11月6日、CodSpeedが「State of Python 3.13 Performance: Free-Threading」と題した記事を公開した。この記事では、Python 3.13の新機能である「フリースレッドモード」をはじめとする、CPythonのパフォーマンス向上機能について詳しく紹介されている。
以下に、その内容を紹介する。
CPython 3.13のパフォーマンス強化の概要
Python 3.13は、パフォーマンス向上を重視したリリースであり、次の機能が注目される:
- フリースレッドモード:グローバルインタプリタロック(GIL)が無効化され、マルチスレッド環境での実行が可能になった
- JITコンパイラの追加:動的な最適化を行い、実行速度を向上する
- mimallocアロケータの導入:デフォルトで効率的なメモリアロケーションが利用可能になった
本記事では特にフリースレッドモードに焦点を当て、パフォーマンスの影響について詳しく分析している。
フリースレッドCPythonの導入
フリースレッドは、Python 3.13で導入された実験的な機能で、GILを無効化してCPythonのマルチスレッド実行を可能にする。従来、GILはCPythonのメモリ管理を簡素化し、C APIを扱いやすくする一方で、複数スレッドによる同時実行を制限し、マルチコアプロセッサを有効活用できない大きな障害となっていた。
従来の回避策: マルチプロセス
GILの制約を回避するために、従来はmultiprocessingモジュールを利用して複数プロセスでの実行が推奨されてきたが、この方法には以下のような課題が存在する:
- メモリのオーバーヘッド:各プロセスごとにPythonインタプリタとメモリ空間が必要で、メモリ集約的なアプリケーションでは負荷が大きくなる。
- 通信コスト:プロセス間でのデータのシリアライズとデシリアライズが必要となり、オーバーヘッドが発生する。
- プロセス生成の遅延:プロセスの生成には時間がかかり、頻繁にワーカーを生成するタスクには不向きである。
現実的な影響: PageRankの例
PageRankアルゴリズムの実装を例に、フリースレッドモードの影響を考察している。PageRankは計算集約的で大規模なデータセットを扱うため、並列処理による恩恵を大きく受けるが、以下のような従来の問題があった:
- メモリのオーバーヘッド:グラフのデータを各プロセスでコピーする負荷。
- プロセス間のデータ転送のコスト:部分的な結果を各プロセス間で移動させるためのコスト。
- 状態管理の複雑さ:共有状態の管理が複雑になる。
実装例:シングルスレッド版
シングルスレッドでのPageRankアルゴリズムの基本的な実装例は以下の通りである:
def pagerank_single(matrix: np.ndarray, num_iterations: int) -> np.ndarray:
# 行列のサイズを取得
size = matrix.shape[0]
# スコアを一様に初期化
scores = np.ones(size) / size
# 指定された回数の反復を行う
for _ in range(num_iterations):
# 新しいスコアを格納する配列を初期化
new_scores = np.zeros(size)
# 各ノードについてスコアを計算
for i in range(size):
# 現在のノードにリンクしているノードを取得
incoming = np.where(matrix[:, i])[0]
for j in incoming:
# リンクしているノードのスコアを加算
new_scores[i] += scores[j] / np.sum(matrix[j])
# ダンピング係数を適用して新しいスコアを更新
scores = (1 - DAMPING) / size + DAMPING * new_scores
return scores
上記のコードでは、各ノードのスコアの寄与を計算し、ダンピング係数を適用する部分が特に負荷の高い処理である。
実装例:マルチスレッド版
マルチスレッドを使用して、上記の計算部分を並列化することで高速化を図る実装は以下の通りである:
