないように制限をする」ことです. 先程の例の場合は型をつけると以下のようになります(例はTypeScriptで書いています).
let apply2 = <A>(f: (a: A) => A, n: A) => f(f(n)) apply2(1, 3)
Argument of type '1' is not assignable to parameter of type '(a: 3) => 3'
この例では重要なことが2つあります.
- エラーは実行時ではなくコンパイル時に出ている
apply2の関数本体ではなく呼び出し側のエラーになっている
let omega = <A, B>(x: (a: A) => B) => x(x)
Argument of type '(a: A) => B' is not assignable to parameter of type 'A'
今度はomegaの定義の時点でエラーになります. 「なんの役に立つのかよくわからないもの」のうち, 明らかに危険なものは型があればそもそも書けなくなる例です.
型検査
現代の処理系で, このような「型がつく」ことの検査をどのようにやっているか少し話しておきましょう. 型を検査するためには, あらかじめ言語仕様として型付け規則(typing rule)が定義されていて, それらの規則だけを使って「ある式にある型がつく」ことを(自動)証明する手続きを踏みます. 難しいことを言っていますね. ひとつずつ見ていきましょう.
まず型付け規則とはどういうものか. 実際のプログラミング言語のフルの仕様の型付け規則を見るのは非常にたいへんなので, 型理論の源流となっている単純型付ラムダ計算(以下STLC)の場合で見てみましょう(式の部分はTypeScriptの構文にしてあります).
STLCの型付け規則,
,
は, ラムダ計算の構文要素である変数(variable), 関数抽象(abstraction), 関数適用(application)にそれぞれ対応して定義されています. 正確を期すため, TypeScriptの構文での型を, 型の表記として一般的な形に変換する操作
も定義しています. これは単に
の形のTypeScriptの関数型をここでは
と読み替えたいだけで, あまり重要ではありません.
いくつか読み方の約束を書いておきます. は変数を表すためのメタ変数で, 任意の識別子が入ると思ってください.
,
は式を表すためのメタ変数で任意の式が入り,
,
は型を表すためのメタ変数で任意の型が入ります.
は型環境と言って, 基本的には変数と型の組を
の形で要素に持つ集合です. ただし,
と書かずに単に
と書き,
と書かずに単に
と書きます. また, 同じ変数を異なる型と組にして重複して含んではいけない(
のようにしてはいけない)こととします(つまり
は単なる組の集合ではなく, 変数から型への写像です).
は判断(judgment)と言い,
という仮定の下で
が成り立つという主張です(主張なのでまだこれだけでは本当に成り立つかどうかはわかりません). いまは型付け規則の話をしているので, これは型判断であり,
という環境(
で示した方法により各変数の型を割り当てたという仮定)の下で
に
という型がつくと主張しています.
それぞれの型付け規則は, 横線の上が前提で下が結論です. 前提が成り立つ場合に限って, 結論に書かれた判断が成り立つと思ってよいことを意味します. 前提が複数ある場合(の規則)は, 両方の前提が成り立つ場合に限り結論を導いてよいとします.
型検査は, このような型付け規則のみを用いての形の判断が成り立つと言えるか調べることです. もし結論を導くのに
や
を用いるとすると, これらの規則の前提にはまた
が登場するので, 前提が成り立つと言うために再び3つの規則のうちのいずれかを用いなければなりません. そうやって前提を成り立たせるための規則をどんどんつなげていくと(
で枝分かれが生じるため)木構造ができ上がります. 木構造の葉の部分がすべて
の規則で終わっていれば, もうそれ以上は規則を当てはめる必要がなくなり, 最終的な結論(木構造の根のところにある判断)が成り立つと言えます. このように規則をつないで結論を導くことを導出(derivation)と言います.
型検査: 型がつく例
例を見てみましょう. (f: (a: A) => A) => (n: A) => f(f(n))にの型がつくことを確認します.
いきなり完成した導出を見せてしまいましたが, どうやってこれが導かれるのか確認していきましょう.
まず, の式は全体が関数になっています. 3つの型付け規則はすべて結論の部分の形が違っていて, 結論が関数の形にマッチするのは
の規則のみなのでこれを使います. 式を
の結論にパターンマッチすると,
,
,
になります. 型の部分も同様に
を
にパターンマッチすると,
とわかります. これらの情報を用いると,
の前提部分は以下のようになるはずです.
