
本セッションの登壇者
セッション動画
「LLMによるフロントエンド生成自動化」というテーマで発表させていただきます、mizchiです。
皆さん、LLMは当然のように使っていると思います。会社の都合で使えない方もいるかもしれませんが、ChatGPTやCopilotなどがインフラになりつつあると感じます。ただ、エンジニアとしてはWeb UIではなくCLIで自動化したい、日々のタスクの一環として、LLMへのリクエストをワークフローに組み込むことで、私たちプログラマーの役に立つかどうかを試してみたいと考えていて、Denoで書き捨てのスクリプトを大量に書いています。

DenoでLLMを操作しよう
Denoを使う理由は、npmインストールや依存関係の解決が簡単で、VSCodeでキャッシュが効くなど、スクリプトが書きやすいことに価値を感じるからです。
また、native bindingを除いてnpmの資産も利用でき、サードパーティーのコードも動作します。最近見つけた、DenoのメンテナーのLuca氏が作ったesbuild-deno-loaderは、Denoのモジュール解決ルールをesbuildに移植したもので、これを使ってフロントエンドの資産を活用し、フロントエンドのコードを生成することを目指しています。

たとえば、Denoでgpt-4oを叩くコードはこれだけです。APIキーを別途取得する必要はありますが、簡単ですね。バージョンを固定するのが大事ですけれども、これはDenoがインストールされていればポンと動きます。

Claude-3-opusのAntrophicのコードもOpenAIのAPIに合わせているので自然に叩けます。HTTP Requestができれば言語は本当に何でもいい感じです。

Reactコンポーネントの生成、編集を対話型で行える「previs」
ここから本題ですが、マークアップを自動化したいと思って「previs」というツールを作りました。
これはReactコンポーネントを生成したり修正したりできるCLIで、自分の学習用プロダクトになっています。

どういうものかというと、deno install -Af として、CLIで「このファイルのボタンのコンポーネントを作って」とするとボタンコンポーネントを生成してくれます。さらに、「背景を黒くして」とすると書き換えてくれて、-- でテストコードを渡すとそのテストが通るまで自動で修正する…というのを実装してみました。

コンポーネントを作ってプレビューして、それを人間が目視で確認して、修正して、テストを実行する…というのを、対話型で繰り返し行えるツールというイメージです。
実際の動作としては、.previsというフォルダの下に、1個のファイルをインポートするだけの一時的なプロジェクトを作っています。そしてサーバーを起動してpuppeteer でスクリーンショットを撮り、そのスクリーンショットを添付してgpt-4oに画像を送信します。その結果をbase64でエンコードして、得られた結果を元コードに書き込むという流れです。

プロンプトは全部 scrap に書いていますので参照してください。

また、Reactのコンポーネントを生成するための規約をいくつか作っています。たとえば、__preview__ というファイルでエクスポートするなどです。ボタンコンポーネントをプレビューしようとしたらtext, onClickという Propsが必要です。「~が足りない場合」というプロンプトを入れて、それをAIにモックごと生成させています。

また、previsではIn-source Testingをやるようにしています。たとえばvitestなら、import.meta.vitset があったら、テストヘルパーを取り出してテストコードを書くみたいな感じですね。

あと、人間がチェックせずにAIが悪意あるコードを参照して実行したらと考えると、テストを評価するのはすごく危険なんですね。
たとえば1999年ぐらいに書かれた学習資料で実際に見たことがありますが、文字列から数値の変換にはevalを使うと書いてあります。これをそのまま使うと、いろいろな攻撃計画と組み合わせて任意コード実行につながってしまう可能性があります。そこで必要なのがDeno SandboxやNode: Process Based Permissionのような、実行プロセスに権限を付与するという機能です。ちゃんとサンドボックスがある環境でコードを評価しましょう。

LLMは修正が苦手→毎回ゼロから作ればいい
previs を作ってみた感想ですが、そもそも肝心のLLMの生成の精度が悪く、CSSの崩れが頻発します。その対策に画像をアップロードして「崩れたら修正して」みたいなことをしてみましたが、崩れている箇所と、実際のソースコードでそれが起きている場所を紐づけることができず、今のLLMの性能だと修正できません。基本的な能力が足りていないのと、修正のたびに全文を生成しようとするので、「自分でやった方が早い」となりがちです。

じゃあそもそも、修正が苦手なら毎回ゼロから生成すればいいんじゃないかと考えました。UIフレームワークをロジックのみの非依存の状態にして、元のコードを忘れてTailwindで再装飾し直して、と指示するようにしました。
ワンショットを並列化するアプローチですが、一瞬でAPIの使用上限に達してしまい、クレジットを補充し直しました。あと、1回アップロードした画像を修正するのではなく、ドローイングツールのExcalidrawで雑にワイヤーフレームを書いて「これにこんな感じのレイアウトで」と投げたらうまくいった日もあります。

さまざまなことを試しましたが、AI周りの人たちと同様に自分も、結局はAIコード生成向けのRAG(Retrieval-Augmented Generation)を作るしかないかと思っています。これはAIに検索機能を与えるもので、embeddingという機能を使ってローカルソースコード検索も実装できます。

ワークフロー自体はAIに作らせれば良くて、僕らがやることはツールの提供ではないかと思っています。たとえばテストコードを実行する、TypeScriptのタイプチェックをするなど、大量にツールを実行して、あとはそれに従って自分がやりたいことをプロンプトで表現して、そのワークフローが正しいかどうかを人間がたまに見て検証してあげて実行する。これが今、多分必要なワークフローだろうという気がしています。

