こんにちは。エンジニアリンググループのAI・機械学習チームに所属している三浦(@mamo3gr) です。弊チームでは毎週1時間の技術共有会を実施しており、各自が担当するプロダクトの技術や、最近読んだ論文を紹介しています。今週はCVPR2024が開催されていることもあり、同学会の論文読み会となりました。1セッション1名の担当で、各自がセッション内で気になった論文の詳細を解説します。本ブログではその一部として、セッションごとの「推し論文」を紹介します。

- LDP: Language-driven Dual-Pixel Image Defocus Deblurring Network
- EventPS: Real-Time Photometric Stereo Using an Event Camera
- LISA: Reasoning Segmentation via Large Language Model
- CroSel: Cross Selection of Confident Pseudo Labels for Partial-Label Learning
- We are hiring !!
LDP: Language-driven Dual-Pixel Image Defocus Deblurring Network
- セッション: Low-level Vision and Remote Sensing (Orals 6A)
- 著者: Hao Yang, Liyuan Pan, Yan Yang, Richard Hartley, Miaomiao Liu
- 論文リンク: PDF
- 紹介者: 池嶋 (機械学習エンジニア)
推しポイント
この論文では、CLIP(contrastive language-image pre-training framework)を使って、ピンボケ画像を鮮明化する方法を提案しています。

画像を鮮明化するためには、まずどこがピンボケしているかを示すボケマップ(blur map)を作成し、そのボケている部分を鮮明化する手法が取られます。ボケマップの作成にはボケマップ判定モデルが必要ですが、既存の研究ではこれを教師あり学習で作成していました。しかし、鮮明な画像とピンボケ画像のペアデータを入手するのは難しく、教師あり学習でボケマップ判定モデルを作成するのは困難でした。
本論文では、CLIPを使ってボケマップの作成を試みています。CLIPは、画像と説明文を結びつけるマルチモーダルモデルで、対応する画像と説明文の類似度を高く、それ以外の組み合わせの類似度を低く学習します。「この辺がぼやけているよ」という文字列とピンボケ画像のペアをCLIPに与えることで、ボケている場所を特定できるのではないか、というのが本論文のメインのアイディアです。

結果的に、1つの画像からではピンボケ部分の正確な推定はできませんでしたが、オートフォーカスに使われるデュアルピクセル画像の左右非対称性(デュアルピクセル画像ではピンボケしている部分は左右視差が大きくなる)を活用してボケマップの作成に成功しました。その後、ボケマップとデュアルピクセル画像をencoder-decoderに投入し、ピンボケ部分を補完した鮮明な画像を生成しました。
この研究では、「CLIPを使えば画像のピンボケ部分がわかるのでは?」というアイディアが非常に面白いと感じました。CLIPに文字列を与えることで、教師なしで必要なモデル(ここではボケマップ判定モデル)を構築できるという発想が、マルチモーダルモデルが普及している2024年の研究らしいと感じました。
EventPS: Real-Time Photometric Stereo Using an Event Camera
- セッション: Medical and Physics-Based Vision (Orals 3C)
- 著者: Bohan Yu, Jieji Ren, Jin Han, Feishi Wang, Jinxiu Liang, Boxin Shi
- 論文リンク: PDF
- 紹介者: 三浦(機械学習エンジニア)
推しポイント
計測対象に様々な方向から光を当てたときの陰影をもとに表面形状(正確には法線)を推定する「照度差ステレオ」を、シーン全体の輝度ではなく明暗の変化だけを記録する「イベントカメラ」と組み合わせることでリアルタイムに実現する、という論文です。一般的なカメラがシーンの全画素を同期的に取得するのに対し、イベントカメラは明暗変化のあった画素を非同期的に取得するため、高速に撮影できることが強みです。一方で、取得できるのは輝度そのものではなく「輝度が変化した」イベントのみで、ここに新しい原理やアルゴリズムを導入する必要があります。