前提が判断の形なので, 成り立つことを示す必要があります. この判断も, 式の形が関数なのでを使います. すると前提は以下の形になります(いま下から3段目まできました).
今度は関数適用(関数呼び出し)の形になっていて, マッチするのはの規則です.
は前提が2つあるので, 枝が2つに分かれます. 左右の枝は次のようになります(いま下から4段目です).
(左)
(右)
左の枝は関数抽象でも関数適用でもなく, マッチするとしたらの規則だけです. 実際にマッチしていて, 型環境
には
を含んでいるので前提も成り立ちます.
の規則を使ったので, 左の枝はこれで終わりで, 成り立つことが確認できました.
右の枝も同様に繰り返し規則を使っていくとで終わらせることができます.
型検査とはこのように, 型付け規則をパターンマッチして結論から前提へと木構造を作っていき, すべての枝が判断を含まない前提で終わる形にすることで, たしかに結論の型がつくと確かめることです.
型検査: 型がつかない例
いまのは型がつく場合の例でした. 型がつかない場合にどうなるかも見ておきましょう. (x: (a:A) => B) => x(x)の式には型がつかないことを確認します.
まず, 式は関数の形になっているので最初に使う規則はしかありえません. 結論の部分にパターンマッチすると,
,
,
となります.
はまだなにかわからないのでいったん
のままにしておきます. これらの情報を使うと前提は以下の判断になります.
この判断の式の形は関数適用なのでの規則を使います. 前提の左右の枝は以下のようになります(
はまだなにかわからないのでそのままにしておきます).
(左)
(右)
左の枝にマッチするのはの規則だけです. パターンマッチしてみると前提が
でないといけないとわかるので, けっきょく
,
だったとわかります. ここまでは辻褄が合っていてとくに問題ありません.
一方, とわかったので右の枝は以下のようになっています.
(右)
やはり使える規則はだけですが, パターンマッチしてみると前提として
になる必要があり, これは成り立ちません.
だからです.
の前提を満たす以外に導出木を下から上へのばしていく方法はないので, 導出木は完成できません. したがって, 右の枝がどうやっても完成しないので,
(x: (a:A) => B) => x(x)の式には型がつかないとわかります. 全体像としては以下のようになっていました.
型付け規則やその導出に慣れるには練習が必要そうですね. こういったやり方を身につけたい人は以下の本を読むとよさそうです. オンライン課題提出(自動採点)システムで練習もできます.
)")
プログラミング言語の基礎概念 ((ライブラリ情報学コア・テキスト))
- 作者:五十嵐 淳
- 発売日: 2011/07/01
- メディア: 単行本
実際の型付言語の処理系は, 型がつく/つかないの検査を自動的にやるプログラム(型検査器(type checker))を内蔵していて, 人間にかわってこのような検査をやってくれているわけです.
型安全性
型付け規則を定めておくと, それに基づいて型検査器を実装できるだけでなく, 型検査を通ったプログラムが満たす性質を数学的な議論により証明できます. 巷で言われる「型安全性」とはこのことです.
たとえばSTLCの場合は以下のような性質が成り立ちます.
- 型のついた式は
-
- 実行した結果の値も同じ型になる.
- 最終結果だけでなく実行途中も同様
- 主部簡約定理(subject reduction)と言う
- 実行したら必ず停止する(必ず結果の値が得られる).
- 評価戦略によらない(遅延評価しても結果が変わらない)
- 強正規化性(strong normalization)と言う
- 実行した結果の値も同じ型になる.
これはSTLCの場合で, ふつうのプログラミング言語は無限ループが書けるので2つ目の性質は少し違って「停止したときは必ず値になっている(エラーにはならない)」という形になります. いずれにせよ, 型をつけることである種の「安全な操作」しかできないようになっているのは, このような性質によります. 型付け規則は闇雲に決めているわけではなく, こういった性質が成り立つようにうまく定めているのですね.
型付け規則のバリエーションや, 成り立つ性質の議論などについてもっと詳しく知りたい人は以下の本を読みましょう.

- 作者:Benjamin C. Pierce
- 発売日: 2013/03/26
- メディア: 単行本(ソフトカバー)
型検査の限界
STLCの型付け規則は非常に単純で, それゆえ限界もあります.
1つ目は, 実際のプログラミング言語では再帰関数のための型付け規則が入っているのでまず問題になりません. しかし2つ目はしばしば問題になります.
