
1月28日、Googleが「Introducing Agentic Vision in Gemini 3 Flash」と題した記事を公開した。この記事では、Gemini 3 Flashに搭載された「Agentic Vision(エージェント・ビジョン)」という、AIの視覚能力を根本から変える新技術について詳しく紹介されている。

以下に、その内容を紹介する。
【概要】AIは「一瞬の静止画」ではなく「能動的な観察」を手に入れた
これまでのAIによる画像理解は、いわば「一枚の写真をパッと見て、その瞬間の記憶だけで答える」というスタンスであった。そのため、写真の隅にある小さな文字や細かな部品の型番など、一見して判別できない情報は「勘」で補うしかなかった。
今回発表されたAgentic Visionの革新性は、この受動的な画像理解を、AI自らが動的に動く「調査プロセス」へと進化させた点にある。例えるなら、「虫眼鏡を手に取って、気になる場所をズームしたり、角度を変えたりしながら、納得いくまで調べ尽くす」という、人間に近い観察プロセスをAIが自律的に実行できるようになったのだ。
Gemini 3 Flashはこの「自分で調べて確認する」能力により、主要な視覚ベンチマークにおいて5〜10%の精度向上を達成している。
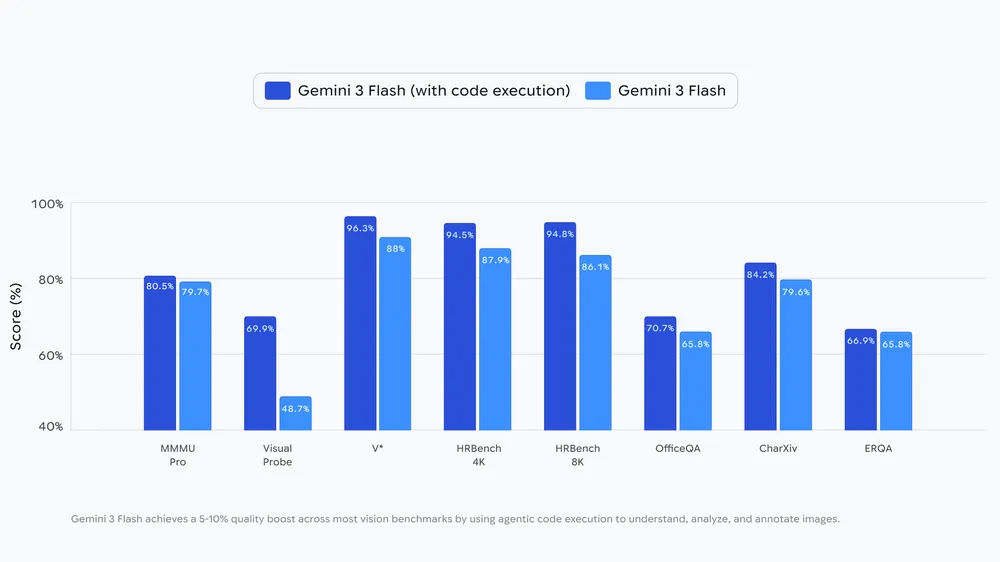
公式ブログより引用。主要な視覚ベンチマークにおいて5〜10%の精度向上を達成
1. Agentic Visionを支える「思考・実行・観察」のループ
Agentic Visionは、単に画像を見るだけでなく、以下のサイクルを回すことで正確な理解に到達する。
- 思考 (Think): ユーザーの質問に対し、画像のどこをどう調べればよいかという「調査計画」を立てる。
- 実行 (Act): Pythonコードを生成・実行し、画像を拡大(クロップ)したり、回転させたり、計算を行ったりして、必要な情報を自ら取りに行く。
- 観察 (Observe): 加工・拡大した新しい画像を自分自身の「記憶(コンテキスト)」に追加し、より詳細な情報をもとに最終的な結論を出す。
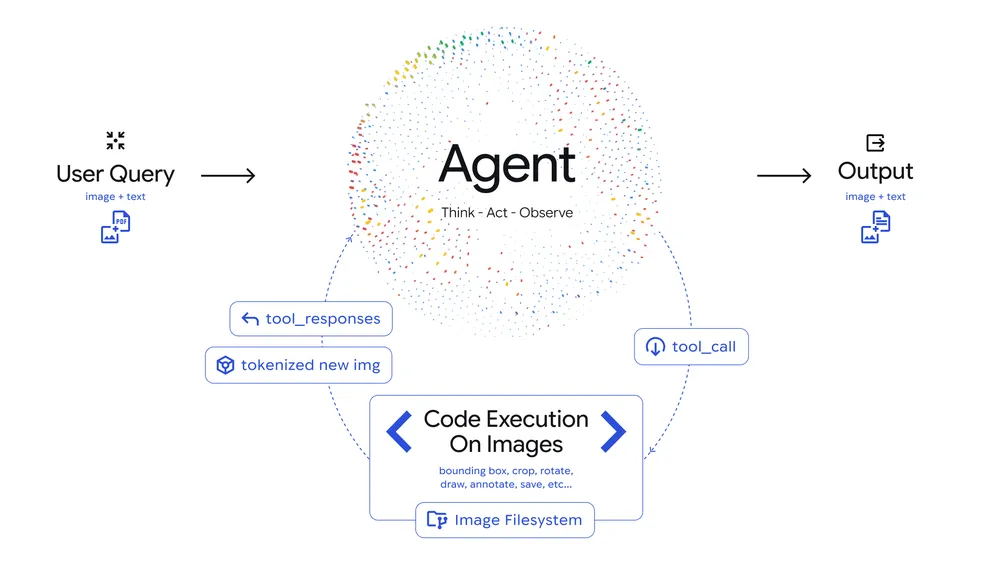
公式ブログより引用。Agentic Visionは、思考→実行→観察を繰り返しながら画像を理解する
2. 具体的に何ができるようになるのか
この「能動的な調査」が可能にすることで、以下の3つのような実用的な活用が始まっている。
- 図面の精密な検証(ズームと検査)
建築図面のような巨大で高精細なデータにおいて、AIは自動的に「屋根の端」や「建物の接合部」などをクロップして拡大検査する。これにより、一見では見落とすような微細な不備も、確実な視覚的証拠に基づいて指摘できるようになった。 - ミスのないカウント(画像への注釈付け)
例えば「指の数」を数える際、AIはただ眺めるのではなく、Pythonを使って画像上の指一本一本に「枠」と「番号」を書き込みながら数える。この「視覚的な下書き(スクラッチパッド)」を使うことで、数え間違いというAI特有のミスを劇的に減らしている。 - 正確なグラフ化(視覚的な算術とプロット)
複雑な表データを読み取る際、AIは「おそらくこうだろう」と推測するのをやめ、コードを実行してデータを正規化し、正確なグラフを自ら生成して回答する。これにより、数字の読み間違いによる「幻覚(ハルシネーション)」を排除している。
3. 今後の展望
Agentic Visionはまだ進化の入り口に過ぎない。現在は「拡大」などの動作が中心だが、今後は「逆画像検索」などの外部ツールとの連携や、他のモデルサイズへの展開も予定されている。AIが「ただ見る」存在から、自ら「調査し、検証する」エージェントへと変わる、大きな一歩と言えるだろう。
詳細はIntroducing Agentic Vision in Gemini 3 Flashを参照していただきたい。