
本セッションの登壇者
Rustをこれから大きく支えるかもしれないSeaQL Projectsというものについて発表していきたいと思います。
このプレゼンテーションの目標としては、SeaQL Projectsという取り組みを知ってもらうことがあります。実は私が勝手に付けているのですがこの名前の由来もお話しします。また、Seaから始まるクレートがたくさんありますが、そのSea系のプロダクトが皆さんの技術選定時の候補に上がってくる状態にすることを目標にします。

免責事項ですが、私は実はこのプロダクト自体は本番環境では使ったことがなく、ちょっと手元で動かしてみた程度なので、本番運用上で辛いポイントなどはお話ししません。

Sea系プロダクトを総称
初めて聞いた方も多いと思うのでSeaQL Projectを簡単に説明すると、頭にSeaのつくクレート群の総称として私が勝手に呼んでいるものです。
www.sea-ql.orgというサイトがあって、Projects の下にいくつかクレートがぶら下がっています。SeaQLのProjects なので「SeaQL Projects」と便宜的に呼んでいます。
このプロジェクトの内容として一番有名なのはSeaORMというO/Rマッパーのクレートです。関連してGraphQL、ストリーミング処理用のライブラリ、タイムトラベル・デバッキングができるちょっと高機能なデバッガーなどを作っています。グループのトップは、プロフィールを見た感じでは香港からイギリスに移った経歴を持つ方のようです。

SeaQLプロジェクトの製品群では、SeaORMの他に、SeaORM X、SeaQuery、ジオグラフィーのもじりと思われるSeaography、SeaStreamer やデバッガーのFireDBGがあります。

簡単に紹介していくと、SeaORMはRustの情報を追っている方は目にしたことがあるかもしれません。どちらかというとDieselやSQLxのようなクエリービルダーではなく、ある程度本格的なO/Rマッパー用のクレートです。対応している製品は、MySQL、Postgres、SQLite。「X」と付く方はSQLServerに対応しているもののようです。なぜ分けたのかはよく分からないですが、SQLServer向けの事情があったのかなと思っています。使い心地は後で見ていきますが、結構RailsのActive RecordやActive Modelに近いかなと思います。なので、そちらに慣れている方は意外となじみがあるかもしれないし、逆にRust独特の文法に違和感があるかもしれないですね。

次がSeaQueryというクレートです。これはSea内で使われているクエリービルダーです。簡単にクエリーを組み立ててくれるので、使える場面があるかもしれないですね。

Seaographyというのは、SeaORMで作ったモデルの機能を拡張して、GraphQLに対応させることができるクレートです。主にはRustでGraphQL用に使われる async-graphql というクレートとSeaORMをもとに作られていて、GraphQLに対応しているというのが特徴かなと思います。

最後はSeaStreamerで、いわゆるストリーミング処理を行えるようにするクレートです。RedisやKafkaに対応していて、その辺をプロデューサーやコンシューマーにすることができます。

Sea系のプロダクトに言えることとしてはまず、非同期処理対応がデフォルトでされている印象があります。具体例を挙げると、Dieselはまだ対応されていなくて工夫が必要でしたが、Sea系はデフォルトで対応しているので好感が持てるポイントかと思います。非同期ランタイムのtokioとasync-stdに対応しているので、そういった意味でも使うチャンスが多いクレートだと思います。また、けっこうドキュメントが充実している印象があります。網羅的に機能が解説されているので、ドキュメントの内容を上から触っていくと使い方が分かるのは良いところです。最後、大きな利点として、メンテナンスがグループで行われていて、これからも続くだろうと期待が持てる点です。Rustのサードパーティー製クレートは個人がメンテナンスしていることが多く、その人のモチベーションに頼るところが大きいのですが、グループでメンテナンスをされているとそうしたリスクは減ります。そういう意味でも選んでみる価値があると思います。

