
3月4日、海外スタートアップRivetが「SQLite-on-the-Server Is Misunderstood: Better At Hyper-Scale Than Micro-Scale」と題したブログ記事を公開した。この記事では、サーバー環境におけるSQLite活用が大規模スケールでどのように有効なのかについて詳しく紹介されている。以下に、その内容を紹介する。

Rivetは新しいオープンソースのセルフホスティング型サーバーレスプラットフォームである。最近、サーバー上でのSQLite活用に深く取り組んでおり、多くの見解が得られたという。GitHub上でも情報を公開しているので、興味があればスターをつけてほしいとのことだ。今後もSQLiteに関するさらなる情報を共有する予定だという。
近頃、サーバーサイドでのSQLite利用に関する長所と短所について、多くの議論が行われている。一般的には、小規模なホビープロジェクトや個人開発での利用が想定されがちだが、Rivetの視点では、むしろ大規模スケールでこそSQLiteが強みを発揮すると考えているようだ。
サーバー上でのSQLiteがマイクロスケールのアプリケーションで活用される背景を理解するため、まずはその小規模活用の一般的な状況を整理している。
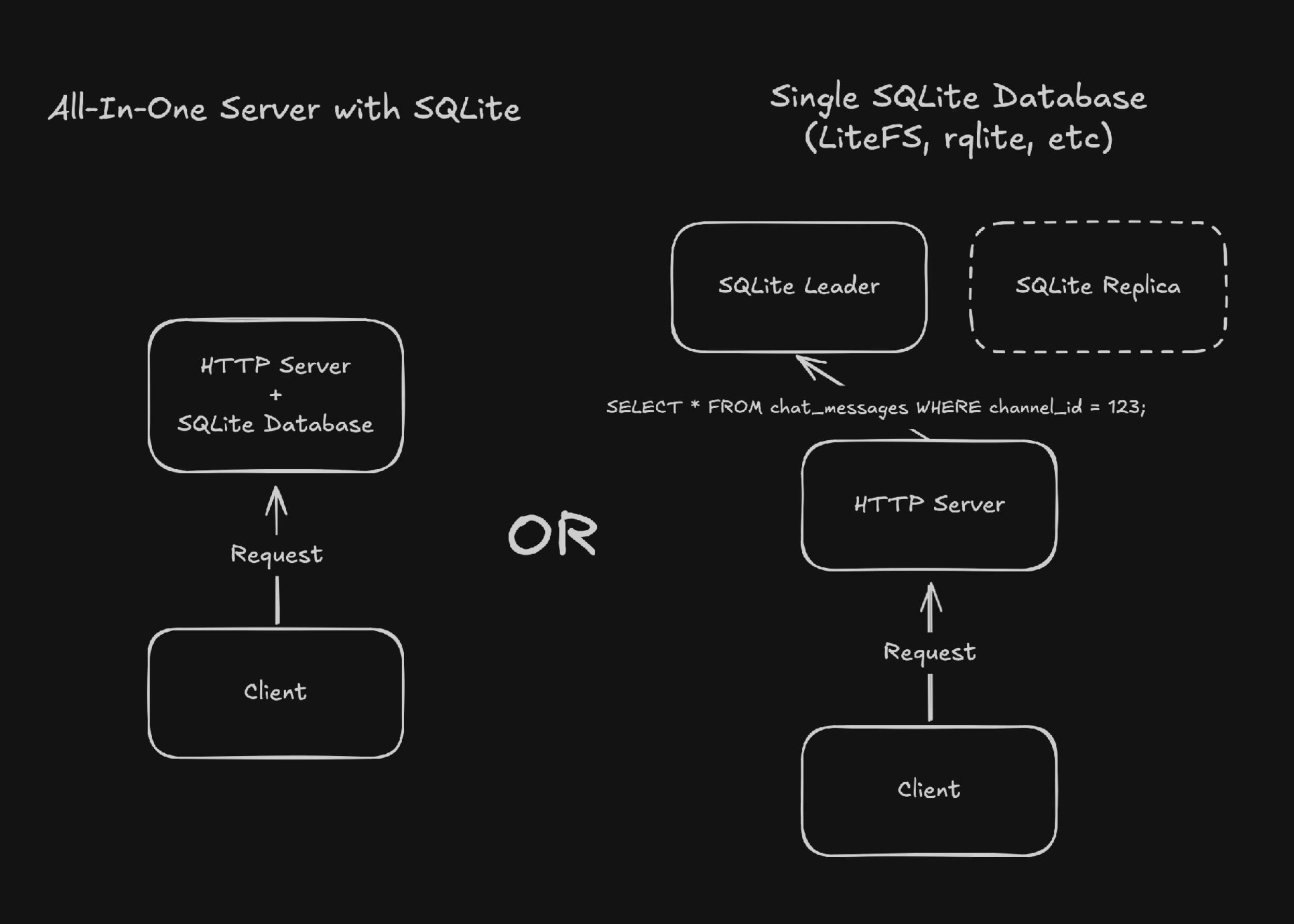
多くの開発者にとって、サーバーサイドでのSQLiteは以下の理由からシンプルでコスト効率の高い選択肢と見なされることが多い:
- 設定が容易で軽量
- 小規模アプリケーションに十分なパフォーマンス
- ホスティングコストを抑えやすい
- 運用管理のハードルが低い
これらの特性が、個人プロジェクトや軽量アプリ、プロトタイプ構築にとって魅力的に映るわけだ。また、LiteFS、Litestream、rqlite、Dqlite、Bedrockといったツールによって、マイクロスケールの環境でもSQLiteにレプリケーションや高可用性をもたせることが可能になっている。