たとえば, 型がなければとくに問題のない以下のようなプログラムを考えます.
let apply2 = (f, n) => f(f(n)) apply2((n) => [n], 3)
=> [[3]]
一方, これに素朴に型をつけるとうまくいきません.
let apply2 = <A>(f: (a: A) => A, n: A) => f(f(n)) apply2((n) => [n], 3)
Type 'number[]' is not assignable to type 'number'
型システム(書ける型の種類や型付け規則を定めたもの)を工夫すればこういった不便をなくせる可能性はありますが, 一般に型システムの自由度を上げると型検査が決定不能*1になったり, 型安全性が成り立たなくなったりします. さまざまな型システムを備えたプログラミング言語が提案され続けるのは, 型検査が万能にはなりえない中で自由と安全のバランスを模索しているからです.
ここまでのまとめ
計算ありきで考えたときの型は, 自由を制限する代わりに安全を得るためのしくみでした.
- 型がなければ自由だがめちゃくちゃなこともできてしまう
- 型によって安全がもたらされるが自由は制限される
- 型システムは自由と安全のバランスの下に発展してきた
型ファーストで考える計算
ここまでは計算ファーストで, まずなにかやりたいことをコードで書いて, そこに型を書き加えることで安全になる話をしてきました. しかし実際に型付言語をばりばり書いている人たちはあまりそういうつもりで書いておらず, どちらかと言うとまず型を考えていそうです*3. まずやりたいことを型で表して, その型に沿う実装を書いていくのです.
この感覚は, 型をある種の仕様だと思うとしっくりきます. 実は感覚だけの問題ではなく, 理論上の必然としてそうなります.
型はある種の仕様
まずは例を見てみましょう. 関数型がとくに言語は関係ないので型の表記がわかりやすいScalaのメソッドのシグネチャをいくつか見てみます. Scalaが読める必要はありません.(x: A) => Bみたいな記法になるのがだるいので
1つ目は, はてなブックマークのソースコードに実際に登場するメソッドのシグネチャです.
BookmarkRepository.find: BookmarkId => Option[BookmarkEntity] // - ブックマークIDがあるなら, // - ブックマークのエンティティがあれば得られる
コメントとして書いたように, 型をそのまま読んで仕様がわかりますね. Option[A]型はSome[A](値があるとき)もしくはNone(値がないとき)を表す型なので, 「あれば」とつけるとスムーズに読めますね.
次の例はScalaの標準ライブラリから引っぱってきました. 列をソートするメソッドです.
Seq.sortBy: Seq[A] => (A => B) => Ordering[B] => Seq[A] // - Aの列があり, // - AをBに変換でき, // - Bの順序が規定されていれば, // - (Bでソート済みの)Aの列が得られる
Seq[A], A => B, Ordering[B]をそれぞれ, Aの列がある, AをBにできる, Bの順序が与えられている, と読めば, そこから新たなAの列ができる, と言っているとわかります. 最後に得られる列がBでソート済みなのは残念ながら型を見ただけではわかりません.
最後の例もScalaの標準ライブラリからです.
Either.fold: Either[A, B] => (A => C) => (B => C) => C // - AまたはBどちらかのインスタンスがあり, // - AからCへの変換と, BからCへの変換があれば, // - 常にCのインスタンスが得られる
Either[A, B]は, AもしくはBどちらのインスタンスでもかまわないときに使う型です. たとえばAにエラーを表す型を入れて, 「Bが得られるか, もしくはエラーが返る」ときによく使います.
Eitherにはfoldメソッドがあり, A, Bそれぞれを共通のCに変換するメソッドを与えると, 実際の値がA, BどちらであってもとにかくC型の値が得られます. foldの型を読んだそのままですね.
このように, 型Aが出てきたら「Aのインスタンスがある」に, =>が出てきたら「ならば」に置き換えながら読んでいくと, なんとなくどういう仕様のメソッドかを表した文になりそうです.
Curry-Howard同型対応
型を読むとまるで仕様のようになるのは偶然ではありません. ここまではふんわりと「仕様」と言っていましたが, 実のところ型は論理式で表した命題そのものであり, (型のついた)式による実装はその命題が成り立つことの証明です.
| 計算体系 | 論理体系 | (気持ち) |
|---|---|---|
| 型 | 論理式 | (仕様) |
| 型のついた式 | 証明 | (仕様が満たせる証拠) |
つまり, 式に型がつくことと, (その型に対応する論理式で表される)仕様を満たす実装が存在することは一致します. この対応関係をCurry-Howard同型対応(Curry-Howard isomorphism)と言います*4*5.
