概要
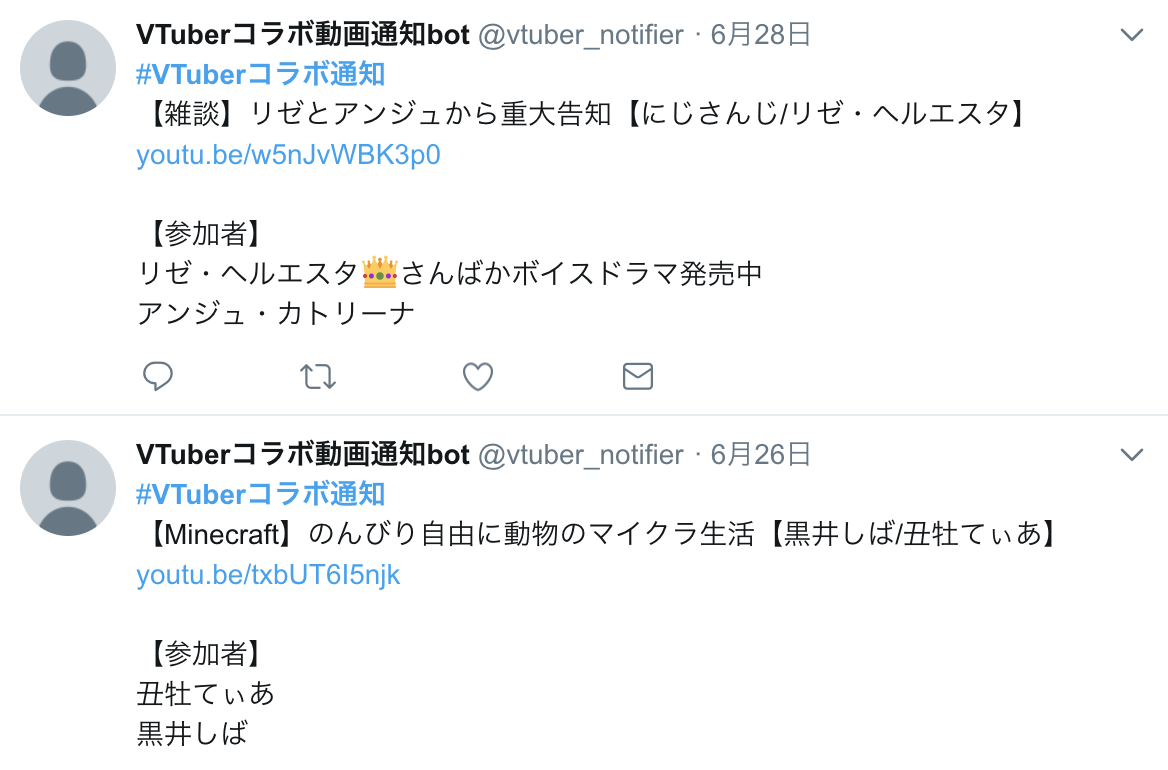
VTuber の新着動画を監視し、複数人が参加するコラボだと判定した場合に Twitter で呟くシステムを作成しました。
リンク
解決したい問題
VTuber の界隈では、複数人が参加するコラボ動画(ライブ配信)が頻繁に投稿されます。
しかし一方で、 YouTube のチャンネル登録の仕組みは、コラボ動画をフォローするのには適していません。
例えば A さんと B さんのコラボ動画が A さんのチャンネルだけに投稿された場合を考えてみてください。この動画には B さんが参加しているにも拘らず、 B さんのチャンネルに登録している人には通知が届きません。
そこで今回は、 VTuber 動画の参加者を特定してデータベースに保存し、コラボ動画だけを通知するシステムを作成しました。
仕組み
VTuber 動画の参加者を特定する方法
VTuber がコラボをする際には、参加者の YouTube チャンネルへのリンクを動画の概要欄に貼る慣習があります。
これを利用して、以下のような方法で動画の参加者を特定しました:
- VTuber のチャンネル URL のリストをデータベースに保存
- VTuber の新着動画の概要欄から、正規表現検索でチャンネル URL を抽出
- 抽出した URL で VTuber データベースを検索
アーキテクチャ
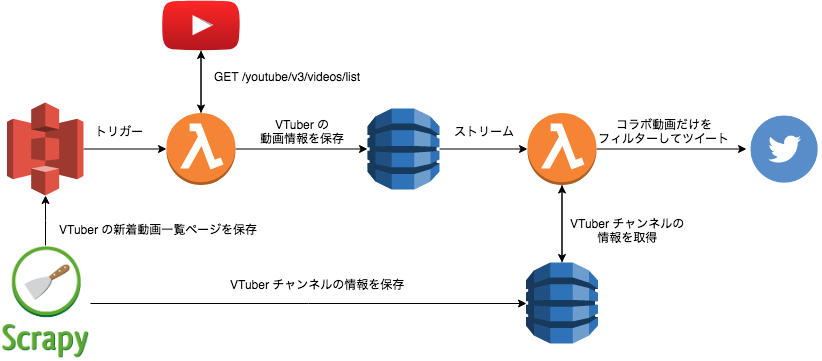
アプリの性質上常に稼働している必要は無いので、イベント駆動型で計算時間の分だけ課金される serverless アーキテクチャを採用しました。
VTuber の新着動画やチャンネル情報を取得するために、 Scrapy で以下のページを定期的にダウンロードします。
新着動画があれば AWS Lambda が処理を継続し、動画の詳細情報取得、参加者特定、ツイートを行います。
製作中に諸々の予定変更があった影響で、スクレイピングまわりはあまり綺麗な設計にはなっていません。
動画一覧を取得する際には、 Scrapy は HTML を S3 に保存する処理だけを担当し、スクレイピングはその後の Lambda が担当します。
一方でチャンネル一覧を取得する際には、 Scrapy でスクレイピングまで行ってから直接 DynamoDB に保存します。
各種準備
AWS + Serverless Framework の準備
今回開発するアプリには Lambda、S3、DynamoDB の 3 種類の AWS サービスが絡み、これらのリソース作成、イベント紐付け、権限管理など煩雑な設定が必要になります。
こうした設定を毎回手動でやっていると、面倒で、バージョン管理ができず、ミスが発生しやすくなります。
CLI ツールの Serverless Framework を使用すると、各種設定を YAML 形式のファイルに記述しておき、コマンド一発で自動的にデプロイすることが可能です。