O/Rマッパー「SeaORM」でテーブルを定義
では、簡単にSeaORMを見ていきます。サンプルコードはこちらです。

SeaORMの利点と改善ポイントを簡単にお話しすると、いいところは普通に実用的なデザインをしていて使いやすいことです。また、Rustにはまだ数の少ないO/Rマッパーを利用できることで、Java のHibernate のようなハードめのO/Rマッパーを使う方も納得できる構成になっていると思います。sea-orm-cli というCLIツールも提供されていて、組み合わせるとマイグレーションやRustコードの生成をスムーズに行うことができるようです。逆にちょっとここはもうちょっと手が届いてほしいポイントは、多用する手続き的マクロによって生成される箇所のコンパイルエラーの読み解きが難しいという問題があります。触ってみた時に思いましたが、はまった時にどう解決したらいいんだというコンパイルエラーがあったりして、わりと大変そうだという印象があります。ただ、Rust 1.78から入った #[diagnostic::on_unimplemented]という、トレイトが実装されていない時に出すコンパイルエラーをカスタマイズできるアトリビュートがあるんですが、これを駆使して対応できそうです。そのあたりはこれからの改善に期待したいポイントかなと思いますし、私もちょっと改善してみたいなと思いました。あとは単純にボイラープレートが多めです。O/Rマッパーではリレーションの定義などいろいろと設定が必要な手前、仕方がないかなという気もしますけれども、やっぱりDieselやSQLxと比べると、どうしてもボイラープレートが増える印象です。

