
7月4日、Roboflowが「Claude Sonnet 5 for Vision: Evaluation and Benchmarks」と題した記事を公開した。Anthropicが6月30日にリリースしたClaude Sonnet 5のビジョン性能を67プロンプトで実測し、競合モデルと比較した評価結果をまとめたものだ。
結論から言う:Sonnet 5はビジョンで「横ばい」
Roboflowが独自に整備したRoboflow Vision Evals(オブジェクト理解・空間理解・文書理解・欠陥検出・カウントの5カテゴリ、67プロンプト)でClaude Sonnet 5を評価した結果、67問中47問(70%)をパスした。これは前モデルのClaude Sonnet 4.6(※元記事の表記のまま)と完全に同点である。
比較対象との順位は以下の通りだ。
| モデル | ビジョンスコア | 入力コスト | 出力コスト |
|---|---|---|---|
| Gemini 3.5 Flash | 79% | $1.50 / MTok | $9 / MTok |
| Claude Fable 5(※元記事の表記のまま) | 75% | $10 / MTok | $50 / MTok |
| Claude Sonnet 5 | 70% | $3 / MTok ※ | $15 / MTok ※ |
| Claude Sonnet 4.6(※同上) | 70% | $3 / MTok | $15 / MTok |
※ 2026年8月31日までの導入期間は入力$2 / MTok、出力$10 / MTokの特別価格が適用される。
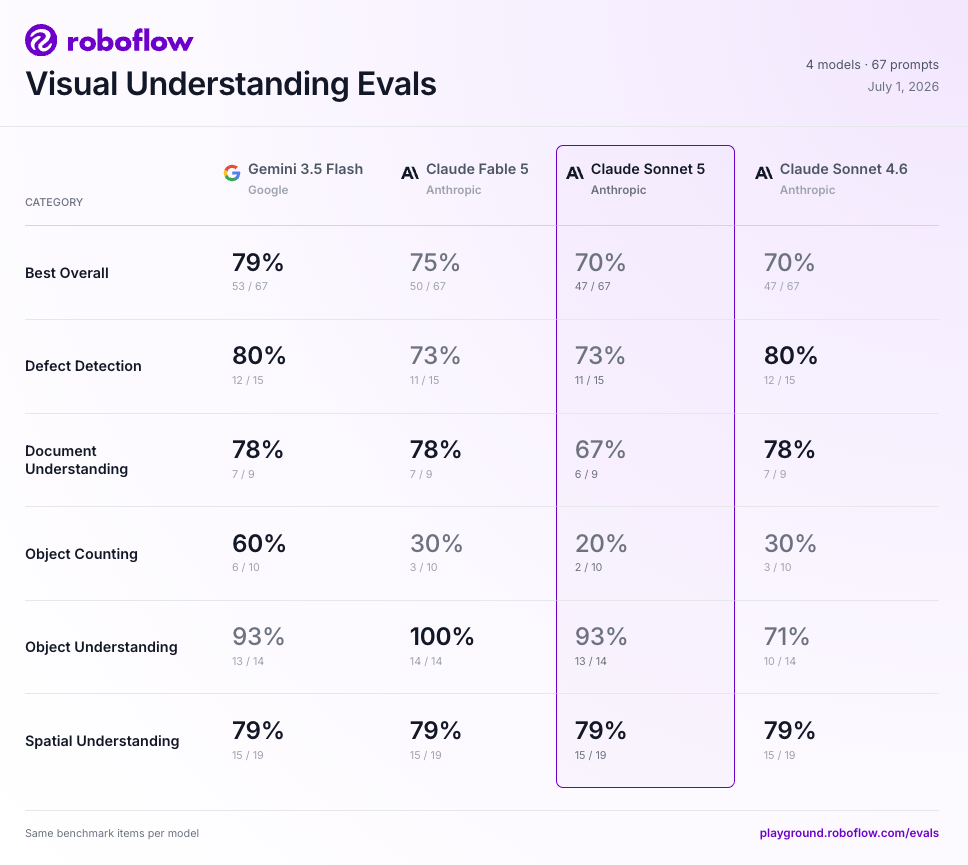
Gemini 3.5 Flashはスコアでも9ポイント上回りながらトークン単価は最安という状況であり、Sonnet 5はスコアとコストの両面で優位性を示せていない。なお「コスパではGemini 3.5 Flashに軍配」としているのはこうした総合的な文脈に基づく評価であり、コスト単体の比較ではない点に留意されたい。
カテゴリ別の詳細:「同点」の中身は入れ替わり
総合スコアの同点は、内訳の入れ替わりで相殺された結果だ。
- オブジェクト理解: Sonnet 5が**93%**と大幅改善(Sonnet 4.6は71%)
- 文書理解: Sonnet 5が**67%**で4モデル中最下位
- オブジェクトカウント: Sonnet 5が20%(10問中2問)で、これも4モデル中最低
文書理解とカウントにおけるスコア低下は元記事でも明確に指摘されている数値の差であり、前世代との比較で後退が見られる領域だ。カウントタスクの失敗パターンはVLM(視覚言語モデル)全般に共通する弱点でもある。オブジェクトが少なく離れている場合は機能するが、密集・遮蔽が発生すると精度が急落する傾向があり、Sonnet 5はそのグループの中でも最も低いスコアだった。
VLM全体の精度競争という文脈で言えば、AnthropicはClaude 3シリーズ以降、テキスト推論と並行してマルチモーダル能力の強化を継続的に謳ってきた。しかし今回の評価が示すように、ビジョン性能の向上はコーディングや推論ほど直線的ではなく、カテゴリによって伸びと後退が混在する状況が続いている。競合のGemini系列(Google DeepMind)やGPT-4oシリーズ(OpenAI)もマルチモーダル強化を進めており、VLM市場は依然として流動的だ。
どう使うべきか
Roboflowは用途別に明確な使い分けを示している。
Sonnet 5が有効な場面:視覚的な質問応答や一般的な画像理解。すでにテキスト用途でClaudeを使っている環境に画像入力を追加するケースでは、シーンの説明や質問への回答は十分こなせる。
Sonnet 5を使うべきでない場面:物体検出・カウント・セグメンテーション。これらの用途にはVLMよりファインチューニング済みの専用モデル(例:RF-DETR)の方が精度・コスト・レイテンシのすべてで上回るとRoboflowは指摘している。また、ビジョン精度のコストパフォーマンスを重視するならGemini 3.5 Flashが現時点でのトップという評価だ。
Sonnet 5のリリース時はコーディング性能と速度が注目を集めたが、ビジョン性能については前世代からの大きな進歩は確認されなかった。文書理解とカウントでスコアの後退が見られることも踏まえると、ビジョン用途での乗り換え理由は現状見当たらない。
詳細はClaude Sonnet 5 for Vision: Evaluation and Benchmarksを参照していただきたい。