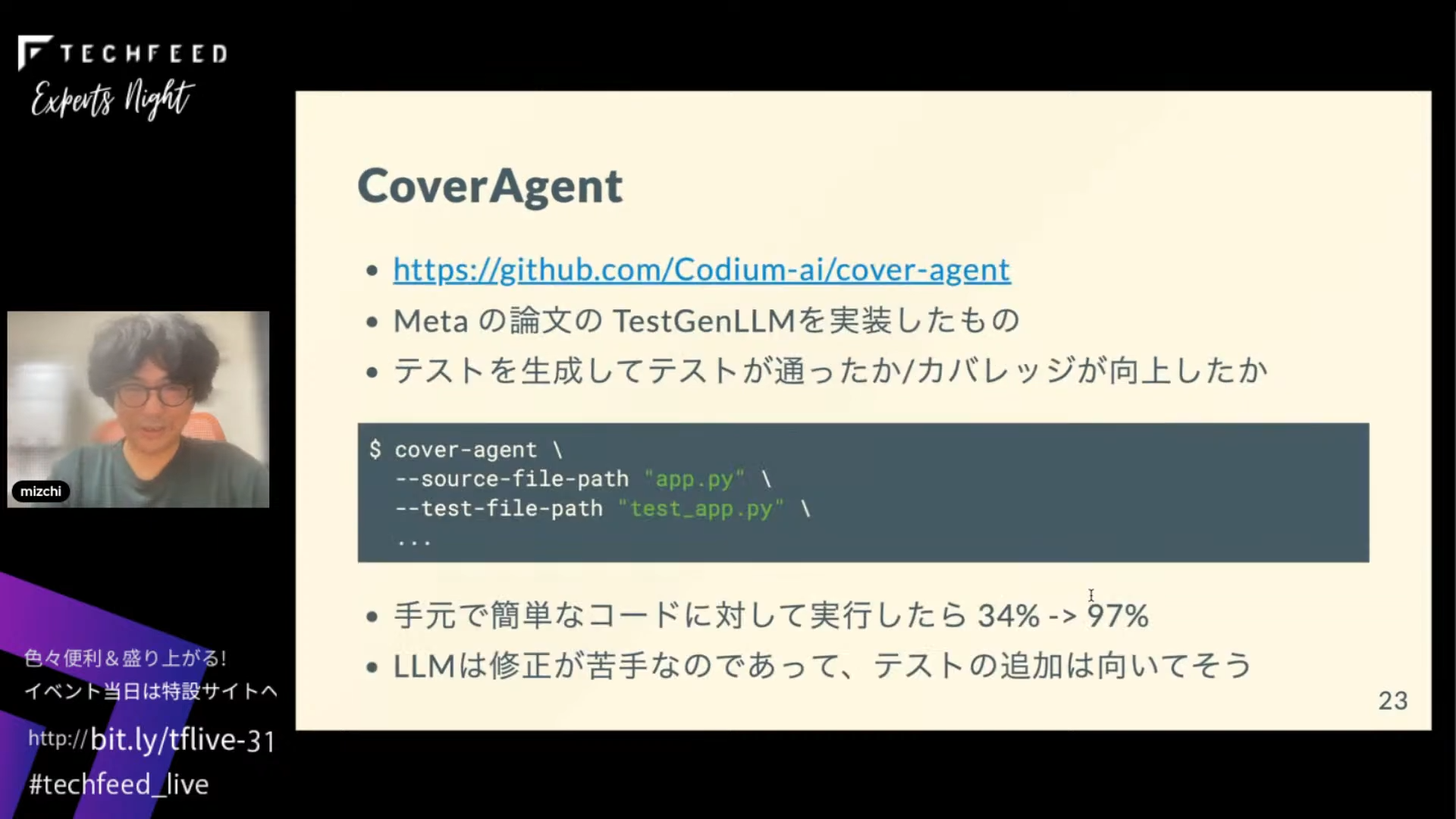
他のツールがどうやっているか調べてみました。たとえばこれはCoverAgentというMetaのTesGenLLMというユニットテストを生成する論文をPythonで実装したCLIツールです。テストコードを生成して、意味があるテストかどうかという人間的な評価はせずに、それによってカバレッジが向上したかということだけを見てテストを生成し続けます。手元のサンプルコードで実行したら、理想化された環境ではありますが最初34%くらいだったのが97%まで行きました。LLMは修正が苦手ですが、コードの追加は結構得意そうだなというイメージです。
「今」じゃない。けれどもその日は近い
まとめです。当たり前ですが、雑なワンショットプロンプトだと簡単なものしか作れません。今必要なのは、AIが知らないプロのドメイン知識と、プロがどうやって情報を得ているかというのをコードで書いてひたすら教えるフェーズを入れることと、性能です。ただ、試した感じでは単純なマークアップに関しては3年から5年ぐらいすれば、簡単なケースや6~7割のケースは自動化できるんじゃないかという気がしています。現状はまだ早いです。

今回のプロンプトエンジニアリングは、インターン向けの指示書を作るのに近かったです。誰でもできるという感じではなく、最低でもプロンプトガイドは読んだ方がいいでしょう。
また、Pythonの方が知見や作例が多いので、Pythonの実行環境は用意しておいた方が無難です。移植するよりファストAPIのサーバーを書いて、APIで実行した方が早いこともよくありました。

細かく気になっているものは、MistralAIのコード生成特化モデルの codestral や、Qwikを作っているBuilderIOが出したコード書き換えCLIツールのmicro-agentなどがあります。この界隈はあまり詳しくないのでいいものがあったら教えてください。では終わります。

記事中のプロンプトガイドの URL が間違っているようです。
promptingguide.ai.jp => promptingguide.ai/jp