
6月18日、arXivにてLe Maら研究者チームが「A Comprehensive Survey on Vector Database: Storage and Retrieval Technique, Challenge」と題した記事を公開した。この記事では、ベクターデータベース(VDB)のストレージ技術と検索アルゴリズムの最新動向、代表的な実装の比較、そして大規模言語モデル(LLM)との統合における課題と展望について詳しく紹介されている。
以下に、その内容を紹介する。
VDBの基盤技術と進化
まず、VDBの核となるストレージ層とインデックス層が歴史的にどのように発展してきたかを概観している。特に、ハイブリッドインデックス(PQ + HNSW)やディスク常駐の遅延ロード戦略など、近年のスケール要件を満たすための最適化が詳細に整理されている。計算資源と応答時間のトレードオフをどう設計するかという論点は、クラウドサービスでの実装を志向する開発者にとって有益だ。
代表的VDBソリューションの比較
論文では、Milvus、Weaviate、Qdrant、Pineconeなど主要VDBを性能指標(検索レイテンシ、挿入スループット、拡張性)、内部構造(疎密混合インデックスの有無、圧縮技法)、および典型的ユースケースで比較している。ANNアルゴリズム単独のベンチマークでは見落としがちな実運用のボトルネック──クラスタリング時の再バランスや自動階層管理──にも触れ、各プロダクトの強みと限界を客観的に示している。
VDBソリューションの比較表(論文より引用):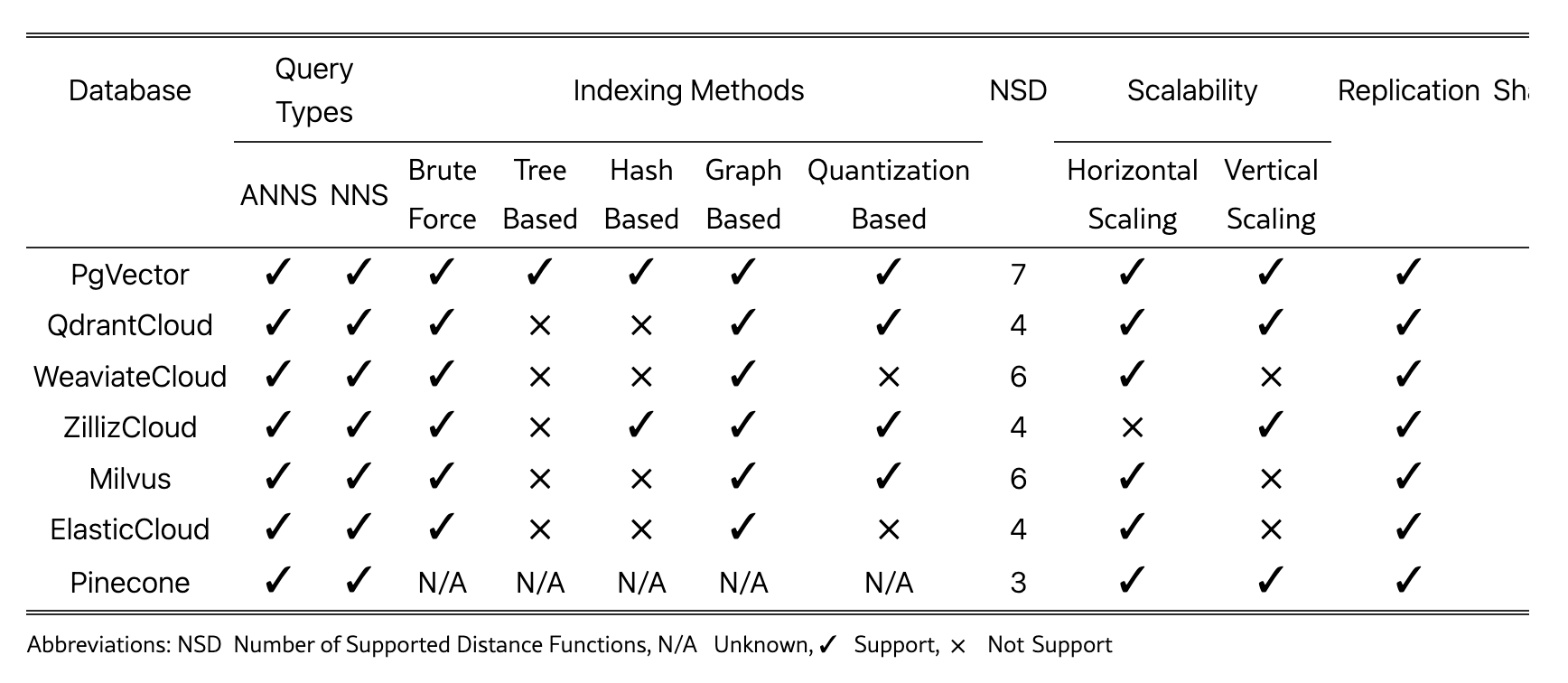
まとめ
ベクターデータベースは高次元データ活用の要として成熟期に入りつつあるが、LLMとの深い結合が始まったことで再び技術的飛躍が期待される。本稿で紹介した論文は、ストレージ構造から応用事例、そして未解決課題までを体系的に整理しており、VDBの全体像を把握する上で格好の参考資料となる。
詳細はA Comprehensive Survey on Vector Database: Storage and Retrieval Technique, Challengeを参照していただきたい。