本セッションの登壇者
セッション動画
それではcgroup v2で何が変わったのかということで発表させてもらいます。この後に楽しい話がいっぱいあると思うので、私の話はさらっと聞いていただければと思っております。
私、加藤と申します。SNSではTenForwardという名前を使っていて、コンテナ技術を趣味でいろいろ調べています。仕事の方はセキュリティをやっております。
本日の話は、詳しくは技術評論社さんの連載をご覧ください。
技術書展でも本を売っています。ただ、今日お話しする話はまだ本になってないので、連載でご覧ください。
もう少し深く知りたい方はcgroupのカーネルのソースコードリーディングの本も出していますので、よろしくお願いします。
今日お話しする内容は、最近使われるようになってきたcgroup v2について、どういうところが良くなったのかを中心に、カーネルの機能としてお話ししたいと思います。ただ、コンテナエンジンやKubernetesでcgroup v2がどのように使われているかという話はしません。

グループ化する機能もグループになったものもcgroupと呼ぶ
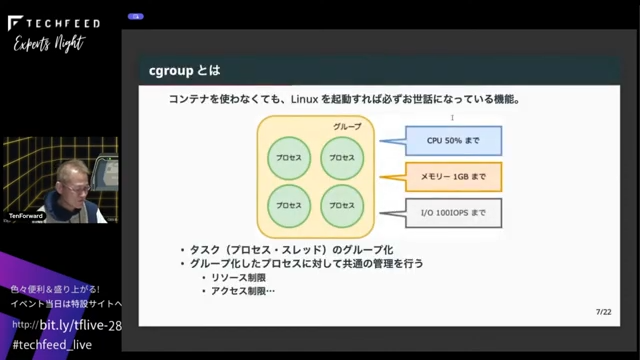
それでは早速cgroupの話をしていきます。cgroup とは何かというと、Linuxを起動するとほぼ必ずお世話になっている機能だと思います。一番重要な機能はタスクのグループ化、つまりLinux上のプロセスやスレッドをグループ化する機能です。そのグループに対して同じ制限をかける機能がcgroupです。
用語なんですけども、cgroup というと、cgroupの機能自体を表す場合と、cgroupで作ったグループのことを指す場合があります。ちょっと混乱しがちなんですけども、こうした2つの意味があります。
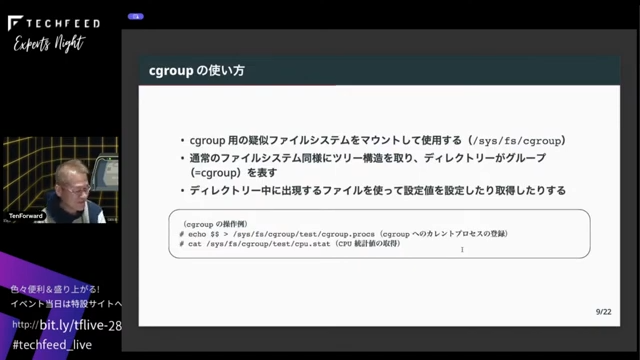
cgroupの使い方ですが、Linuxが起動すると必ず起動してくるsystemdが全部管理するので、手動でcgroupを使うことはありません。裏ではcgroup 用のcgroupfsという特殊な疑似ファイルシステムを/sys/fs/cgroupの下にマウントします。これは普通のファイルシステムと同様にツリー構造を取っていて、ディレクトリがcgroupを表します。ディレクトリを作るとファイルが生えてきて、そのファイルを読んだり書いたりすることで、設定したり、設定値を読み取ったりということをします。
cgroup の構成としては、明確に定義されてはいませんが、cgroup 自体の機能や、グループを作る機能がコアです。CPUやメモリなど各種リソースごとにコントローラーが実装されています。カーネルのコードを読むと、コアはカーネルのcgroup/というディレクトリにあります。コントローラーはそれぞれCPUならスケジュール管理、メモリならメモリ管理のコードの中に分散されて実装されています。
v1の自由度の高さが問題を呼んでいた
cgroup にはv1とv2の2つのバージョンがあります。v1は2007年の2.6.24から、少しずつ機能が充実して、これが今のcgroupのベースになっています。2017年の4.5カーネルでv2が stable になりました。v2が実装された理由は、v1にいろいろ問題点があったからで、作り直そうということでv2が作られました。
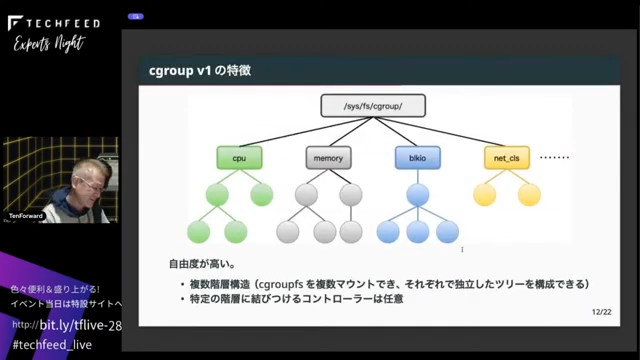
v2で何が良くなったか、何が変わったかを説明するために、比較としてv1の話をします。v1は、自由度が高いことが一番の特徴です。Ubuntu 20.04やRHEL 8ぐらいまではv1を使っていて、CPU、メモリ、I/O、ネットワークなど、コントローラーごとに/sys/fs/cgroupの下にcgroupfsという特殊なファイルシステムをマウントして、その下にツリーを作るという構造になっていました。cgroupfsはシステム上でいくつでもマウントできます。また、CPUとメモリを一緒にする、システム上のすべてのコントローラーを1個のツリーで管理するなどもできました。今ではsystemdが全部cgroup関係の管理を行っています。
v1にはいろいろ問題点がありました。これはまだコンテナが一般的ではない頃にv1が実装され始めたので、汎用性を持たせるために自由度を高く設計したことが一つの理由です。結局いろいろ制限があって自由度の高さは使われませんでした。また、バラバラに少しずつ実装されてきたので、コントローラー間の連携ができていなかったことと、操作感がコントローラーによって違うということがありました。加えて、どのグループにもタスクが所属できるので、親子関係でリソースが競合したり、どういう風にリソース分配したらいいかがよく分からない状態が生まれていました。さらに、すべてのコントローラーがスレッド単位で制御されていて、CPUはスレッド単位で制御する意味があるけれどもメモリはプロセスで全部共有するので、スレッドごとにリソースを分配する意味がないし、そもそもどうやって分配するのかといった問題点がありました。

