
1月16日、Matthias Endler氏のブログで「Prototyping in Rust」と題した記事が公開され、海外で大きな注目を集めている。この記事では、Rustによるプロトタイピングに関して詳しく考察されている。

以下に、その内容を簡単に紹介する。
プログラミングは反復的なプロセスである。最初から完璧な解決策を生み出せれば理想的だが、実際にはうまくいかないことが多い。
優れたプログラムは、しばしば素早い試作品(プロトタイプ)から始まり、それが進化して本番コードになることもあれば、プロトタイプのまま停滞してしまうものもある。ゲームやCLIツール、あるいはライブラリのAPI設計などにおいても、デザインを決める前に最適なアプローチを見つけるためにプロトタイピングは非常に有用である。より慣用的(イディオマティック)なコードの背後にあるパターンを明らかにするのにも役立つ。
Rustは型が明示的というイメージが強い一方で、アイデアを素早く形にする際にも意外と使いやすい言語である。一般的に言われるほど「プロトタイピングに不向き」ではない。Rustの高度な機能をすべて使いこなさなくても、生産的に開発できる方法はいくらでもある。シンプルなパターンに集中し、Rustの優れたツールチェーンを活用すれば、Rust初心者でも素早くアイデアを形にできる。
なぜ「Rustはプロトタイピングに向いていない」と思われがちなのか
一般には次のように言われることが多い。
「プログラムを書き始めるときは、何を作りたいか明確ではなく、途中で考えがよく変わる。Rustの型システムはとても厳しいので、設計変更をするときに壁にぶつかる。さらに、他の言語に比べてコンパイルを通すために時間がかかるので、フィードバックループが遅い。」
Rustに十分慣れていない開発者が、厳格な型システムや所有権(borrow checker)に阻まれると、こうした印象を抱きがちだ。Rustでは“0%か100%か”しかなく、中間がないと思い込んでしまう人もいる。
以下のような誤解が典型的だ。
- 「メモリ安全性とプロトタイピングは両立しない。」
- 「所有権と借用がプロトタイピングの楽しさを奪う。」
- 「最初からすべての詳細を正確に決めなければならない。」
- 「Rustでは常にエラー処理をしなければならない。」
これらはすべて真実ではない(よくある誤解の一例でもある)。実際は、Rustを使ってプロトタイピングする際にこれらの落とし穴を回避しつつ、多くのメリットを享受できる。
他の言語でのプロトタイピングが抱える問題
「Pythonのようなスクリプト言語があるのに、なぜわざわざRustを使うのか?」という疑問はもっともだ。Pythonはフィードバックループが速く、動的型付けはプロトタイプ作成を容易にする。さらにあとからRustへ書き換えればいい、という考え方もあるだろう。
確かにPythonは優れたプロトタイピング言語だ。しかし、筆者(元記事執筆者)はPython開発を長年行いながら、プロトタイプ段階を超えたあたりからPythonに限界を感じてきたという。型に関連するバグが深い場所で発生するようになり、結果として「より堅牢な言語に移行したい」と考えるタイミングが早く訪れてしまう。
しかし、言語を切り替えるのは大きな負担だ。とくにプロジェクト途中での切り替えは、しばらく2つのコードベースを同時に維持しなければならない可能性があるし、RustとPythonでは慣用的な書き方が異なるためソフトウェアアーキテクチャを再考しなければならない。さらに、ビルドシステムやテストフレームワーク、デプロイ環境もすべて切り替える必要がある。大がかりな作業だ。
では最初からプロトタイプも本番も同じ言語で書くことができればどうだろうか?