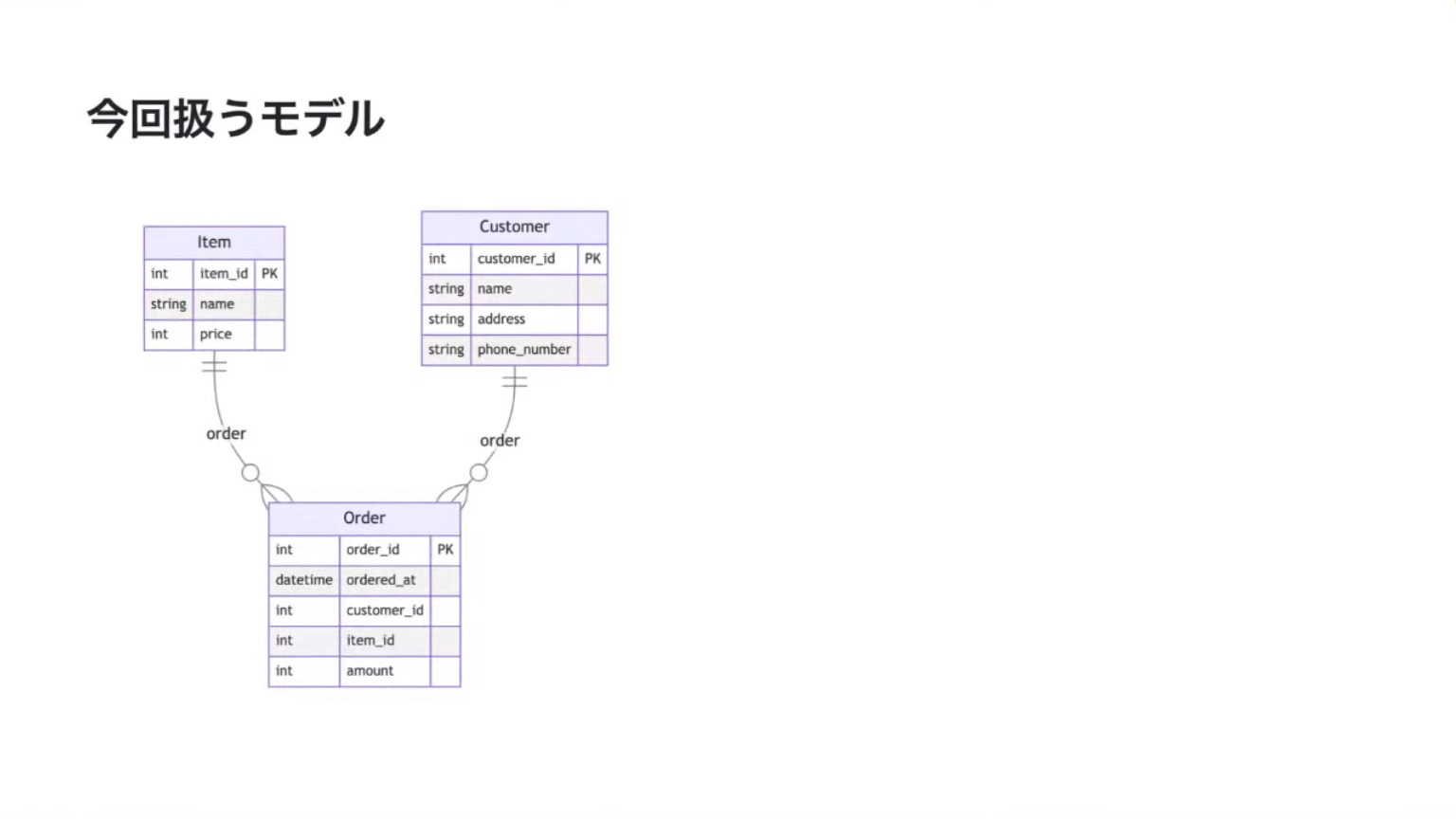
簡単にテーブル定義の様子を紹介します。今回はこんな感じで「item」、「customer」、「order」という3つのリレーションとテーブルを用意しています。3つという数に深い意図はありません。大事なポイントは、ここに1対多(one-to-many)のリレーションが張られていることで、そのあたりを重点的に説明したいと思います。