しかし、この記事の本題は、Cloudflare Durable ObjectsやTursoといった技術を例に挙げながら、ハイパースケールにおけるSQLiteの利点を紹介する点にある。
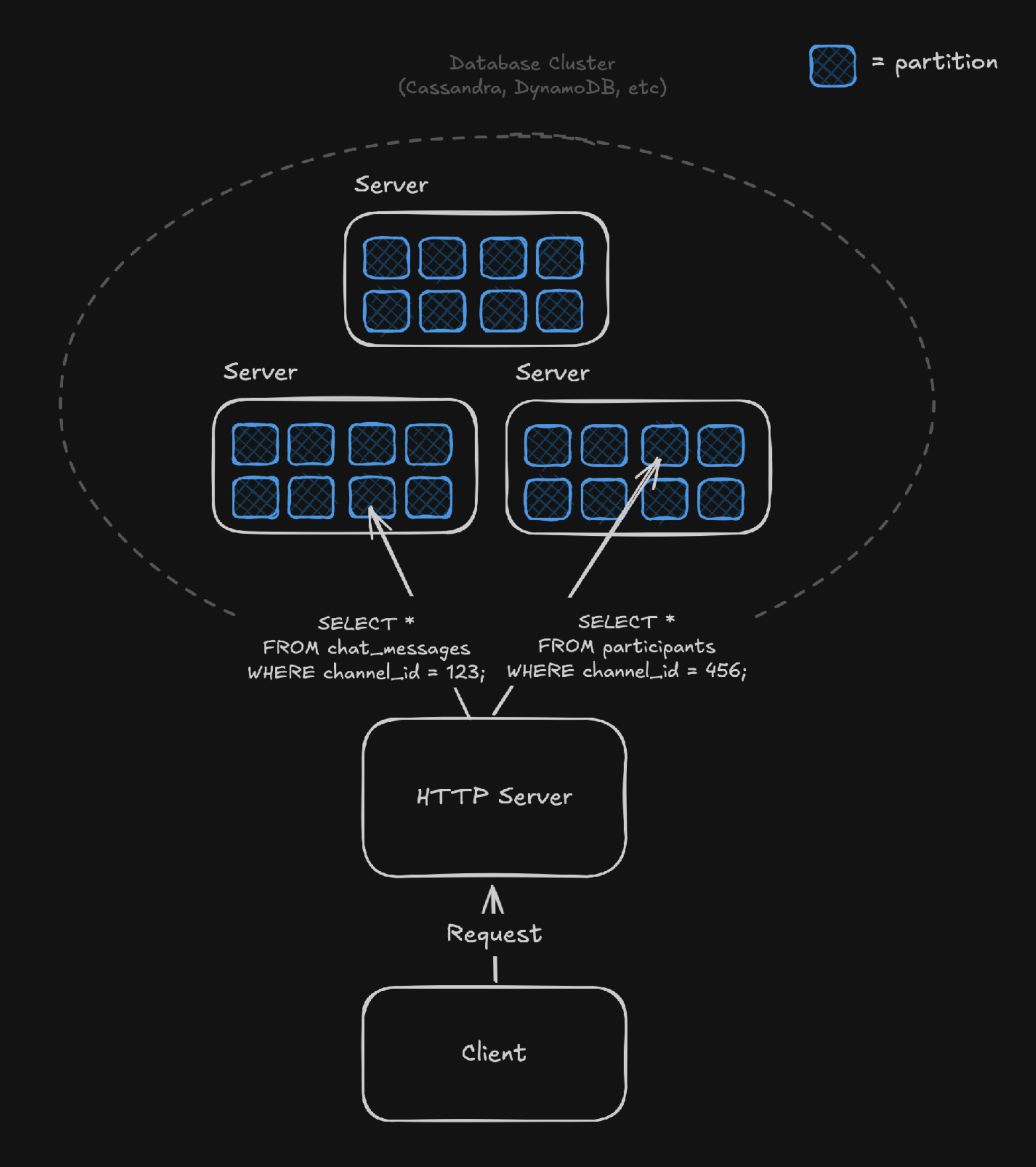
多くの大規模システムにおいては、PostgresやMySQLのスケーリングに苦慮し、CassandraやScyllaDB、DynamoDB、Vitess(MySQLのシャーディング)、Citus(Postgresのシャーディング)などのシャーディングされたデータベースを使うケースが一般的である。
これらのシステムでは、パーティションキーによって関連性の高いデータを同一パーティションに配置し、高速なバッチ読み取りや水平スケーリング、大量書き込み性能を実現している。たとえば、チャットアプリケーションをCassandraで設計する場合のテーブル例は以下のようになる:
CREATE TABLE chat_channel (
-- Partition Key: Groups all messages for a single chat in the same partition
channel_id UUID,
-- Clustering Key: Orders messages within the chat (think ORDER BY)
sent_at TIMESTAMP,
message_id UUID,
-- Row data
message TEXT,
PRIMARY KEY (channel_id, sent_at, message_id)
) WITH CLUSTERING ORDER BY (sent_at ASC, message_id ASC);
このデータを取得する際には、次のようなクエリを書くことになる:
SELECT * FROM user_chat WHERE channel_id = ? ORDER BY sent_at ASC, message_id ASC;