いきなり「型は論理式で式は証明だったんだよ!!!」と言われてもわけがわからないと思うので, 実際に一致していそうなことを視覚的に確認してみましょう.
まずは, STLCに加えて直積型(タプル)や直和型*6を入れた言語の型付け規則を見てみます(式の部分はTypeScriptですが都合により型の表記は別になっており, またに関するルールも加えられています).
この規則から式の部分を隠すと以下のようになります.
これは実は直観主義命題論理*7の推論規則まったくそのままで, GentzenのNJと呼ばれる自然演繹体系です*8. 自然演繹の体系では, 型付け規則でやったように, 推論規則を木構造につなげていって, すべての葉をにできれば根の判断が成り立ちます. (直観主義)命題論理の自然演繹なので, これらの規則を用いると「
ならば
」や「
ならば
で, かつ,
ならば
が成り立つなら,
ならば
も成り立つ」といった, 一般に成り立つ命題(トートロジーと言います)を導出できます. 逆に, この規則で導出できない命題はトートロジーではありません. たとえば, いま挙げた2つの例は以下のように証明できます.
ところで, 「型は論理式」の話を思い出すと, 2つ目の例のは型でもあります. では, この型のつく式はどういったものがあるでしょうか? たとえば以下の式がそうです*9.
(x: [(a:A) => B, (b:B) => C]) => (a: A) => x[1](x[0](a))
つまり,
と主張しているわけです. この主張が正しいかどうか確かめる(型検査する)には, 式を型付け規則にパターンマッチして, 根から葉へと導出木を作っていけばよいのでした. まず式全体は関数になっているのでの規則を使います. 次もまた関数なので
を再び使います. すると今度は関数適用なので
を使います. 左の枝はタプルの要素へのアクセスなので
を使います.
......といった具合にやっていくと, いま書いた命題論理での証明がそっくりそのまま復元されます. 型付け規則の結論の部分は(の規則をいったん忘れると)規則ごとにすべて異なるので, マッチする規則は毎回一つに決まります. すると復元される内容全体も, 式が決まれば一つに決まります. ということは, この式は命題論理での証明をTypeScriptの式の形にエンコードしたものになっているのです. これが「型のついた式は証明」の真相です.
Curry-Howard同型対応についてもっと詳しく知りたい人は以下の本を読みましょう.
 (English Edition)")
なぜ型ファースト?
ここまで分かればなぜ型ファーストなのかは明らかです.
何を証明したいか決めずに
証明を書くヤツはいない
というだけです.
たとえば, 「素数が無限に存在することを証明せよ」と言われたら「よーし, 素数が無限に存在することを証明するゾ」と思って証明しますよね. 「ふと, ある数を階乗してみた. ひとまず1を足してみた. なんとなく素因数を求めてみた. あれれぇ, 元の数が素数だとすると, この素因数はそれより大きいよね? これって素数が無限にあるってことじゃない?」なんて言ってなんの脈略もないところから突然なにかの証明を導き出してくる人はいないと思います. もしかしたらいるかもしれませんが天才っぽいですね. あまり真似できそうにありません.
プログラミングの話としては, テスト駆動開発との類似性を考えるとわかりやすいかもしれません. テスト駆動開発では, まずは機能の要件(つまり仕様)を満たすことをチェックするためのテストを書き, 最初はテストが失敗する状態にしておき, テストを通す最低限のコードを書いて, 徐々に洗練させていきます.
型ファーストも同じ考えで, 仕様が何なのかをまず書いて, それに沿うコードを書いていくのです. もし仕様そのものになんらかの不備があればそれを型として表現しようとした時点で不備に気づきやすくもなります. 闇雲に実装を書き始めるよりは, まずは仕様が何なのかはっきりさせましょう.
型は「ある種」の仕様
型によってある種の仕様を表現できましたが, どういう仕様を表現できるかは型の表現力次第です. たとえばsortByの例では, 結果の列がソート済みであることは型からはわかりませんでした.