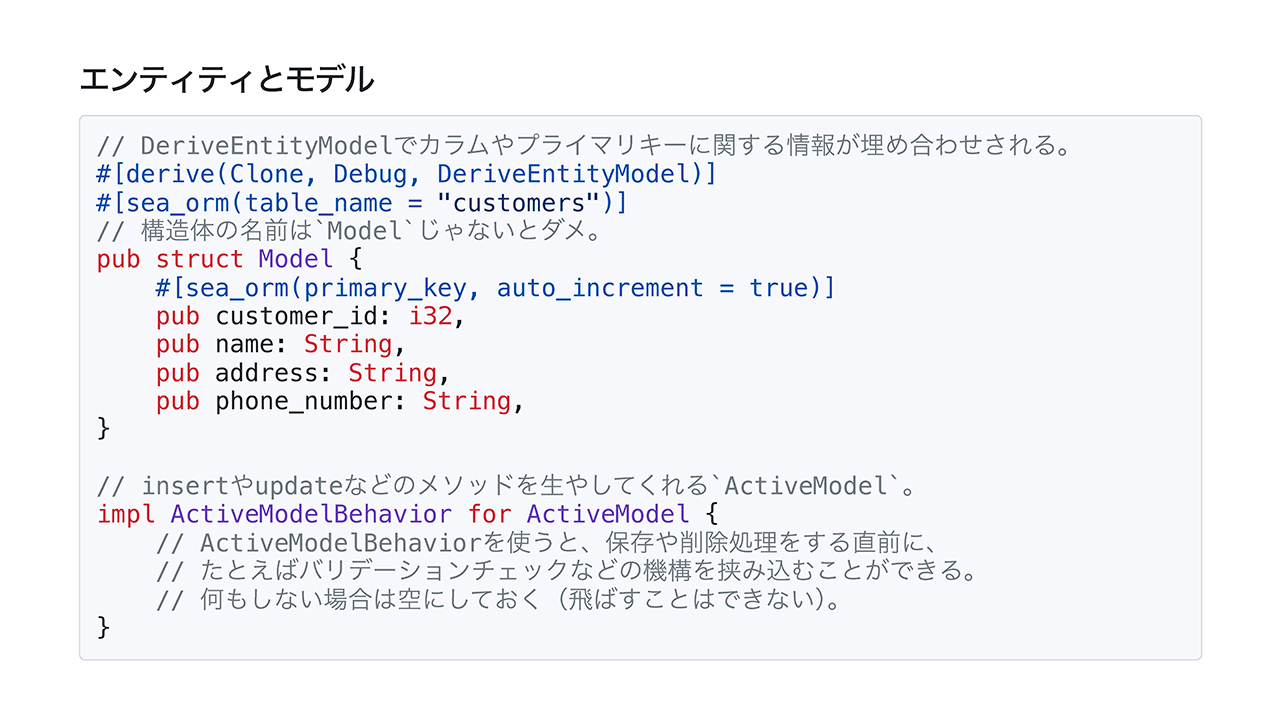
まず、モデルの定義の話をします。Model という構造体を定義して、そこに対して DeriveEntityModel という Derive を使って Entity を生成させる作業を行います。次に、ActiveModel 関連の操作の定義をします。最後にRelated でトレイトを使って関係性を定義します。この順番で簡単に説明していきたいと思います。