Rustがプロトタイピングに向いている理由
プロジェクトのライフサイクルを通して同じ言語を使えると、生産性が高まる。Rustはアイデア検証用のProof of Conceptから本番デプロイまでをカバーできるため、コストのかかるコンテキストスイッチやコードの書き換えを大幅に削減できる。Rustの強力な型システムは早期に設計上の問題を発見できるうえ、必要なら実用的な“逃げ道”も提供してくれる。結果的にプロトタイプから本番コードへ自然に進化させられるのだ。しかも最初のバージョンでもすでにプロダクションレベルの安定性を備えていることが多い。
Discord社がGoからRustへ移行した事例でも、Rustのパフォーマンスの高さや最適化のしやすさが証明されている(Why Discord is switching from Go to Rust参照)。
「Rust版を書いたときはごく基本的な最適化しか考慮していなかったが、それでもGoの高度に最適化された実装を上回ることができた。これは、Rustで効率的なプログラムを書くのがいかに容易であるかを示す大きな証拠だ。」
Rustでプロトタイピングする理想的なワークフロー
Rustを最初に使えば、型システムや強力なリンタ(Clippy)などにより堅牢なコードベースを手に入れられる。しかも、プロトタイプが完成したあとに言語を切り替える必要がないので、コンテキストスイッチやフレームワークの切り替えをする手間が省ける。
一方で、Pythonの以下のような特性は学ぶ価値がある。
- フィードバックループが速い
- 思いつきで仕様を変えやすい
- (細部のエッジケースを無視すれば) シンプルで扱いやすい
- ボイラープレート(定型コード)が少ない
- 実験やリファクタリングが容易
- 数行ですぐに役立つ機能が作れる
- コンパイルステップが存在しない
Rustであっても、この体験にできるだけ近づけるよう工夫すれば、アイデアをすばやく検証しつつ、Rustが本来持っている原則を損なわずに進められる。コンパイルがあるのは事実だが、小規模プロジェクトならコンパイル時間はそれほど気にならないはずだ。
以下では具体的なRustでのプロトタイピングテクニックを紹介する。
RustでのプロトタイピングTIPS
シンプルな型を使う
型システムを避けることはできないが、むしろそれを強みに変えられる。まずはi32やString、Vecのように扱いやすい所有型(owned type)を積極的に使うとよい。必要になったときにより複雑な型へ移行すればいいので、最初の段階では簡単な型に頼るのが得策だ。逆の順番、つまり複雑な型から単純な型への移行ははるかに難しい。
プロトタイプから本番へ移行する際によくある型の切り替えは以下のとおりだ。
| Prototype | Production | When to switch |
|---|---|---|
| String | &str | アロケーションを避けたい場合や、文字列のライフタイムを明確に管理したい場合 |
| Vec<T> | &[T] | 所有されたベクタを頻繁にクローンするコストを抑えたい場合や、ヒープを使いたくない場合 |
| Box<T> | &T または &mut T | Boxのヒープ確保がボトルネックになる場合や、所有権ではなく参照で済ませたい場合 |
| Rc<T> | &T | 参照カウントのオーバーヘッドが高くなったり、可変性(mutability)が必要な場合 |
| Arc<Mutex<T>> | &mut T | 排他的アクセスが保証できてスレッドセーフである必要がなくなった場合 |
こうした所有型はほとんどの所有権・ライフタイム問題を回避できるが、その代わりメモリをヒープに確保する。一方で、後から必要に応じて最適化できるので、最初のうちはパフォーマンスをあまり気にしなくてもいい。
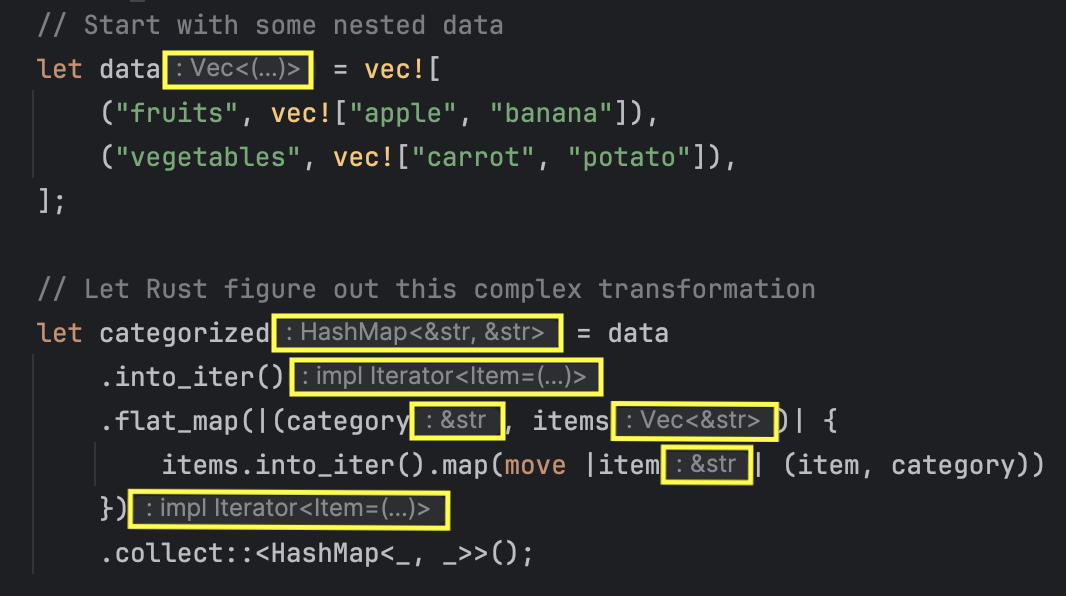
型推論を活用する
Rustは静的で強い型付けの言語だが、型推論のおかげで常にすべての型を明示しなくても済む。以下のように、型はコンテキストから推論される。
let x = 42;
let y = "hello";
let z = vec![];
最初に素早くコードを書く段階では型を省略し、後から必要に応じて追記できる。複雑な型にも対応できるので、大規模プロジェクトでもこの方法は有効だ。
let x: /* 省略 */ = vec![];
let y: /* 省略 */ = vec![];
let z = x.into_iter().chain(/* 省略 */);
より複雑な例としては以下のようなものがある。