Seq.sortBy: Seq[A] => (A => B) => Ordering[B] => Seq[A] // - Aの列があり, // - AをBに変換でき, // - Bの順序が規定されていれば, // - Aの列が得られる
型の表現力は, 対応する論理体系の論理式の表現力です. 命題論理なら論理式に書ける個々の要素は命題変数なので, 主語と述語の関係を表したりはできません.
ではもっとリッチな論理体系に対応する型システムにすればよいのかというと, 一概にそうとは言えません. あまり表現力の高い型システムにしてしまうと, 型検査が決定不能になったり, 型推論ができなくなったりします.
よりリッチな論理体系とそれに対応する計算体系の研究はさまざま進んでおり, 一部は実際のプログラミング言語にもとり入れられています. 例をいくつか挙げておきます.
| 論理体系 | 計算体系や言語 |
|---|---|
| 古典論理 | STLC + 継続 |
| 二階直観主義命題論理 | System F |
| 様相論理 | MetaOCaml |
| 線形論理(アフィン論理) | Rust |
たとえば, 計算体系System Fは二階論理に基づいているので, のような型が使えます(このような型を多相型と言います). しかし, System Fで型検査を決定可能にするためには型を明示的に書かなければならない場合があり, 型推論の恩恵が減って不便になります. なのでHaskellやMLといった実際のプログラミング言語では, System Fよりも少し制限された形の型システム(Hindley-Milner型システムと呼ばれるもの)を用いて, 多相型が使えて型推論も可能にしています.
仕様を細かく記述できる表現力の高い型システムにすることと, 型検査や型推論がうまくいくことの間にはトレードオフがあり, ここでもやはりよいバランスを追求していく必要があります.
ここまでのまとめ
- 型は論理式に, 型のついた式は証明に対応する
- 証明を書くときはまず命題から書く, だから実装を書くときはまず型から書く
- 型から書くのは仕様から書くのと同じ
- 仕様を型として細かく書けるとありがたいけど限界はある
型の表現を工夫する
型システムの表現力を高めるのには限界がありますが, さまざまな工夫によって仕様をうまく表現した型を考えることもできます. (筆者の知る限りでは)この部分にとくに体系だったなにかがあるわけでもないので, 思いつくままにいくつか紹介します. みなさんも「こんな工夫があるよ」というのがあれば是非それをご自身で紹介していってください. 「仕様としての型」をどんどん便利にしていきましょう.
思いつくままに書いたので例はすべてScalaです.
Scalaのimplicit
Scalaにはimplicitという言語機能があります. 使い道はいろいろありますが, 「仕様としての型」の観点では, 使う側に不便を強いることなく必要とされる前提を表現できてたいへん便利です.
たとえば, List[(A, B)]をMap[A, B]に変換するところでimplicitは使われています.
val l1: List[(Int, String)] = List(1 -> "foo", 2 -> "bar") val m1 = l1.toMap // m1: Map[Int, String]
ふつうですね. これがよくできているのは, タプル以外を要素とするListはMapには変換できないところです. 「できない」のは, やるとコケるのではなく, そもそもコンパイルが通りません.
val l2: List[Int] = List(1, 2, 3) val m2 = l2.toMap // コンパイルエラー
これは一体どう実装されているのでしょうか? 素朴にList[A]を定義しようとすると, 行き詰まってしまいます. Mapの型引数になんと書いていいかわからなくなるからです.
class List[A] { def toMap: Map[???] ... }
こう書けばいいでしょうか??
class List[A] { def toMap[K, V]: Map[K, V] ... }
これだと, AのListをどこの馬の骨とも知れないKからVへのMapに変換できてしまいます. たとえばList[Int]をMap[Int, String]にしてしまうといった具合です.
そこで, implicitを使えば「Aが(K, V)と互換性のある型である」前提を要求できます(<:<はScalaにあらかじめ定義されている型です)*10.
class List[A] { def toMap[K, V](implicit ev: A <:< (K, V)): Map[K, V] ... }
implicitな引数は, 呼び出されたコンテキストで静的に解決できるimplicitな値があれば自動的に解決される(今回の場合は<:<のimplicit値は標準で定義されていてどのコンテキストからでも解決されます)ので, Aがなんらかのタプル型である限りは呼び出し側はとくに引数を渡す必要はありません.