customer モデルはこんな感じになります。pub struct Model { でモデルを定義して、その下にリレーション、つまり関係性を定義して、最後にアクティブモデルに関する定義をするという、3段構成で定義を進めていきます。これは他のアイテムやオーダーにも行うので、この時点でボイラープレートが増える感じにはなります。

エンティティとモデルの肝にあるのは、DeriveEntityModelというトレイトです。これによってカラムやプライマリキー、テーブルの名前などを定義することができます。ちなみに構造体の名前は、CustomerModel のように定義することはできなくて、必ず Model でなければなりません。このDeriveEntityModelの実装の都合によると思うんですけど、ここはちょっと若干使いにくいポイントかもしれないですね。
次に、下にある ActiveModel というのはinsertやupdateなどのメソッドを生やしてくれるもので、これを使うと事前のチェックができたりします。今回は何も定義しないので飛ばします。
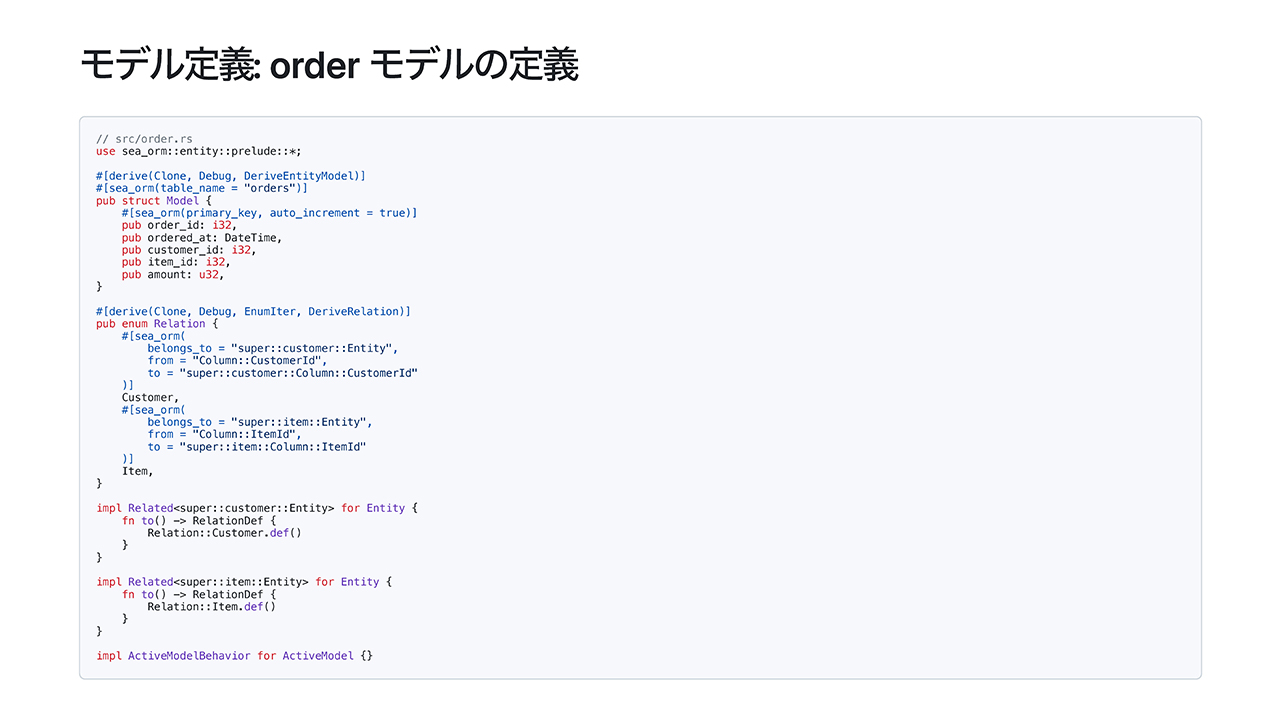
orderモデルも同様に定義します。
itemモデルもこんな感じで定義します。