今回は AWS ですが、 Serverless Framework 自体は GCP や Azure など他のクラウドサービスにも対応しています。
Serverless Framework を使うには、まず npm の serverless パッケージをインストールします。
また、 CLI ツールがあなたに代わって AWS リソースにアクセスするために IAM user の作成が必要です。
詳細な手順は以下の公式ガイドを参照:
- Serverless Framework - AWS Lambda Guide - Quick Start
- Serverless Framework - AWS Lambda Guide - Credentials
GCP アカウントの準備
動画の詳細情報(特に、概要欄の全文)を取得するために YouTube Data API (v3) を利用します。
GCP コンソールから以下の設定をしてください:
- 新規プロジェクトを作成
- YouTube Data API v3 を検索し有効化
- API キーを作成
- API キーを YouTube Data API v3 だけに制限
Twitter API の利用申請
2018年7月24日以降に新しく Twitter API を利用する場合、 Twitter Developers で開発者アカウントを作成し審査を受ける必要があります。1
この申請が面倒で、アプリの用途などを 300 字程度の文章で説明しなければいけません。
申請内容によってはメールで追加の質問が来たり、許可されるまでに 10 日以上かかることもあるようです。2
私の場合、以下の説明を記載して申請したところ 3 時間後に申請許可のメール通知が届きました。
In English, please describe how you plan to use Twitter data and/or APIs.
I will use the API to make a tweet bot. My app monitors certain YouTube channels, and tweets URLs whenever new videos with particular conditions are published. The rate of tweets will be at most 100/day.
Will your app use Tweet, Retweet, like, follow, or Direct Message functionality?
My app will use only the Tweet functionality. The rate of tweets will be at most 100/day. It will NOT tweet on behalf of other users.
