
OtterTuneが2023年に公開したブログ記事「PostgreSQLで最も嫌いな部分」が、2024/10/21にまた人気を博している。この記事では、PostgreSQLのマルチバージョン並行性制御(MVCC)実装の問題点について詳しく紹介されている。
以下に、その内容をかいつまんで紹介する。
はじめに
データベースの選択肢は数多く存在し、2023年4月時点で897種類にのぼる。これだけ多くのシステムがある中で、どれを選ぶべきか迷うのは当然だ。2000年代には、GoogleやFacebookといった新進気鋭のテック企業が使用していたことから、MySQLが一般的な選択肢となっていた。その後、2010年代には、NoSQLストレージとしてMongoDBが人気を博した。そしてここ5年ほどで、PostgreSQLがインターネット上で最も愛されるDBMSとなった。その理由は、信頼性が高く、機能が豊富で、拡張性があり、多くの運用ワークロードに適しているからだ。
しかし、OtterTuneはPostgreSQLを愛しているものの、 PostgreSQLのMVCCの実装方法は、主要なリレーショナルDBMSの中で最も問題がある と指摘する。これは、カーネギーメロン大学での研究や、Amazon RDS上でのPostgreSQLデータベースの最適化経験から明らかになった事実であり、AmazonのPostgreSQL Auroraでも同様の問題が存在するという。
MVCC(マルチバージョン並行性制御)とは?
MVCCの目的は、複数のクエリが同時にデータベースを読み書きする際、可能な限り互いに干渉しないようにすることだ。基本的なアイデアは、 DBMSが既存の行を決して上書きせず、各(論理的な)行に対して複数の(物理的な)バージョンを保持する というものだ。クエリを実行する際、DBMSは特定のバージョン順序(例:作成タイムスタンプ)に従って、リクエストを満たすための適切なバージョンを取得する。
このアプローチの利点は、 他のクエリがデータを更新している最中でも、古いバージョンを読むことができるため、読み取り専用のクエリがブロックされない ことだ。クエリは、トランザクションが開始された時点のデータベースのスナップショットを観測する(スナップショット分離)。これにより、データを変更している書き込みクエリによって読み取りクエリがブロックされるのを防ぐ。
MVCCは1978年、David ReedのMIT博士論文「Concurrency Control in Distributed Database Systems」で初めて紹介されたとされる。その後、1980年代に商用DBMSであるInterBaseで初めて実装された。それ以来、トランザクションをサポートするほぼすべての新しいDBMSがMVCCを実装している。
PostgreSQLのMVCC実装
1987年のStonebrakerのシステム設計文書によれば、PostgreSQLは当初からマルチバージョンをサポートするよう設計されていた。PostgreSQLのMVCC方式は一見すると単純だ: クエリが既存の行を更新するとき、DBMSはその行をコピーし、新しいバージョンに変更を適用する。 このアプローチは「 追記型 」のバージョンストレージ方式と呼ばれる。しかし、この方法はシステムの他の部分にいくつかの複雑な影響を及ぼす。
マルチバージョンストレージ
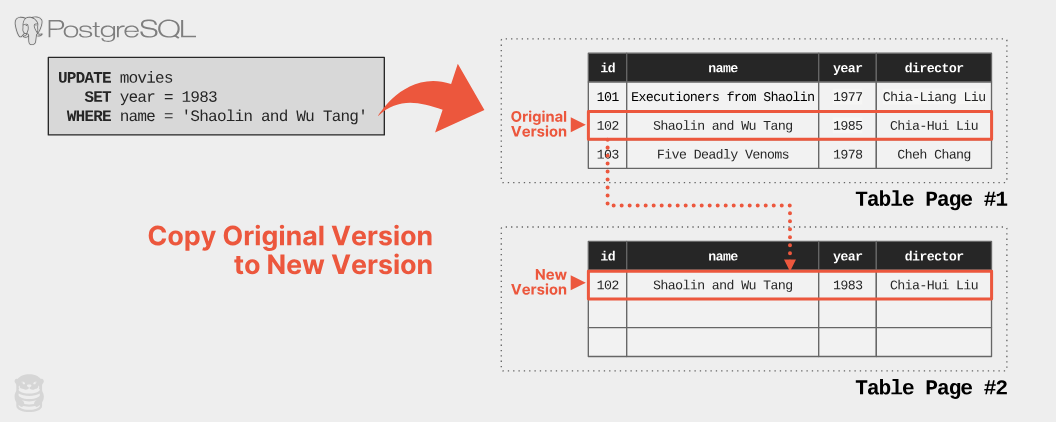
PostgreSQLは、 テーブル内のすべての行バージョンを同じストレージスペースに格納する。 既存のタプルを更新する際、DBMSは新しい行バージョンのための空きスロットをテーブルから取得し、現在のバージョンの内容を新しいバージョンにコピーして変更を適用する。
例えば、映画データベースで「Shaolin and Wu Tang」の公開年を1985年から1983年に変更する場合、以下のクエリが実行される。
UPDATE movies
SET year = 1983
WHERE name = 'Shaolin and Wu Tang';
この操作により、元の行のコピーが作成され、新しいページに新バージョンが配置される。
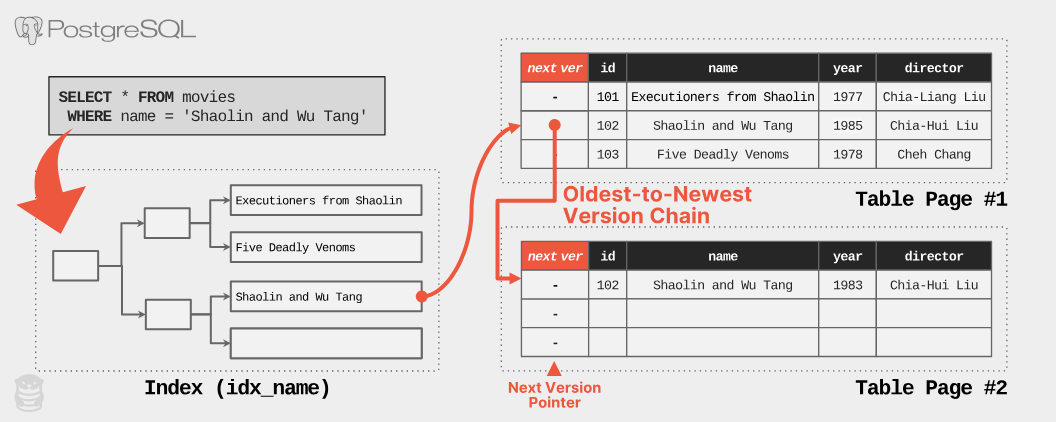