リレーションを定義して customer と order、item と order を one-to-many の関係にします。これをSeaORMで定義するとどうなるかという話をしていきます。

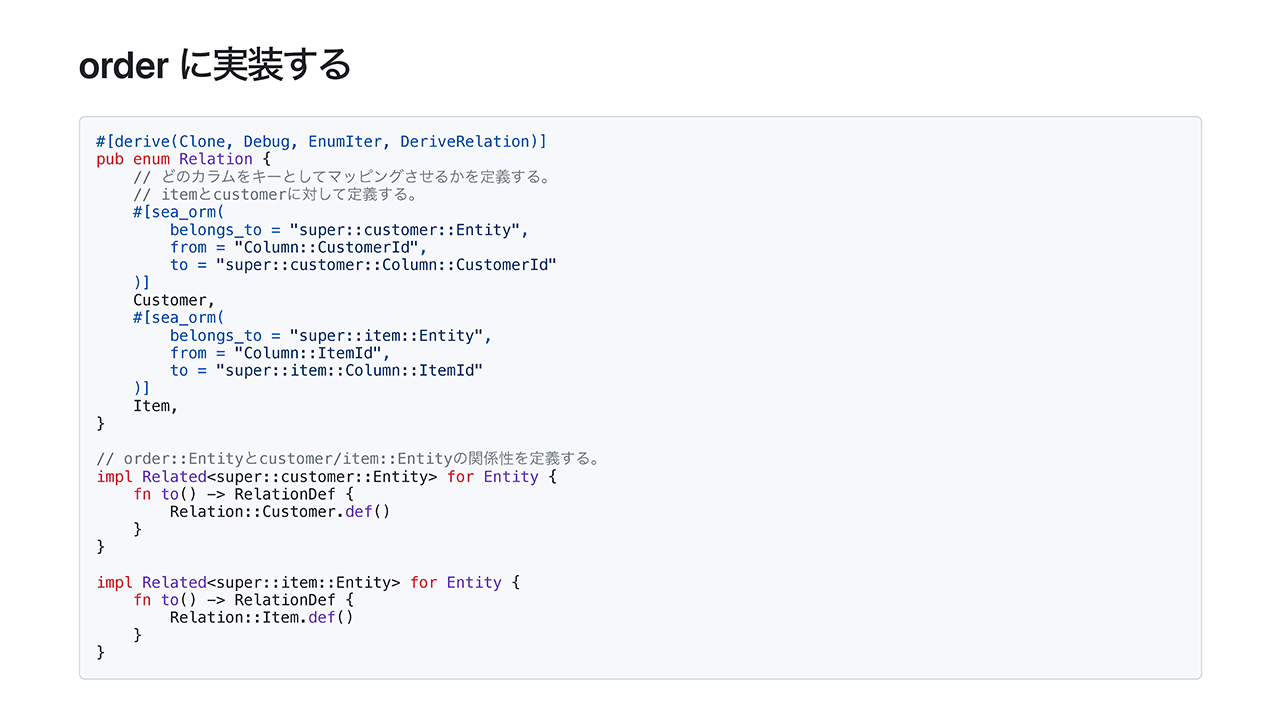
主には先ほど定義したように、Relation という enum を定義して Related トレイトを実装することになります。

