10月9日、Miguel Grinberg氏が「Python 3.14 Is Here. How Fast Is It?」と題したブログ記事を公開した。この記事では、最新のPython 3.14の実行速度を、過去バージョンやPyPy、Node.js、Rust、さらにCPythonのJIT版・フリースレッディング(GIL無効)版と比較する形で詳しく紹介している。以下に、その内容を紹介する。
ベンチマーク概要
今回のベンチマークは、以下の5つの軸で構成される。
- 6つのPythonバージョン(3.9〜3.14)に加え、PyPyの最近版、Node.js 24、Rust 1.90
- 3種のインタプリタ(標準/JIT[3.13+]/フリースレッディング[3.13+])
- 2種類のスクリプト(再帰多用の
fibo.py/反復主体のbubble.py) - 2つのスレッドモード(シングルスレッド/4スレッド)
- 2台のマシン(Ubuntu 24.04のIntel i5搭載Framework Laptop、macOS SequoiaのM2 Mac)
比較のため、fibo.pyとbubble.pyはそれぞれJavaScript(Node)とRustにも移植されている。
テストスクリプト(抜粋)
再帰主体のフィボナッチ計算と、反復主体のバブルソートを用いている。どちらも「最速化」を狙ったコードではなく、インタプリタ差の比較用サンプルである。
# fibo.py
def fibo(n):
if n <= 1:
return n
else:
return fibo(n-1) + fibo(n-2)
# bubble.py
def bubble(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
ベンチマークフレームワークは各テストを3回実行し平均を採用する。完全なスクリプトは著者のGitHubリポジトリで公開されている。
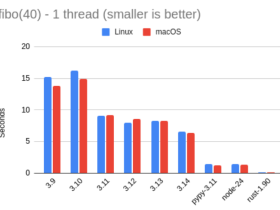
ベンチマーク#1:フィボナッチ(シングルスレッド)
40番目のフィボナッチ数fibo(40)の実行時間(秒)。右端の「vs. 3.14」は3.14に対する相対速度である。
| fibo 1 thread | Linux | macOS | vs. 3.14 |
|---|---|---|---|
| 3.9 | 15.21 | 13.81 | 0.45x |
| 3.10 | 16.24 | 14.97 | 0.42x |
| 3.11 | 9.11 | 9.23 | 0.71x |
| 3.12 | 8.01 | 8.54 | 0.78x |
| 3.13 | 8.26 | 8.24 | 0.79x |
| 3.14 | 6.59 | 6.39 | -- |
| Pypy 3.11 | 1.39 | 1.24 | 4.93x |
| Node 24 | 1.38 | 1.28 | 4.88x |
| Rust 1.90 | 0.08 | 0.10 | 69.82x |

所見として、3.14は3.13比で約27%高速化している。一方、PyPyは依然として突出して速く、今回はNode.jsよりわずかに速い。Rustは桁違いに高速である。
インタプリタ別(標準/JIT/FT)
| fibo 1 thread | Linux | macOS | vs. 3.14 |
|---|---|---|---|
| 3.13 | 8.26 | 8.24 | 0.79x |
| 3.13 JIT | 8.26 | 8.28 | 0.78x |
| 3.13 FT | 12.40 | 12.40 | 0.52x |
| 3.14 | 6.59 | 6.39 | -- |
| 3.14 JIT | 6.59 | 6.37 | 1.00x |
| 3.14 FT | 7.05 | 7.27 | 0.91x |

JITはこの再帰的ワークロードでは有意な改善を示さなかった。FT(フリースレッディング)は単体スレッドでは依然として標準より遅いが、3.14ではその差が縮小している。
ベンチマーク#2:バブルソート(シングルスレッド)
1万要素の乱数配列をバブルソートする。
| bubble 1 thread | Linux | macOS | vs. 3.14 |
|---|---|---|---|
| 3.9 | 3.77 | 3.29 | 0.60x |
| 3.10 | 4.01 | 3.38 | 0.57x |
| 3.11 | 2.48 | 2.15 | 0.91x |
| 3.12 | 2.69 | 2.46 | 0.82x |
| 3.13 | 2.82 | 2.61 | 0.78x |
| 3.14 | 2.18 | 2.05 | -- |
| Pypy 3.11 | 0.10 | 0.14 | 18.14x |
| Node 24 | 0.43 | 0.21 | 6.64x |
| Rust 1.90 | 0.04 | 0.07 | 36.15x |