ハマりどころ
YouTube Data API のレート制限
当初の構想では、 VTuber の新着動画の取得をスクレイピングではなく YouTube API でやろうと考えていました。 search/list で channelId を指定して各 VTuber の動画を検索するという方法です。
しかし、実際にこれをやると一瞬で API のレート制限を食らいます。
現時点で新しく YouTube Data API を有効化すると、一日あたりに使える quota は 10,000 units しかありません。
quota の消費量はリクエストの種類によって異なり、例えば search/list なら 100 units 、
videos/list なら最低 3 units です。
各リクエストの quota 消費量についてより詳しい情報は公式ドキュメントにあります。一方で、一日あたりの quota 上限は私の見た限りどこにも記述が無いので、正確な情報は GCP コンソールで確認してください。
Twitter の文字数制限
ご存知の通りツイートには文字数制限があり、長すぎるツイートを投稿しようとすると API にエラーを返されます。
このエラーに対処するための方針として考えられるのは:
- 事前にツイートの文字数をカウントして、制限を超過していたらリクエストをしない
- ツイートを試みて、文字数制限によるエラーが発生したら例外処理
前者は無駄な API リクエストもエラーも発生しないため何となくスマートな気がしますが、完璧に実装しようとするとかなり厄介です。というのも、 Twitter の文字数カウントはそれだけで 1 つのライブラリになるほど複雑なためです。
- Counting Characters - Twitter Developers
- twitter-text Parser - Twitter Developers
- twitter/twitter-text: Twitter Text Libraries
ライブラリは Java, Ruby, JavaScript, Objective-C 用に作られており、 Python は残念ながら対象外です。
DynamoDB に空文字列を含むオブジェクトを保存できない
YouTube API から取得した動画の詳細情報を DynamoDB に保存する際に、以下のエラーが発生しました。
One or more parameter values were invalid: An AttributeValue may not contain an empty string
どういうわけかわかりませんが DynamoDB には空文字列が保存できないようで、公式ドキュメントにも記載があります:
The length of a string must be greater than zero and is constrained by the maximum DynamoDB item size limit of 400 KB.
Java SDK の場合オプションで空文字列を null に変換できます3が、 Python の Boto3 にはそのような機能は(私の知る限り)ありません。そのため、自前で以下のような関数を実装しました:
from toolz.dicttoolz import valmap
def emptystr_to_none(item):
if isinstance(item, list):
return list(map(emptystr_to_none, item))
elif isinstance(item, dict):
return valmap(emptystr_to_none, item)
elif item == "":
return None
else:
return item
ただし、本来 None と空文字は意味的に異なるオブジェクトなので、この変換によって何らかの微妙なバグが発生する恐れはあります。
あくまでその場しのぎの対策として注意して使いましょう。
S3 のバケット名は globally unique
あるとき channels という名前の S3 バケットを serverless.yml に設定してデプロイを試みると、以下のようなエラーが発生しました:
Serverless Error ---------------------------------------
An error occurred: S3BucketChannels - channels already exists.
しかし AWS コンソールを見ても serverless.yml を隅から隅までチェックしても、同名の S3 バケットなどどこにもありません。
しばらく調べて回った末、エラーの原因は公式ドキュメントの中であっさり見つかりました:
Bucket names must be unique across all existing bucket names in Amazon S3.
BeautifulSoup のエラー : "Couldn't find a tree builder"
HTML から情報を抽出するためのライブラリとして、 Python では BeautifulSoup が有名です。
AWS Lambda でこうしたサードパーティーのライブラリを使う場合には全て一つの zip ファイルにまとめる必要がありますが、その際のディレクトリ構成が原因で BeautifulSoup の妙なバグに遭遇しました。詳細は別の記事にまとめてあります。
BeautifulSoup のエラー "Couldn't find a tree builder" の原因と対処法
課題
誤検知
- コラボ動画である => 概要欄にチャンネル URL がある
はかなり高確率で正しい印象ですが、一方でその逆
- 概要欄にチャンネル URL がある => コラボ動画である
は成り立たないことが多くあります。特に、少人数のグループで活動している VTuber の場合、コラボか否かに拘らず毎回動画の概要欄にグループメンバーのチャンネル URL を貼る傾向が見られました。
一時的な対策として、他チャンネルの URL を毎回貼っている VTuber は見つけ次第 DB から削除するようにしています。
しかしこの方法だと、 DB から削除した VTuber が本当にコラボ動画を投稿した場合に検知できなくなるという難点が残っています。
UI
今回 Twitter bot という形を取ったのは、単純に UI 開発を手抜きしつつ手っ取り早く一般公開もできるようにするためです。
(自分自身を含め)最も需要があるユースケースは恐らく「お気に入りの VTuber が参加しているコラボ動画だけを確認する」パターンだろうと考えています。現状の Twitter bot でも、 TweetDeck の Search カラムなどを活用すればこのユースケースは実現可能です。
一方で、より細かい条件の指定やプッシュ通知設定などは不可能なので、そのうち Web アプリも制作してこれらの機能を実現する予定でいます。