このような形でまず Relation という enum を定義して、DeriveRelationがいろいろ裏で処理を支援してくれつつ、has_many を使って order の Entity に対してone-to-manyの関係性を定義することができます。Related トレイトで最後にこの関係性を呼び出してやると関係を定義できたことになります。

itemも同様にorderに向けておきます。

orderからは逆にcustomerとitemに対する関係性を定義する必要があって、それをマッピングしているという実装です。
充実したテスト周り
最後にデータベースの接続をやるべきですが、結構テスト周りも考慮されて実装されてるなと思ったのでその話をしたいと思います。具体的には、生成されたEntityからfind_by_idなど、データベース操作の関数が入っているのを確認したり、モックを使ったテストの仕方を確認していきます。

テストコードはこんな感じです。MockDatabaseというものを使うと、データベースのモックを生やして設定を定義することができます。最後にアサーションを実行するという流れです。
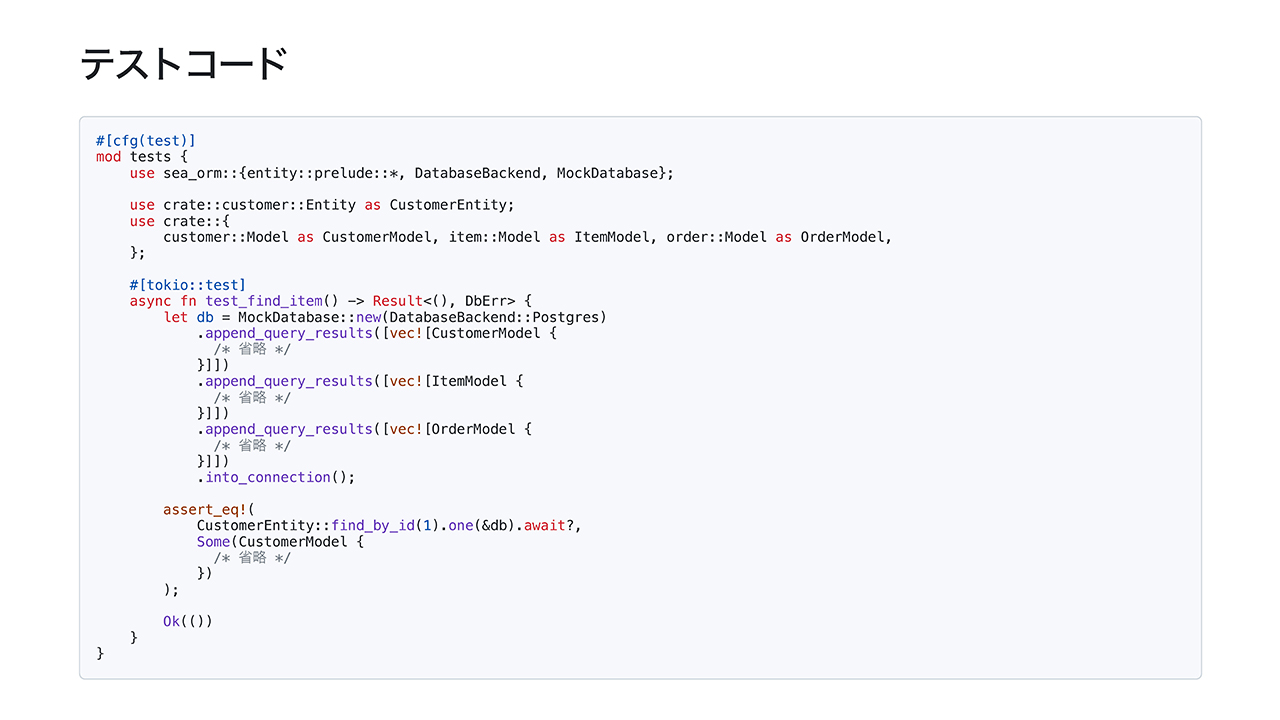
ポイントは、このあたりです。