3.14はCPython中で最速だが、フィボナッチほどの差ではない。3.11が意外と健闘し、3.12〜3.13でやや後退しているのも昨年同様の傾向である。PyPyはここでも圧倒的である。
インタプリタ別(標準/JIT/FT)
| bubble 1 thread | Linux | macOS | vs. 3.14 |
|---|---|---|---|
| 3.13 | 2.82 | 2.61 | 0.78x |
| 3.13 JIT | 2.59 | 2.44 | 0.84x |
| 3.13 FT | 4.13 | 3.75 | 0.54x |
| 3.14 | 2.18 | 2.05 | -- |
| 3.14 JIT | 2.03 | 2.32 | 0.97x |
| 3.14 FT | 2.66 | 2.28 | 0.86x |

LinuxではJITがわずかに有利な場面もあるが、macOSの3.14ではむしろ遅くなるケースがあるなど効果は限定的である。FTは単体スレッドではやはり不利だが、差は3.13より縮んでいる。
ベンチマーク#3:フィボナッチ(マルチスレッド)
fibo(40)を4スレッドで並列実行(各スレッド独立)。GILの影響を見るため、NodeやRustの多言語比較は行っていない。
| fibo 4 threads | Linux | macOS | vs. 3.14 |
|---|---|---|---|
| 3.9 | 67.87 | 57.51 | 0.46x |
| 3.10 | 72.42 | 61.57 | 0.43x |
| 3.11 | 45.83 | 36.98 | 0.70x |
| 3.12 | 36.22 | 34.13 | 0.82x |
| 3.13 | 37.20 | 33.53 | 0.81x |
| 3.14 | 32.60 | 24.96 | -- |
| Pypy 3.11 | 7.49 | 6.84 | 4.02x |

標準インタプリタではほぼ4倍スケール相当の時間になっており、GILの制約でPythonコード自体は並列化できていないことがわかる。
インタプリタ別(標準/JIT/FT)
| fibo 4 threads | Linux | macOS | vs. 3.14 |
|---|---|---|---|
| 3.13 | 37.20 | 33.53 | 0.81x |
| 3.13 JIT | 37.48 | 33.36 | 0.81x |
| 3.13 FT | 21.14 | 15.47 | 1.57x |
| 3.14 | 32.60 | 24.96 | -- |
| 3.14 JIT | 32.58 | 24.90 | 1.00x |
| 3.14 FT | 10.80 | 7.81 | 3.09x |

ここがハイライトである。3.14のFTは標準3.14に対し約3.1倍高速で、GIL除去の効果がCPU負荷の高いマルチスレッド処理で明確に現れている。
ベンチマーク#4:バブルソート(マルチスレッド)
各スレッドが同じ乱数配列のコピー1万要素をソートする。
| bubble 4 threads | Linux | macOS | vs. 3.14 |
|---|---|---|---|
| 3.9 | 16.14 | 12.58 | 0.66x |
| 3.10 | 16.12 | 12.95 | 0.65x |
| 3.11 | 11.43 | 7.89 | 0.97x |
| 3.12 | 11.39 | 9.01 | 0.92x |
| 3.13 | 11.54 | 9.78 | 0.88x |
| 3.14 | 10.55 | 8.27 | -- |
| Pypy 3.11 | 0.54 | 0.59 | 16.65x |

Linuxでは単体スレッド×4よりやや悪化しており、オーバーヘッドの影響が示唆される。
インタプリタ別(標準/JIT/FT)
| bubble 4 threads | Linux | macOS | vs. 3.14 |
|---|---|---|---|
| 3.13 | 11.54 | 9.78 | 0.88x |
| 3.13 JIT | 10.90 | 9.19 | 0.94x |
| 3.13 FT | 9.83 | 5.05 | 1.17x |
| 3.14 | 10.55 | 8.27 | -- |
| 3.14 JIT | 10.03 | 9.26 | 0.98x |
| 3.14 FT | 6.23 | 3.02 | 2.03x |

3.14のFTは標準3.14に対して平均約2倍高速で、CPU負荷の高い並列処理で有効性が確認できる。JITはここでも効果が小さいか、環境によっては負に働く結果である。
結論(筆者の整理)
- CPython 3.14はCPython系で最速である。
- 3.14へ即時移行できない場合でも、3.11以降は3.10以前より大幅に速い。
- 3.14のJITは本テスト条件では顕著な効果を示さない。
- 3.14のフリースレッディング(GIL無効)版は、CPU負荷の高いマルチスレッド処理で標準版の2〜3倍高速になり得る。一方、GILが律速でない一般的な負荷では標準版より遅い可能性がある。
- PyPyは依然として非常に高速である。
詳細はPython 3.14 Is Here. How Fast Is It?を参照していただきたい。