# 行列サイズに基づきチャンクサイズを計算
chunk_size = size // num_threads
# スレッドごとに分割された行列の範囲をリストで定義
chunks = [(i, min(i + chunk_size, size)) for i in range(0, size, chunk_size)]
スレッドごとに行う処理を分担し、異なるチャンクを処理させる。また、new_scores配列の更新はロックを使用してレースコンディションを回避している。
実装例:マルチプロセス版
マルチプロセス実装では、プロセス間で直接メモリ共有ができないため、ローカルスコアを個別に保持し、最終的に合計する。multiprocessing.Poolを利用し、各チャンクを並列処理する。
with multiprocessing.Pool(processes=num_processes) as pool:
# 各プロセスが計算した結果をリストで集約
chunk_results = pool.starmap(_process_chunk, chunks)
# 各プロセスの結果を合計して最終スコアを計算
new_scores = sum(chunk_results)
プロセス間でのデータ転送があるため、メモリと通信コストがかかり、特に大規模データの場合はオーバーヘッドが大きくなる。
結果
これらのコードを、pytest-codspeedを利用したベンチマークにより、シングルスレッド、マルチスレッド、マルチプロセスの各実装を比較した。
その結果、以下のようなパフォーマンス上の特性が確認された。
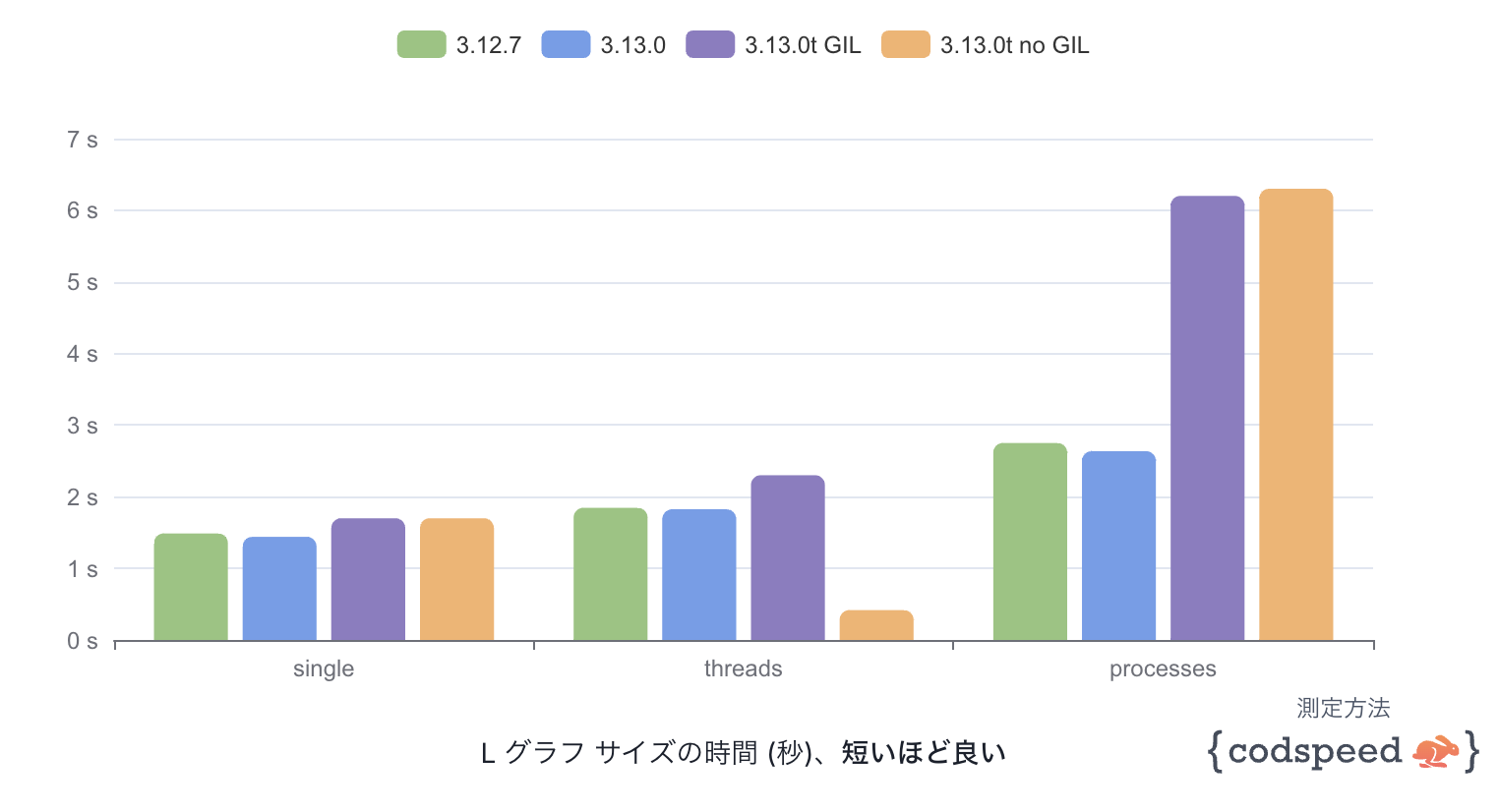
1. GILが有効な環境でのパフォーマンス
Python 3.12と3.13の通常ビルド(GILが有効な環境)では、multiprocessing実装はシングルスレッドよりもむしろ遅い結果が得られた。これは、プロセス間の通信が必要であるためで、データのシリアライズやデシリアライズのオーバーヘッドが発生する。また、プロセスの生成コストも影響しており、軽量なタスクの繰り返し実行には不向きである。
2. GILが無効な3.13tのパフォーマンス
GILを無効化した3.13tビルド(フリースレッドモード)では、threadingベースの実装が最も高速であり、各スレッドが並列に動作することでシングルスレッドの実装と比べて大幅なスピードアップが達成された。この結果から、GILによる制約がなくなることで、特に計算集約的な処理でのスレッド並列化のメリットが確認された。
3. フリースレッドビルドで発生するオーバーヘッド
フリースレッドビルド(GILなし)では、スレッド並列処理のメリットがある一方で、いくつかのオーバーヘッドが確認された。特に、フリースレッドビルドでは特化型の適応インタプリタ(specializing adaptive interpreter)が無効化されるため、multiprocessingやシングルスレッドの実装ではパフォーマンスが低下する傾向にある。このインタプリタは通常、コードを実行時に最適化するが、フリースレッドビルドではスレッド安全性の観点から無効化されるため、単純なシングルスレッド実装でさえ従来のビルドよりも遅くなる場合がある。これにより、GILが有効な通常ビルドと比較して、multiprocessingや一部の並列処理が期待したほどのパフォーマンスを発揮できないケースが見られた。
4. 将来的な改善見込み
現在のフリースレッドビルドは実験的であり、Python 3.14以降では特化型インタプリタのスレッド安全性が改善され、再び有効化される予定である。この改善により、フリースレッドモードでのオーバーヘッドが軽減される見込みで、並列アプリケーションにとってGILなしの環境がより実用的になることが期待されている。
現時点でのフリースレッドビルドは、GILがないために並列処理には有効であるものの、特定のシングルスレッドおよびマルチプロセス処理ではパフォーマンス低下が見られることから、慎重に評価を行う必要がある。
詳細はState of Python 3.13 Performance: Free-Threadingを参照していただきたい。