
1月24日、OpenAIが「Unrolling the Codex agent loop」と題した記事を公開した。この記事では、Codexの基盤となるエージェント・ループの仕組みと設計思想について詳しく紹介されている。

以下に、その内容を紹介する。
エージェント・ループ:自律性のエンジン
AIエージェントの中核には「 エージェント・ループ 」と呼ばれる論理サイクルが存在する。これは、ユーザー、モデル、そしてモデルが実行するツール間の相互作用をオーケストレートする仕組みだ。
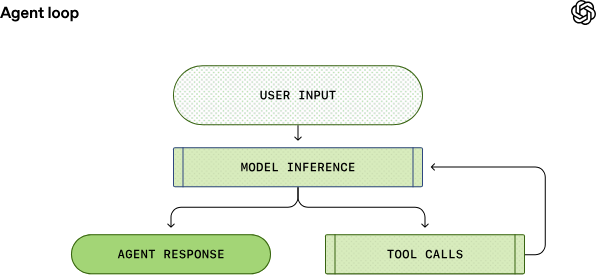
このサイクルは、モデルが最終的な回答を出すまで、あるいはユーザーへの確認が必要になるまで繰り返される。エージェントは単にテキストを生成するだけでなく、ローカル環境でシェルコマンドを実行するなどの「行動」を伴うため、その出力はアシスタント・メッセージと環境の変化(コードの書き換え等)の両方に及ぶ。
エンジニアが直面する3つの設計課題
原文は非常に詳細かつ長大な技術解説だが、本稿では特にエンジニアにとって洞察に富む「3つの課題」に絞ってピックアップする。
1. プロンプトの肥大化によるコストと遅延の増大
エージェントは過去の履歴をすべてプロンプトに含めて送信するため、会話が進むほどデータ量は雪だるま式に増えていく。これに対する解が、OpenAIのAPIサーバー側で提供されている「プロンプト・キャッシュ」の最大活用である。
プロンプト・キャッシュとは、以前のリクエストで送信したプロンプトの「プレフィックス(前方部分)」をサーバー側でキャッシュし、再利用する仕組みだ。これにより、同じ文章を何度も再計算する必要がなくなり、レスポンス速度とコストが劇的に改善される。
- 「先頭一致」の重要性: 例えば、「A(共通指示)+B(履歴)」というプロンプトを送り、次に「A+B+C(最新発言)」を送った場合、先頭の「A+B」が一致するためキャッシュが効く。しかし、途中で「Aを少し書き換える」と、それ以降のBもCもすべてキャッシュが無効化されてしまう。
- Codexの工夫: ディレクトリ変更などの「状態変化」が起きても、既存のメッセージを編集するのではなく、新しいメッセージとして末尾に「追記」することで、プロンプトの先頭部分を常に不変に保ち、キャッシュヒット率を最大化している。
2. 限られた「コンテキスト窓」への対応
LLMには一度に扱えるトークン数(コンテキスト窓)に上限がある。大規模な開発タスクでは、この上限をいかに超えずに「知能」を維持するかが課題となる。
- 解決策: コンテキストが閾値を超えた際、履歴を単純に削除するのではなく「コンパクション(圧縮)」を行う。それまでの複雑な試行錯誤やツール実行結果をモデル自身に要約させ、その要約を「新しい起点」としてプロンプトを再構成することで、重要な文脈を維持したまま会話を継続させる。
3. ステートレスな通信と機密保持の両立
セキュリティ要件(Zero Data Retention)により、サーバー側にデータを残せない場合、サーバーは過去の対話を記憶できない。しかし、記憶がなければ複雑なエージェント・ループは維持できない。
- 解決策: Codexは「暗号化された推論内容」をクライアント側で保持し、リクエストのたびにサーバーへ送り返す手法を取る。これにより、サーバー側はデータを永続化せず、かつ前回の思考プロセスを正確に再開できるという、セキュリティと機能性のトレードオフを解消している。
結びに代えて
本稿では原文の膨大な情報の中から、特にエージェント設計のエッセンスとなる部分を抽出して紹介した。Codexの設計は、LLMの推論能力という抽象的な力を、いかに効率的かつ安全に実務へ変換するかという問いに対する、OpenAIの現在の回答と言える。
さらに詳細な実装仕様や、オープンソース化されているコードとの対応関係、パフォーマンス計測の結果などについては、ぜひ原文を参照していただきたい。
詳細はUnrolling the Codex agent loopを参照していただきたい。