シャーディングによる大規模な分散データベースは、多くの大手企業で広く採用されているが、その一方で以下のような課題も存在すると言われている:
- スキーマが固定的で、クエリパターンと厳密に対応させる必要がある
- インデックスやリレーションを追加するにはライブシステムで大掛かりな対応が必要になる
- パーティションをまたいだACID保証が難しく、複雑な二段階コミットなどを使用するか、ある程度の整合性の甘さを受け入れる設計が必要になる
- 分割されているテーブル間の強整合性が弱く、トランザクションの中断や変更の伝播失敗などによりデータの不整合が起きやすい
Cloudflare Durable ObjectsやTursoの登場により、SQLiteが将来的にハイパースケールアプリケーションの構築方法を変えるかもしれないと期待されている。これらのサービスには次のような特徴がある:
- 動的なスケーリング: エンティティごとにデータベースを即時に用意でき、インフラ管理が簡素化する
- 安価で無数に作成可能: パーティションと同様にSQLiteデータベースを無数に作成でき、管理コストも低い
- グローバル分散: データベースをユーザーに近い場所に配置し、レイテンシを削減できる
- レプリケーションと耐障害性を標準で実装: 従来のSQLiteにはなかったマルチリージョンへの複製機能がある
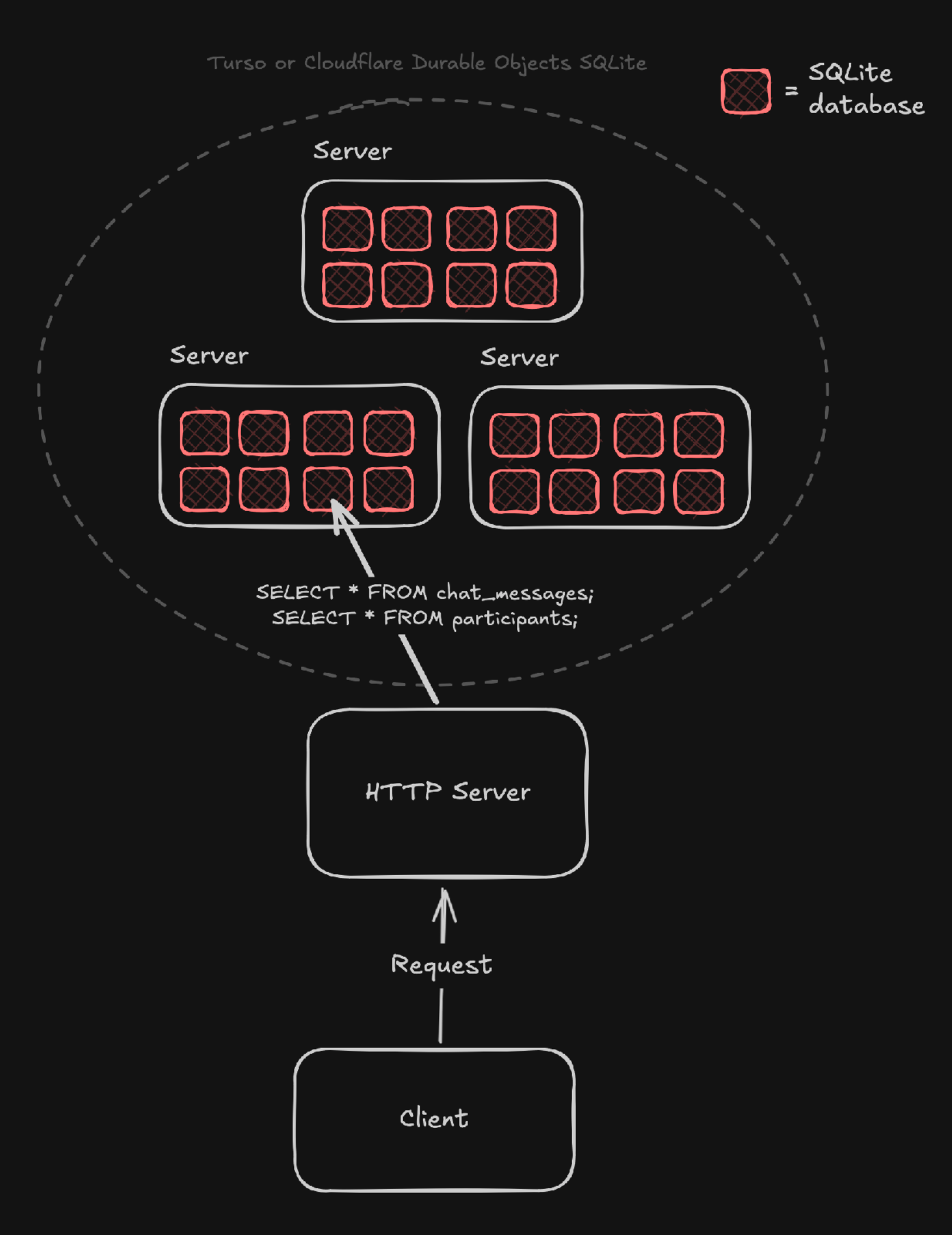
特にCloudflare Durable ObjectsやTursoを利用することで、 エンティティごとに個別のSQLiteデータベースを割り当てる 手法が可能になる。これは従来のパーティションキーの代わりに「1エンティティ=1データベース」という設計を取るイメージに近い。たとえば、チャットアプリケーションであれば、チャットチャンネルごとにデータベースを作成する形だ。以下はサンプルスキーマの例:
-- このデータベースは単一のチャネルに紐づくため、channel_id をカラムとして持たない。
-- channel_id は Durable Object を定義するとき(CHAT_DO.idFromName(channelId))に指定することで