use std::collections::HashMap;
let data = vec![];
let categorized = data
.into_iter()
.flat_map(/* 省略 */)
.collect::<HashMap<_, _>>();
println!("{:?}", categorized);
このcategorizedの型を頭の中でイメージするのは難しいが、Rustはちゃんと推論してくれる。
Rust Playgroundを使う
Rust Playgroundは、コードを素早く試すのに便利だ。オートコンプリートなどの機能はないが、ブラウザ上でRustコードを実行でき、URLを共有すれば他人と簡単にコードをやりとりできる。とりあえず関数や型のスケッチをするにはうってつけである。
unwrapを積極的に使う
プロトタイプの段階ではunwrapを遠慮なく使うのが手軽だ。unwrapを使った箇所は「後からエラー処理を入れる必要がある」という目印になる。仕上げの段階でunwrapを探索して適切なエラー処理に置き換えればよい。Clippyにはunwrapを使った場所を指摘するリントも存在する。
use std::fs;
use std::path::PathBuf;
fn load_files(paths: &[PathBuf]) {
let data = fs::read_to_string(&paths[0]).unwrap();
// ...
}
上記のようにunwrapを使うと、Rustエンジニアには目立って見えるが、それが逆に「あとの修正ポイント」を明確にするメリットになる。たとえばJavaScriptのように例外がいつどこで投げられるかわからない世界より、はるかに追跡が容易だ。Rustなら、まずはハッピーパスに集中でき、仕上げの段階でエラー処理をきちんと導入しても遅くはない。
IDEを活用する
Rustには強力なIDEサポートがある。コード補完やリファクタリング支援があると開発フローが途切れにくくなる。動的型付け言語と比べると、型システムがIDEに豊富な情報を与えてくれるためオートコンプリートが非常に優秀だ。
また前述した型推論を可視化するために、エディタのインレイヒント機能をオンにすると便利だ。変数や戻り値の推論結果がその場で表示されるので、型の把握がスムーズになる。
baconでフィードバックループを高速化する
Rustはスクリプト言語ではないためコンパイルステップがある。しかし、小規模のプロトタイプならコンパイル時間はさほど大きくない。とはいえ変更ごとに手動でcargo checkするのは面倒なので、rust-analyzerと組み合わせたり、baconのような外部ツールを使って自動再コンパイルさせるとよい。baconを使えば、ファイルを変更するたびにコンパイル&実行結果を即座に確認できる。
bacon watch
実行すると、カラフルな出力とともに自動で再コンパイルしてくれる。
なお、以前は同様の目的でcargo-watchがよく使われていたが、現在は非推奨となっている。
cargo-scriptの活用
実はcargoを使ってスクリプトを実行することもできる。例えば以下のような内容をscript.rsというファイルに書く。
#!/usr/bin/env cargo +nightly -Zscript
fn main() {
println!("Hello from cargo script!");
}
chmod +x script.rsで実行可能ビットを付ければ、./script.rsで直接実行できる。ちょっとしたアイデアを試すためにプロジェクトを作成する手間なく動かせるのは便利だ。依存クレートを指定することもできる。
現時点ではcargo-scriptはnightly版の機能だが、いずれ安定版(stable Rust)でも利用できるようになる予定だ。RFCを参照。
パフォーマンスを気にしすぎない
Rustでわざと遅いコードを書くほうが難しいくらい、Rustはデフォルトで高速に動作する。プロトタイプの段階では、できるだけコードをシンプルにしておき、最適化は後回しにしたほうがよい。
「C/C++経験者が早すぎる段階で最適化しようとして借用チェッカーの複雑さに苦しむ」ことはよくある。Rustでは型の安全性を保ったまま高パフォーマンスが得られるので、過度な最適化はかえってメンテナンス性を損ない、実際にはそれほど速くもならない場合がある。
println!とdbg!でデバッグする