提案手法の概要は上図の通りです。(a) 光源を円周上に回転させながら対象をイベントカメラで撮影すると、(b) 画素ごとに「明るくなった」「暗くなった」というイベントが取得できます。(c) 光源の移動に伴うイベント数と法線の向きとの関係から、(d) 表面の法線を推定できます。原理の直感的な理解としては「カメラに対して傾いている面ほど、光源の移動に伴って輝度変化が大きく、したがってイベント数も多くなる」ことを想像するといいでしょう。
性能評価では、従来の照度差ステレオの手法に比べ、精度に対するデータ量の効率性の点で優れていることを示しています。具体的には、従来手法にて2回の撮影に相当するデータ量で、従来手法にて5〜9回の撮影に相当する精度での計測ができるそうです(照度差ステレオでは一般に、撮影回数を増やすほど計測精度が向上します)。
新しい問題設定を提案したことはもちろん、解法やその原理、数式の展開も順を追って組み立てられており、直感的な理解のための説明も補足されていることで、当該分野に詳しくない読者にも分かりやすい点が素晴らしいです。加えて、実際に構築したシステムによるリアルタイム計測の様子もデモ動画として公開しており、「技術は動かしてナンボ」のデモ好きな私に刺さりました。ちなみにリアルタイム処理のためRustで実装されており、過去にC++とOpenCVで画像処理システムのデモを構築していた身としては、時代の進歩を感じました。
LISA: Reasoning Segmentation via Large Language Model
- セッション: Vision, Language, and Reasoning (Orals 3B)
- 著者: Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, Jiaya Jia
- 論文リンク: PDF
- 紹介者: 農見(機械学習エンジニア)
推しポイント
この論文は複雑な言語処理を必要とする質問 + セマンティックセグメンテーションタスクのベンチマークデータセットを自作して、それに対応できるモデルを作ったという論文です。と言っても分かりづらいと思うので具体例が下になります。

これは質問が画像の中で普通ではない部分はどこという婉曲表現となっています。答えるには言語力と犬の姿の知識が必要で難しいです。ただ、実際のユーザーはこういう表現もすることがあると思うので実用的な研究だな思いました。あとセグメントを示すだけでなく言語生成能力もちゃんとあるのもいいですね。
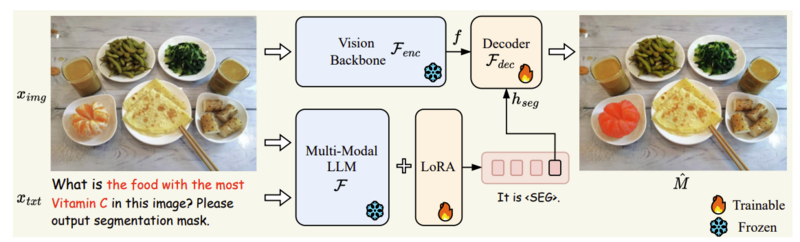
モデルはこんな感じになってます。マルチモーダルLLMにSEGというトークンを出すようにさせて、そのトークンをセグメンテーションのデコーダーに入れる形です。LLMにテキストを生成させて、そのテキストをセグメンテーションモデルに入れるというものよりもE2Eの学習が出来る、テキストより情報量の多いEmbedingというベクトルで渡せられるという点で優れています。また、他のE2Eで学習させる手法より学習コストが低いです。(LISA-7B は 8 × NVIDIA 24G 3090 GPUsで3日弱で学習できる)。学習コスト低い?って思うかもしれないですが、論文中で上げてるのは4×8 NVIDIA 80G A100 GPUsとか使ってるから相対的にですね。
学習にも工夫があり、学習データにはセグメンテーションタスクだけではなくVisual Question Answering という画像と質問を元に回答するタスクも入れて学習することにより、言語生成能力を維持できているそうです。また質問文をChatGPT3.5で言い換えたものを学習データに入れるデータ拡張をすることによっても精度を上げています。
画像と質問を理解してセグメンテーションする能力が発展していけばロボットに自然言語で指示を与えて、そのセグメンテーション部分のものを取ってもらうとかもできそうで夢があるなあと思いました。
CroSel: Cross Selection of Confident Pseudo Labels for Partial-Label Learning
- セッション: Low-Shot, Self-Supervised, SemiSupervised Learning (Orals 5C)
- 著者: Shiyu Tian, Hongxin Wei, Yiqun Wang, Lei Feng
- 論文リンク: PDF
- 紹介者: 大垣 (機械学習エンジニア, グループリーダー)
推しポイント
この論文が解くのは部分ラベル学習という問題設定です。私自身部分ラベル学習の設定を知らなかったので、まず初期の論文Learning from Partial Labelsを参照し、この問題設定を調べました。 こちらの図1にあった例がわかりやすく、映画の映像と脚本のデータがあれば、
- ラベル: 脚本から"このシーンではCharlieとHarleyが話していること"
- 画像: 映像からの顔認識により、"二人の人間の顔画像"
が、得られます。つまり、 "顔画像 -> CharlieまたはHarley "という弱い学習データが得られます。この、"または"が重要で、振られた弱いラベルのうちどれか一つが正しいという問題設定が部分ラベル学習です。