スマートコンストラクタ
Scalaのリストは空の場合にheadで先頭要素を取り出すと実行時エラー(例外)が発生します.
val l1 = List(1, 2, 3) l1.head // => 1 val l2 = List() l2.head // 実行時エラー
こういうことがないように, 「空でないリスト」をなんとか型で表現したくなりますね. しかし「List[A]のインスタンスであって, そして空でない」ことを論理として扱うのはけっこう大変です.
そこで, 「空でない」かどうかチェックするところは実行時に確かめるコードとして書いてしまって, チェック済みを表すタグとして型を使えば, 条件がいくら複雑になっても簡単に表現できます. もちろん, そのタグの型はチェックに通ったときしかインスタンス化できないようにします.
class Nel[A] private (val v: List[A]) object Nel { def apply[A](v: A*): Option[Nel[A]] = fromList(v.toList) def fromList[A](l: List[A]): Option[Nel[A]] = if (l.nonEmpty) Some(new Nel(l)) else None }
Nelクラスのコンストラクタはprivateなのでこのクラスの外でnew Nelはできず, Nelのインスタンスを作るにはNel.applyかNel.fromListを使うしかありませんが, これらはNel()のように空で呼び出すとNoneが返ります. Some[Nel[A]]のインスタンスが得られたときは必ず空ではないと保証されます*11.
val nel1 = Nel(1, 2, 3) nel1.map(_.v.head) // => Some(1) val nel2 = Nel() nel2.map(_.v.head) // => None
篩型 (refinement type)
スマートコンストラクタの例では, 実際にリストの操作をするときには.vを経由する必要があって面倒ですね. できれば元のList[A]のインタフェースはそのままに, 空でない裏付けがタグとして付加された形にしたいものです. まさにこれを実現する考え方が篩型(refinement type)です.
篩型は, 交差型(intersection type)を用いて追加の制約を表現するアイディアです. Scalaには交差型がある(A with Bのような型)ので実現できます. 以下のように使うイメージです(定義はちょっとむずかしいので省いています).
val Some(nel) = RefinedNel(1, 2, 3) // nel: List[Int] with NonEmpty nel.head // => 1 nel.map(n => n * n) // => List(1, 4, 9) nel.flatMap(n => List()) // => List()
篩型版のNel(RefinedNel)はスマートコンストラクタで空でない場合だけインスタンスを返すのは同じですが, RefinedNelのインスタンスを返すのではなくList[A] with NonEmptyのインスタンスを返します. これはれっきとしたList[A]型なので, List[A]のメソッドはそのまま呼べます(たとえばheadやmap, flatMap).
ただ, 一つ面倒な点があります. 空でないList[A]をmapしても「空でない」ことは保たれるはずですが, 結果はただのList[A]になってしまってNonEmptyタグが外れてしまうので, 「空でない」情報が失われてしまいます. 裏側では篩型の概念を使いつつも非空性を保つかどうかを注意深く扱った拙作のライブラリがあるのでご利用ください.
篩型は以下の論文で提案されました.
- Refinement Types for ML.
Tim Freeman and Frank Pfenning.
In Proceedings of the ACM SIGPLAN 1991 Conference on Programming Language Design and Implementation (PLDI '91), pages 268-277, New York, NY, 1991.
高カインド型
カインドは, 型コンストラクタの型のことです. 型コンストラクタとは「型に適用して型を得るもの」のことで, たとえばList[_]は, Intに適用してList[Int]型を得る型コンストラクタです. 「高カインド型」(がある言語でサポートされている)とは, 型(パラメータ)として型コンストラクタを渡せるという意味です.
例としては以下のように, 型コンストラクタをふつうの型と同様に型パラメータにできます.
trait ApplyToString[CC[_]] { type Result = CC[String] } val stringList: ApplyToString[List]#Result = List("a", "b", "c") val stringArray: ApplyToString[Array]#Result = Array("a", "b", "c")
これ自体は型システムの表現力の問題になりますが, サポートしている言語は(多くはないものの)そこそこあるのでうまくすれば大きなデメリットなしに実現できるはずです. Haskell, Scala, C++, Rustあたりでは使えると思います.