プロトタイプ作成時はプリントデバッグが気軽でよい。Rustにはprintln!のほかにdbg!マクロがあり、呼び出し元のファイル名や行番号、式そのものと評価結果を出力してくれるので便利だ。デバッグビルド時のみ有効なので、本番リリース時のパフォーマンスには影響しない。
再帰関数やイテレーションの途中経過を出力する際などに威力を発揮する。
fn factorial(n: u32) -> u32 {
dbg!(n <= 1);
if n <= 1 {
dbg!(1)
} else {
dbg!(n * factorial(n - 1))
}
}
出力例を見ればコードの流れが把握しやすい。
型を活かしたデザイン
Rustの型システムは、よく考えられたデザインを強制するための強力なツールでもある。プロトタイプの段階では「しっくりくる」型を探すことに思い切り時間を使うとよい。最初から最適解が見えるわけではないので、とりあえず実装し、要件が変われば型をリファクタリングする流れを繰り返す。
たとえば、学生のコース登録システムを考えてみよう。はじめは以下のようにシンプルに書くかもしれない。
struct Enrollment {
student_id: u64,
course_id: u64,
enrolled: bool,
}
しかし、定員オーバーになった場合はウェイトリストに入れるという仕様が後から加わったとする。安易にフラグを追加すると、enrolledとwaitlistedが同時にtrueになってしまう可能性がある。
struct Enrollment {
student_id: u64,
course_id: u64,
enrolled: bool,
waitlisted: bool,
}
Rustの列挙型(enum)を利用すれば無効な状態を型レベルで排除できる。
enum Enrollment {
Active {
student_id: u64,
course_id: u64,
},
Waitlisted {
student_id: u64,
course_id: u64,
position: u32,
},
}
これで「ウェイトリストにいるのに登録もされている」という矛盾した状態は型で表現できなくなる。動的型言語で同様のチェックをしようとすると、実行時に型を判定して例外処理するなど、より煩雑になりがちだ。
このように、データモデルを詰める過程こそがプロトタイピングの肝だ。最終的なコード以上に、問題領域への深い理解が得られることにこそ価値がある。
todo!マクロ
プロトタイプでは、すぐに実装詳細を決められない部分があるのは当然だ。Rustでは todo! マクロを使って「未実装」であることを明示できる。
fn main() {
let data = load_data();
let processed = process_data(data);
output_result(processed);
}
fn load_data() -> Vec<u8> {
todo!("Not implemented yet");
}
fn process_data(_: Vec<u8>) -> String {
todo!("Not implemented yet");
}
fn output_result(_: String) {
todo!("Not implemented yet");
}
上記のように、必要な関数やモジュールの形だけ定義しておき、あとから実際の中身を徐々に作り込めばよい。Rustの場合、型さえ整合していればコンパイルを通せるため、最初からすべて完成させなくてもよいのだ。
ジェネリクスを避ける
最初からジェネリクス(総称型)を使うと、かえってコードが複雑になる場合が多い。複数の箇所で同じ機能が必要になったとき、共通化を急がず、まずは重複を容認してコピー&ペーストしておくほうがよい。目的がはっきりしていない抽象化はかえって邪魔になる。
例えば以下のようなコードは見た目に凝りすぎだ。
fn process<T: Into<String>>(input: T) -> String {
let s: String = input.into();
s
}
最初は素直にStringを使い、
fn process(input: String) -> String {
input
}
必要になったらジェネリクスを導入する、くらいでちょうどよい。また、所有権や参照の扱いが面倒に感じるなら、最初は.clone()してしまうのも手だ。あとで最適化を検討すればよい。
ライフタイムを避ける
Rustの所有権システムに慣れていない段階で、参照やライフタイムで足止めを食らうと、開発の流れを乱してしまう。プロトタイプではできるだけStringやVecのような所有型を使い、必要ならclone()を多用することで、難しい所有権の問題を後回しにできる。