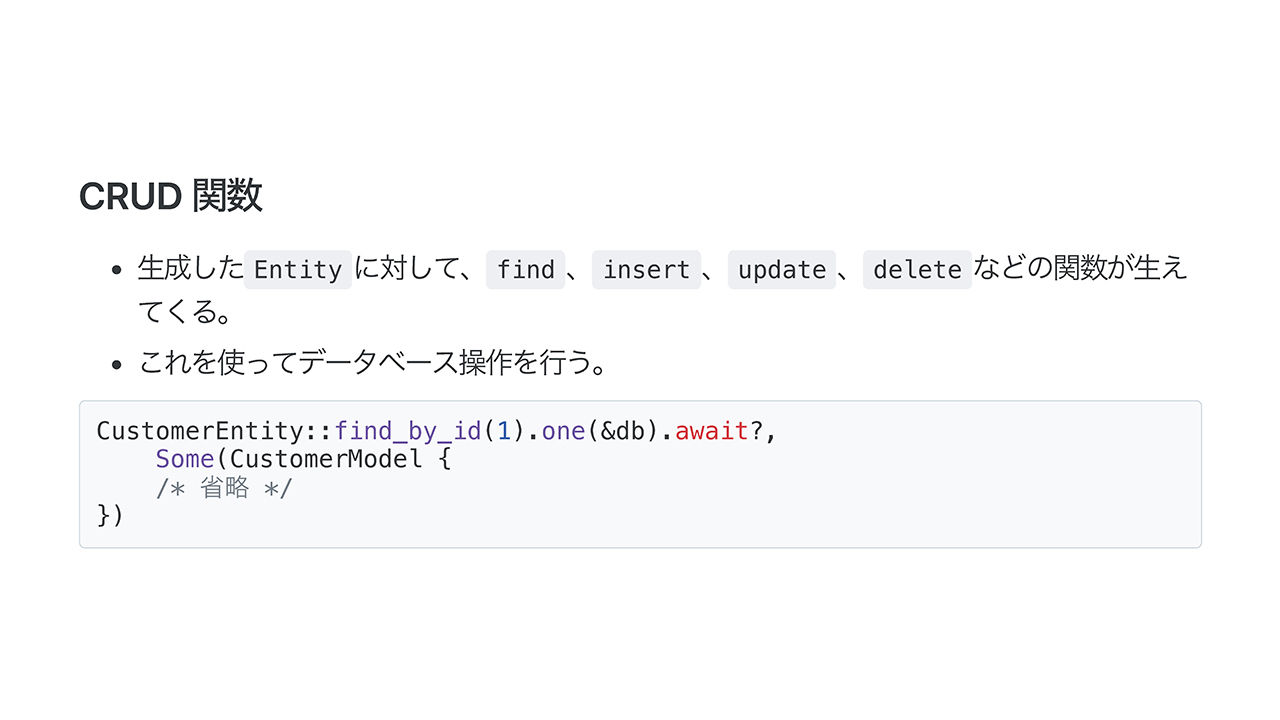
まずはCRUD関数です。最終的にはO/Rマッパーなので、find、insert、update、delete などの関数が生えてきてくれて、これを使ってデータベース操作をすることができます。シンプルで使いやすそうですね。
モックデータベースの定義はこのようになっています。データを手軽にセットできて便利だなと思いました。
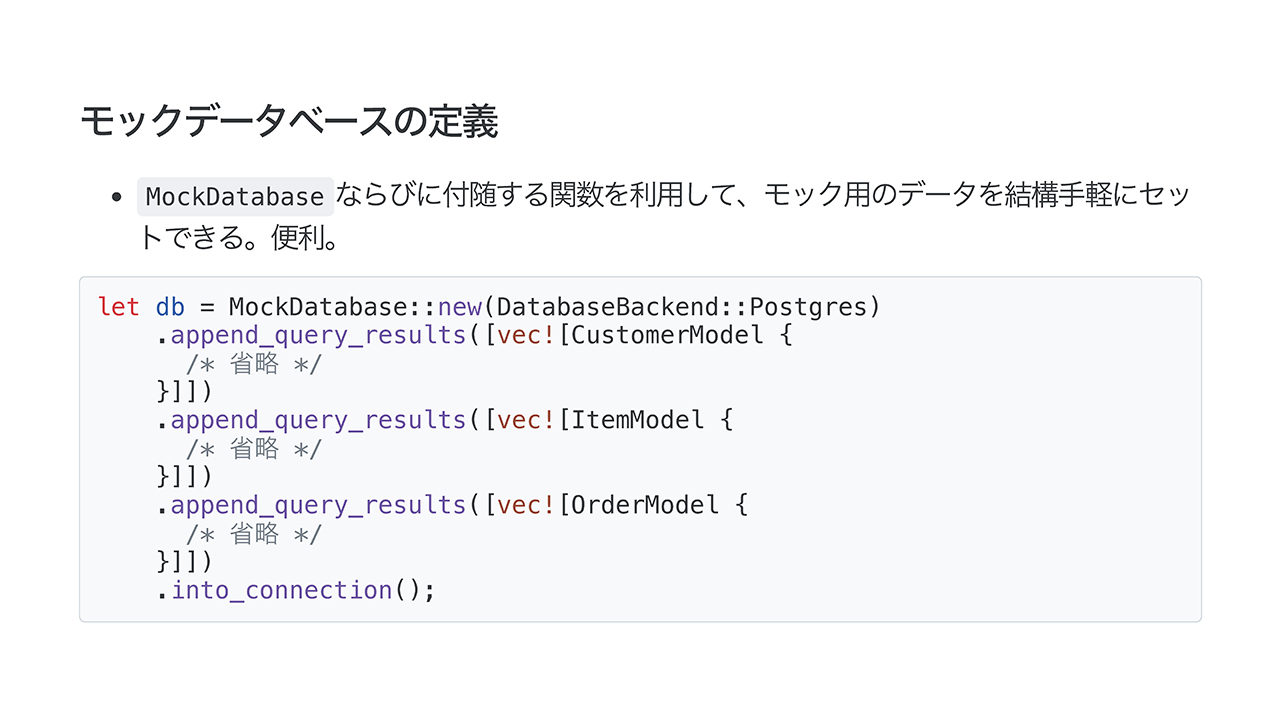
読み出しの場合は append_query_results 関数を使ったんですけど、もちろん書き込み側も定義できます。そのあたりはテストが充実している印象です。

余談ですが、sea-orm-cliという機能があって、データベースマイグレーションができます。あと、これはすごいなと思ったのは、実テーブルの情報を読み込んでエンティティのコードを自動生成させられるところです。実務上、非常に役に立つなと思います。

その他Sea系クレートとの連携も比較的充実していて、SeaORMを使ってGraphQLのスキーマを定義できたり、それを使ってストリーミング処理を行ったりできるようです。

まとめです。Sea系のクレートがありますという話と、SeaORMのお話をさせていただきました。これでセッションを終わりにしたいと思います。ありがとうございました。
