
7月3日、How-To Geekが「Ollama is the open-source app that finally made free local AI useful on my PC」と題した記事を公開した。この記事では、オープンソースのローカルLLMランチャー「Ollama」を使って、300ドル以下のミニPCでAIを実用レベルで動かすまでの体験について詳しく紹介されている。
ローカルLLMはずっと「理論上は便利だが、実際には開発者向け」という立ち位置だった。モデルのダウンロード、コマンドライン操作、ハードウェア要件の調査——一般ユーザーが途中で諦める理由には事欠かなかった。Ollamaはその状況を変えつつある。
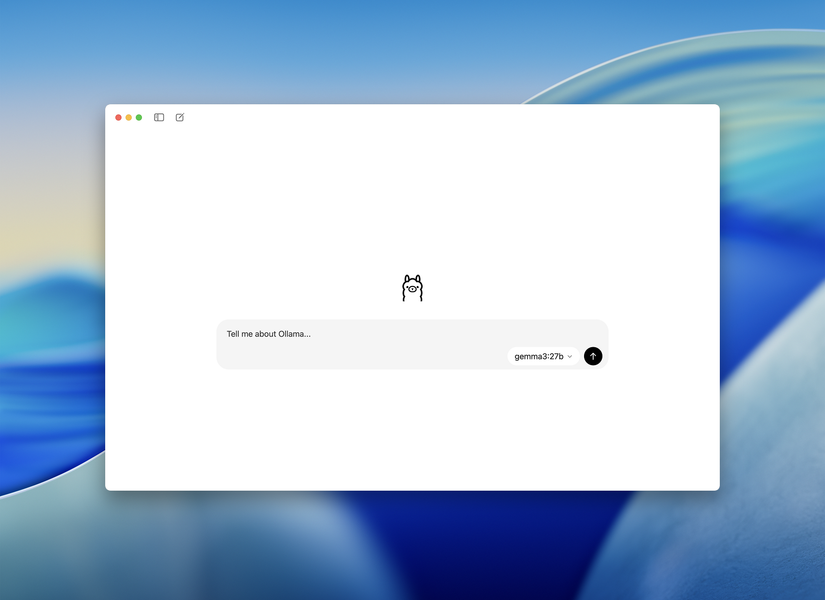
コマンドラインなしでモデルをインストールできる
記事の著者が最も驚いたのは、セットアップの少なさだ。最初はPowerShellでGemma 3をインストールしていたが、OllamaがGUIからモデルを直接インストールできることに気づいた時点で、体験が一変したという。
ドキュメントを漁ったり、セットアップガイドからコマンドをコピーしたり、手順を間違えていないか心配したりする必要がなかった。アプリを開いてモデルを選んで、始められた。
Ollamaの公式インストーラをダウンロードして実行するだけで動作し、モデルの選択もGUI上で完結する。「プログラムをインストールしてアプリを操作できる」レベルのリテラシーがあれば、ローカルAIは手が届く範囲に入った。
モデル選びがポイント——ハードウェアとの相性
インストールより手間がかかったのがモデルの選定だ。著者が使ったミニPCには専用GPUがなく、大きなモデルを選んでも実用的な速度で動かない。元記事によれば、このミニPCは16GB RAM搭載のIntel N100ベースのマシンで、価格は300ドル以下とのことだ。ハードウェアを選ぶ際の現実的なラインとして参考になる数字といえる。
試行錯誤の末、Gemma 3:12Bが最も合っていると判断した。Gemma 3はGoogleが開発・公開しているオープンウェイトモデルファミリーで、商用利用も可能なライセンスが特徴だ。「12B」はパラメータ数(120億)を指し、Googleが公開しているモデルカードによれば、同クラスのオープンモデルの中では推論性能と軽量さのバランスが取れているとされている。
実測値はOllamaの報告によると以下の通りだ:
- プロンプト処理速度: 31.78トークン/秒
- 応答生成速度: 7.1トークン/秒
プロンプトの解析は比較的速いが、応答の生成はクラウドのチャットボットより遅い。それでも、アウトラインの作成、テキストの要約、メモの整理、簡単な文章補助といった「低リスクな日常作業」には十分実用的だったという。
実際の作業に使って初めて価値がわかる
著者がOllamaを「テスト対象」から「日常ツール」に切り替えたのは、普段ChatGPTに投げていた作業を試した時だった。アイデアの整理、ノートのクリーンアップ、テキストの要約、選択肢の比較など——クラウドサービスほど速くも洗練されてもいないが、「ローカルで動いているので、書きかけのアイデアや非公開のメモをわざわざ外部に送らなくていい」という点が実質的なメリットとして機能した。
Credit: Ollama
クラウドを置き換えるものではない
著者はOllama導入後もChatGPT、Claude、Geminiを使い続けている。速度、最新情報へのアクセス、高度な推論、テキスト以外の機能ではクラウドサービスが上回る。Ollamaはそれらすべてでクラウドサービスに勝つ必要はなく、「プライバシーと手元での制御が優先される日常作業」に特化して使うという役割分担が自然に生まれた形だ。
なお、同様のアプローチを取るツールとしてLM Studioも言及されている。より従来のデスクトップアプリ的なUIを好むユーザーには選択肢になる。
まとめ
Ollamaが変えたのは、ローカルLLMを「週末プロジェクト」から「普通のPCアプリ」にしたことだ。専用GPUなし、コマンドライン操作最小限、GUIだけでモデルの選択と実行が完結するという体験は、以前のローカルAIとは明確に異なる。16GB RAM・Intel N100という手頃なスペックのミニPCでも実用的に動作することが示された点は、ハードウェア選定を検討している読者にとっても具体的な指針になる。ハードウェアの制約でモデル選定に調査は必要だが、そのハードルは大幅に下がっている。
詳細はOllama is the open-source app that finally made free local AI useful on my PCを参照していただきたい。