この問題を解くために、部分ラベルから、擬似的な単一の擬似正解ラベルを作り普通のクラス識別問題として解いていくことになるのですが、本研究のキモはその擬似正解ラベルの作り方です。

- 一貫性: 直前t-epochでモデルθが出してきた予測が一貫してる(+ confidenseも高い)ものはその先の教師データとして利用
- モデルθ1で出した予測はθ2の教師データに使う!
- 1だと、すでに一貫した推論ができるデータしか使えないので、最初の不確実な状態から一貫性を高めていく部分は自己教師で学習させる
まず1.のアイディアについて。識別のためのニューラルネットワークを何epochも学習していくのですが、各epochごとに学習データに入っている画像からの推論結果を保存しておきます。その推論結果が、epochを跨いで一貫している場合に、これは正しいラベルを確信した、とみなして、真の学習データとして、その先のepochの正解ラベルとして利用していく、という概念です。
次に2のアイディア、これが面白いところですが、1のアイディアだけだと、自分の予測を使って自分を学習していくことになるので、誤った信念をそのまま引きずるというリスクがあります。なので、モデルを二つ用意し、自分が確信したラベルは片割れの学習のための正解データとして扱うというものです。これ、今回は2つのモデルでやってますが、わりといろんな不安定なラベルの問題に使えると思うのでめちゃめちゃ面白いです。
そして3番目のアイディアはちょっとわかりにくいのですが、1の話はあくまでも推論結果が安定しないと永遠に先に進まないので、推論の安定を目的とする自己教師あり学習を行います。具体的には、ある画像xについて異なるaugmentationを行なったx'とx''を用意し、θ(x')とθ(x'')が近づくようなロスを作るというものです。このアイディアも推論を安定させるための汎用的なアイディアで面白い。
というわけで、この1~3の面白アイディアを入れたら部分ラベル学習という不安定な問題を解けますよーという、わかりやすくアイディア勝負の論文でした。とくに私の推しポイントとしては、これら3つのアイディアは、部分ラベル学習に限らず不安定なラベル(PU学習だったり、ラベリングが信頼できなかったり)での学習に応用できそうなポテンシャルを感じる点です。
We are hiring !!
CVPRの論文の面白さにワクワクする皆さん、エムスリーAI・機械学習チームで一緒に機械学習エンジニアやりましょう!また、学生の皆さん向けには機械学習・MLOpsインターンも募集してます。ぜひ一緒に論文を読みサービス開発していきましょう。
エムスリーでは、コンピュータビジョン・機械学習はもちろん、最新技術へのアンテナが高い仲間を歓迎しています。新卒・中途それぞれの採用、カジュアル面談やインターンも常時募集しています!