しかし、同じ論理行に対して複数の物理的なバージョンが存在するため、DBMSはこれらのバージョンの関連性を追跡する必要がある。MVCCを採用するDBMSでは、 単方向リンクリストによるバージョンチェーン を作成してこれを実現する。
ここで重要なのは、DBMSがバージョンチェーンを最新から最古(N2O)の順序で構築するか、最古から最新(O2N)の順序で構築するかだ。多くのDBMS(OracleやMySQLなど)はN2Oを採用しているが、PostgreSQLは唯一O2Nを使用している。この選択により、インデックスの更新を避けることができるが、その代わりに最新バージョンを見つけるために長いバージョンチェーンをたどる必要がある。
バージョンの真空化(Vacuum)
PostgreSQLは、 自動バキューム(autovacuum) というプロセスを使用して、古いバージョン(死んだタプル)を削除する。自動バキュームは定期的に実行され、テーブルを順次スキャンして不要なバージョンを特定する。バージョンがどのトランザクションからも参照されていない場合、それは「期限切れ」と見なされ、安全に削除される。
しかし、このプロセスには問題がある。書き込みが多いワークロードでは、バキュームが不要なバージョンの蓄積に追いつかず、テーブルが膨張し続ける。また、長時間実行されるトランザクションが存在すると、自動バキュームがブロックされ、パフォーマンスが低下する可能性がある。
PostgreSQLのMVCCが「最悪」である理由
PostgreSQLのMVCC実装は、現代のDBMS設計の観点から見ると多くの問題を抱えている。その主な問題点は以下の通りだ。
問題1:バージョンコピーの非効率性
PostgreSQLでは、 タプルが更新されるたびに、その全体がコピーされる。 たとえ1つのカラムだけを変更する場合でも、全カラムがコピーされるため、データの重複とストレージの無駄遣いが発生する。
他のDBMS(OracleやMySQLなど)は、差分データ(デルタ)のみを保存することで、この問題を回避している。これにより、更新があった部分だけを記録し、ストレージの効率化を図っている。
問題2:テーブルの膨張(テーブルブロート)
不要なバージョン(死んだタプル)が蓄積すると、 テーブルサイズが増加し続ける。 自動バキュームがこれを削除するまで、クエリ実行時に不要なデータが読み込まれ、I/Oとメモリのリソースが浪費される。
さらに、バキュームでは ディスク上の空き領域を解放できない。 テーブルサイズは一度増加すると縮小しないため、VACUUM FULLやpg_repack拡張機能を使用してテーブルを再編成する必要がある。しかし、これらの操作はリソースを大量に消費し、実行中のクエリに影響を与える可能性がある。
問題3:二次インデックスの維持コスト
PostgreSQLは、タプルが更新されるたびに、テーブルのすべてのインデックスを更新する。 これは、更新のたびに新しいバージョンが作成され、その物理的な場所が変わるためだ。
この結果、更新クエリのパフォーマンスが低下し、I/Oが増加し、ロックやラッチの競合が発生しやすくなる。他のDBMSでは、インデックスに論理識別子を使用することで、この問題を回避している。
問題4:自動バキュームの管理
自動バキュームの効果的な管理は難しく、 デフォルト設定ではすべてのテーブルに最適ではない。 例えば、テーブルサイズの20%が更新されるまでバキュームが開始されない設定になっていると、大量の不要データが蓄積する可能性がある。
また、長時間実行されるトランザクションが存在すると、自動バキュームがブロックされ、問題がさらに悪化する。このような場合、データベース管理者が手動で介入し、長時間実行されているクエリを終了させる必要が生じる。
結論
PostgreSQLのMVCC実装は、その設計が1980年代のものであり、現代の要件には適していない部分がある。しかし、それでもなお、PostgreSQLは多くの場面で優れたDBMSであり、その機能や拡張性は高く評価されている。
OtterTuneは、これらの問題に対する自動的な解決策を提供しており、データベース管理者の負担を軽減することを目指している。PostgreSQLの欠点に対処しつつ、その利点を最大限に活用することで、より効率的なデータベース運用が可能になるとしている。
詳細は[The Part of PostgreSQL We Hate the Most // Blog // Andy Pavlo]を参照していただきたい。