fn make_greeting(name: &str) -> String {
format!("Hello, {}!", name)
}
fn main() {
let user_name = "Alice".to_owned();
// あとで必要になれば最適化を検討
let greeting = make_greeting(&user_name);
println!("{}", greeting);
}
スレッド間でデータをやり取りしたいなら、Arc<Mutex<T>>を使えばよい。PythonやJavaは裏側で参照カウントやロックを行っているのだから、最初は気にしなくても問題ない。もちろん、こうした並行処理のデザインは後からリファクタリング可能だ。
use std::sync::{Arc, Mutex};
use std::thread;
let note = Arc::new(Mutex::new(String::from("Hello")));
let note_clone = Arc::clone(¬e);
thread::spawn(move || {
let mut data = note_clone.lock().unwrap();
data.push_str(", world!");
}).join().unwrap();
println!("{}", note.lock().unwrap());
共有状態が多すぎると複雑化するので、必要なら設計を見直せばいい。
フラットなディレクトリ構造にしておく
プロトタイプの段階ではmain.rsに全コードを押し込んでしまうのも一つの手だ。階層を作るのはあとからでも遅くない。
最初の段階:すべてをmain.rsに書く
fn main() {
// ここにコードをどんどん書く
}
後にモジュール構成を実験する
fn main() {
// main.rs内でmodを宣言して
some_feature::do_something();
}
mod some_feature {
pub fn do_something() {
// ...
}
}
mod other_feature {
// ...
}
このように最初はフラットにしておき、構造が明確になったらモジュールに切り出すのが効率的だ。大きな変更が頻繁に発生するうちは、ファイルを分けすぎるとリファクタリングコストが増すので注意が必要だ。
小さく始める
本番コードでの「ベストプラクティス」を最初からすべて守る必要はない。理想を追いすぎて何も作れないよりは、多少乱雑でも動くプロトタイプを素早く仕上げるほうがいい。
Rustは「完成度が低くてもとりあえず動く」という状態を許容しながら、後から本格的に手を入れるためのサポートを充実させている。まずは大まかな全体像を形にして、細部は後から詰めていけばよい。失敗したら捨てる覚悟でどんどん作り直すのもプロトタイピングの醍醐味だ。
まとめ
Rustでプロトタイプを作る最大の利点は、「安全性と速度を保ちつつ、気軽に実験できる」ことだ。たとえunwrap()まみれでmain.rsにコードを詰め込み、すべて所有型だけでコーディングしても、Pythonで書いたプロトタイプより信頼性が高く、しかもずっと高速に動作する。これにより、実際のワークロードを使って早い段階から検証できる。その後、きちんとエラー処理を加えれば本番運用にも耐えるコードに進化させられる。
Pythonとの比較を簡単に示すと次の表のようになる。
| Aspect | Python | Rust |
|---|---|---|
| 初期開発速度 |
|
|
| 標準ライブラリ | 充実しておりエコシステムも豊富 | 標準ライブラリは最小限だが、高品質なクレート群がある |
| 本番への移行 |
|
|
| メンテナンス |
|
|
| コードの進化 |
|
|
結論として、Rustはプロトタイピング言語としても十分優秀だ。型システムは設計を考える手間を増やすが、そのぶん後工程で手戻りが減る。PythonやJavaScriptより1回あたりの反復は重いかもしれないが、必要となる反復回数は少ない。ほかの言語でプロトタイプを書いていると性能や安全性の面で限界を感じてRustに書き換えたくなる局面が早期に訪れるが、Rustなら最初からプロトタイプ→本番という流れを一貫して同じ言語で進められる。
もしRustでのプロトタイピングで役立つテクニックを追加で知っていれば、元記事の作者に連絡してほしいとのことだ。
詳細は[Prototyping in Rust]を参照していただきたい。