高カインド型にはさまざまな応用がありますが, たとえば圏論的な概念を素直に表現できます*12. 例として, Scala標準のタプル型(Tuple2)と, 独自に定義した直積型(|*|)のどちらであっても同じように要素を取り出せるメソッドπ1とπ2を定義して, Tuple2と|*|を相互変換する場合を見てみましょう(完全なコードはこちら).
val p1 = |*|(1, "foo") // 独自定義の直積型 // => p1: Int |*| String = <1, foo> π1(p1) // => res0: Int = 1 π2(p1) // => res1: String = foo val p2 = ("bar", 2) // Scala標準のタプル // => p2: (String, Int) = (bar,2) π1(p2) // => res2: String = bar π2(p2) // => res3: Int = 2 p1.toProduct[Tuple2] // => res4: (Int, String) = (1,foo) p2.toProduct[|*|] // => res5: String |*| Int = <bar, 2>
π1とπ2の定義は以下のようになっていて, なんらかの型コンストラクタP[_, _]に対して, それを2項の直積として扱える証拠Product2[P]があれば, 要素を取り出せる定義になっています.
def π1[A, B, P[_, _]](p: P[A, B])(implicit product: Product2[P]): A = product.p1(p) def π2[A, B, P[_, _]](p: P[A, B])(implicit product: Product2[P]): B = product.p2(p)
toProductの方も, Tuple2や|*|といった具体的な型コンストラクタに言及しない定義になっています.
implicit class WedgeOps[W, A, B](val w: W)(implicit wedge: Wedge[W, A, B] ) { def toProduct[P[_, _]](implicit product: Product2[P], ): P[A, B] = product.mediate[A, B, W](wedge)(w) }
これらは以下の本を社内で輪読したときにささっと書いたものですが, 高カインド型がなかったらコードで表現できるとは思わなかったでしょう.
")
Basic Category Theory for Computer Scientists (Foundations of Computing)
- 作者:Pierce, Benjamin C.
- 発売日: 1991/08/07
- メディア: ペーパーバック
逆に, 圏論的なものをコードに落とし込めれば強力な抽象概念を記述でき, 「仕様としての型」の幅がだいぶ広がります.
おわりに
計算ファーストは自由を制限して安全を得る考え方, 型ファーストは仕様から先に考えるやり方でした. まず仕様を考えるやり方にすればあまり「自由を制限されている」気持ちにならずに済みます. とはいえ仕様を型として表現するには限界もあるので, うまく工夫していきましょうという話でした.
そういえば, ちょうど10年前にもラムダ計算の話を書いていました. またラムダ計算の話してる......
このときは「最速マスター」の流行に乗る都合もあって, 記述はなるべく少なく, 意義はともかく最速で説明する内容でした. 今回は対照的に, 言葉を尽くして形式的な概念をプログラミングするときの心構えにつなげる内容になりました. 10年でいろいろ成長して(歳をとって)見えてきたからこういう話も書けるようになったのでしょうか. でも, ここに書いたことは10年前には知っていたことばかりなので何も変わってないとも言えますね. 「最速マスター」では型なしラムダ計算の話しかしなかったので, 10年越しに続きを書いた感じもします.
*2:当時はコンピュータもプログラムも存在しなかったので, 当然プログラミング上の関心事にはなりえません
*3:計算ファーストだけど型付言語をばりばり書いているつもりだった人は......なんか, がんばりましょう
*4:ちなみに, この対応関係の発見者のCurryさんは, プログラミング言語Haskellの名前の由来となったHaskell Curryさんであり, カリー化の概念でおなじみのカリーさんです
*5:ちなみに, 計算体系と論理体系の一致に加えて, デカルト閉圏という圏論上の概念とも一致することが知られていて, Curry-Howard-Lambek対応とも言います
*6:TypeScriptには直接的な直和型はありませんがやりようはあるのでそれを反映した形になっています
*7:古典命題論理(ふつうの論理)から二重否定除去のルールを除いた論理体系
*8:もともとのGentzenの表記では⊦(ターンスタイル記号)を使わずに木構造の上の方に出てくる仮定を下の方で参照する形で, 論理学の教科書でもそちらの定義のしかたをよく見ると思いますが, 本質的には同じものです
*9:他にも同じ型になる式はあります
*10:Scalaの標準ライブラリのソースコードを見ていると, このような引数の名前は多くの場合"ev"になっていて, おそらく"evidence"の略で, 「証拠」を要求しているわけですね
*11:細かいことを言うとmutableなリストを与えられたらダメなので本来はimmutableに限定したり, 渡された時点でimmutableなリストに変換するなりすべきです
*12:たとえば, 関手(functor)はすべて型コンストラクタで(も)あると思え, 自然変換(natural transformation)を表現するには「関手を受け取って何かする」必要があるため