2月13日、karpathy氏が「microgpt · GitHub」と題したGistを公開した。
このコードは、GPTの動作原理を外部ライブラリに頼らずPythonのみで記述した、最小構成の実装となっており、その読みやすさと理解のしやすさから注目を集めている。
以下に、これからこのソースコードを読み解こうとする方に向けて、GPTがどのように動き学習するのか、その大まかな流れと主要な概念を解説する。
コードリーディング・ガイド:microgptを読み解く
本プログラムは、大きく分けて「微分の自動化」「情報の変換」「予測と修正」の3つのパートで構成されている。
1. 「学習」を支える自動微分(Valueクラス)
ニューラルネットワークが学習するためには、予測の誤りを数値化し、それを元に各パラメータをどの程度調整すべきかを計算する必要がある。本実装の冒頭に登場する Value クラスは、この「微分」という数学的操作を自動化する。
- 役割: 加算(
__add__)や乗算(__mul__)といった基本演算が行われるたびに、計算の履歴(グラフ)を記録する。 - 仕組み:
backward()メソッドを呼び出すことで、出力から入力へ向かって逆方向にたどり、各値が最終的な結果にどれだけ影響を与えたか(勾配)を算出する。
2. 文字から意味へ(Tokenizer & Embedding)
コンピューターは文字列をそのまま理解できないため、まずは数値の羅列に変換するプロセスが必要だ。
- Tokenizer: 登場する文字をID(整数)に割り当てる。
- Embedding: 数値化された文字を、16次元のベクトル(空間上の位置情報)として表現する。これにより、文字同士の「距離」や「関係性」をモデルが扱えるようになる。
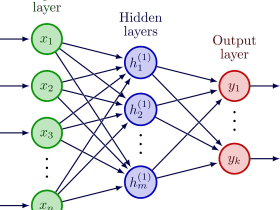
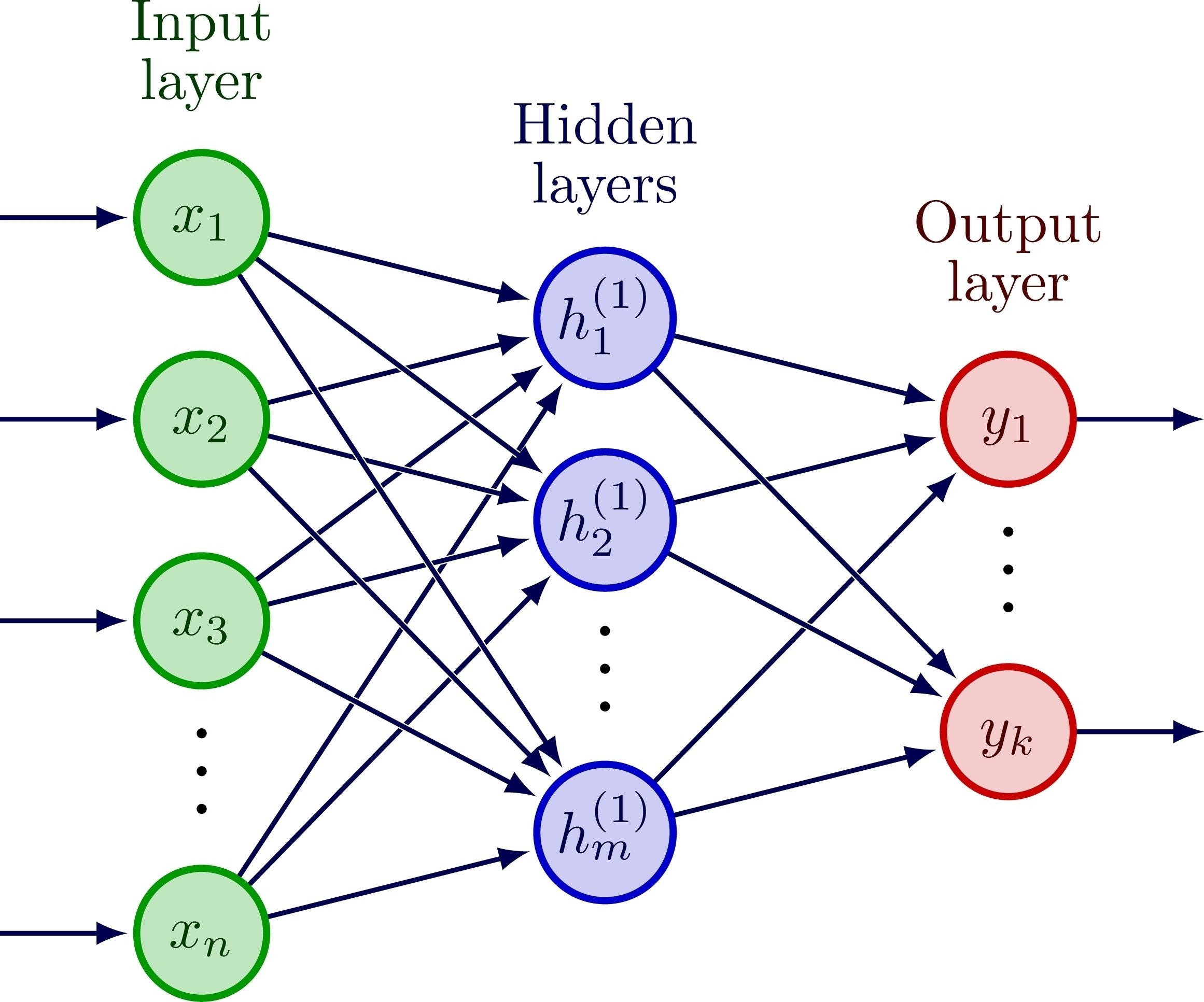
3. GPTの心臓部(Attention & Transformer)
モデルの中心部では、入力された文字の並びから「次に続くべき文字」を特定するための計算が行われる。