-- それぞれ独立したデータベースとなる想定。
CREATE TABLE messages (
id INTEGER PRIMARY KEY,
sent_at TIMESTAMP,
sender_id UUID,
message TEXT
);
CREATE INDEX ON messages (sent_at ASC);
CREATE TABLE participants (
user_id UUID PRIMARY KEY,
joined_at TIMESTAMP
);
そして、Cloudflare Durable ObjectsやTursoからは次のようにクエリを実行できる:
// このDurable Objectは1つのパーティションを表す
// 完全に独立したSQLiteデータベースを内部にもつ
export class ChatChannel extends DurableObject {
async getMessages() {
// クエリ実行
let result = this.ctx.storage.sql.exec('SELECT * FROM messages ORDER BY sent_at ASC').one();
return result;
}
}
function getMessages(channelId: string) {
// channelIdをデータベースパーティションに対応させる
const id = env.CHAT_CHANNEL_DURABLE_OBJECT.idFromName(channelId);
const channelDurableObject = c.env.CHAT_CHANNEL_DURABLE_OBJECT.get(id);
// クエリを実行
return await channelDurableObject.getMessages();
}
このようなモデルを採用することで、次のような利点があると記事では主張している:
- ローカルACIDトランザクション: パーティションをまたがないために複雑な分散トランザクションを避けられる
- I/Oの効率化: 同じデータベース内で複雑なクエリを完結でき、高いパフォーマンスが期待できる
- SQLite拡張の利用: FTS5やJSON1、R*Tree、SpatiaLiteなど、豊富なエクステンションを活用できる
- SQLマイグレーションの柔軟性: DrizzleやPrismaなどの既存ツールが利用可能で、スキーマ変更もSQLベースで対応できる
- 遅延マイグレーション: 大規模システムでのスキーマ変更は大変だが、SQLiteならデータベースを開いたタイミングでマイグレーションを実行することも可能である
もっとも、大規模スケールでのSQLiteには以下のような課題も残されていると記事では指摘している:
- オープンソースかつセルフホスト可能なソリューションが少ない
- 複数のデータベースをまたいだクエリが標準ではサポートされず、データレイクなど別途分析基盤が必要になる
- SQLブラウザやETLパイプライン、監視、バックアップといった周辺ツールがまだ不十分
- 通信プロトコルが標準化されておらず、PostgreSQLやMySQLのように各クラウドで統一されたワイヤプロトコルが存在しない
- CassandraやDynamoDBのようにハイパースケール運用の実績(事例)がまだ少ない
以上のように、サーバーサイドでのSQLiteは小規模用途だけでなく、大規模分散システムにおいても従来のパーティショニングDBを置き換えられる可能性がある、と記事は主張している。TursoやDurable ObjectsのようにパーティションごとにSQLiteを割り当てるアプローチを活用することで、豊富なSQL機能やACID特性を保ちながら、高い可用性と運用上の利便性を得られる可能性があるという。
詳細はSQLite-on-the-Server Is Misunderstood: Better At Hyper-Scale Than Micro-Scaleを参照していただきたい。