- Attention(注目): 文脈の中でどの文字が重要かを判断する仕組みだ。例えば「私は」の次に続く言葉を探す際、「私」という主語に強く注目するような重み付けを行う。
- Forward Pass: 現在の入力から確率分布(次にどの文字が出るか)を算出する順方向の計算である。
処理の全体フロー
ソースコードの後半では、以下のステップがループ(学習)として記述されている。
- データ読み込み: 外部からテキストデータを取得し、文字単位で分解する。
- 順伝播(Forward): 現在の文字から次の文字を予測し、その予測がどれだけ外れているか(Loss)を計算する。
- 逆伝播(Backward): 計算された「外れ具合」を
Valueクラスの仕組みを使って遡り、各パラメータの修正量を導き出す。 - 更新(Optimizer): Adamと呼ばれる手法に基づき、実際にパラメータの数値を微調整する。
# コード内の学習ループの概念図
for step in range(num_steps):
# 1. 入力データ(名前のデータセット等)を準備
# 2. GPTモデルによる次文字の予測
logits = gpt(token_id, pos_id, keys, values)
# 3. 予測の「ズレ」を計算し、自動微分を実行
loss.backward()
# 4. 微調整(学習)を適用してパラメータを更新
p.data -= lr_t * m_hat / (v_hat ** 0.5 + eps_adam)
4. 生成(Inference)
学習を終えたモデルは、自ら文章を紡ぎ始める。特定の文字からスタートし、予測された「次の文字」を再び入力として戻すことで、連鎖的にテキストが生成される。温度係数(temperature)を調整することで、出力の「創造性(ランダム性)」を制御している点も興味深い。
結論
microgpt.py は、複雑なブラックボックスと思われがちな生成AIが、実はシンプルな数学と論理の積み重ねで構築されていることを示している。コードを一行ずつ追うことで、Transformerの構造を抽象的な概念としてではなく、具体的な実装として理解できるはずだ。
詳細はmicrogpt · GitHubを参照していただきたい。