v2ではツリーが1つに
そこで、新しいものを作ろうということで、v2の実装が始まりました。たしか3.14とか16から始まって、4.5で stable になっています。v2の一番の特徴は、システム上に構成できるツリーが1個だけである点です。なので、/sys/fs/cgroupの下を見ると、そのシステムのcgroupfsツリーは1個だけになります。また、cgroupの実装規約が決められたので、統一感が出てきました。コントローラーもcgroupごとに設定できるようになっています。
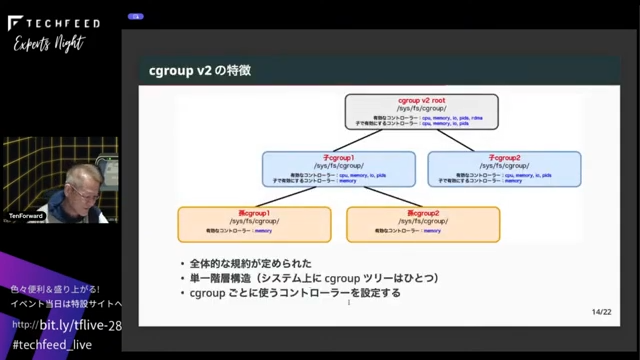
繰り返しになりますが、規約が定められたので操作感が統一されて、cgroupのツリーがシステムに1つなので、ツリー内でコントローラーの制御を行うようになりました。また、ツリーが1個なので、コントローラー間で連携するように実装できるようになっています。cgroup v1では、何個もコントローラーがあってマウントされるかされないか分からないみたいな状態でしたが、v2ではマウントしたら必ず使えるのが前提になっているので、コントローラー間の連携がきちんと取れるようになりました。あと、先ほどスレッド単位でやる意味がないものがたくさんあるという話をしましたが、v2ではプロセス単位で管理するようになっています。ただ、スレッド単位で管理が必要なコントローラーもありますので、別途スレッドモードみたいなのができています。また、親子間でリソースをどう分配したらいいかという問題は、ツリー末端にしかタスクがプロセスに所属できなくなったので問題が起こらなくなりました。

I/O制御ができる、メモリを奪われない、まとめてkill
ここから、私の独断と偏見でいくつか良くなった点をお話しします。
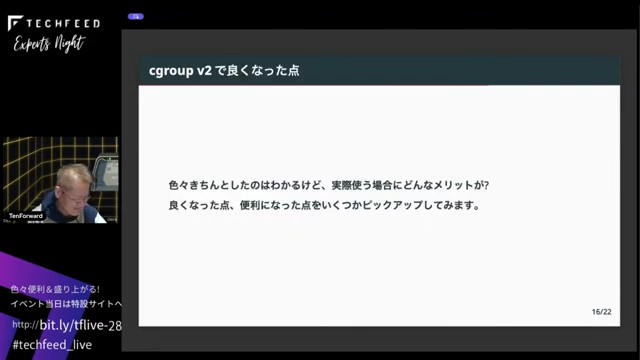
ひとつはI/O制御が効くようになりました。Linuxではディスクからファイルを読むとメモリ上に一度置く必要があります。プロセスはメモリ上のデータを読んで、書く時もメモリに対して書くので、メモリとI/Oのコントローラーが連携する必要がありました。v1ではそれができなかったのに対して、v2ではできるようになっています。v1の時もダイレクトI/Oの時だけはきちんと効いていました。
あと、メモリの最低保証値です。v1ではメモリの上限値は、Kubernatesを使う際にも設定すると思うんですけども、最低このコンテナにはこれだけのメモリを割り当てるという制御ができるようになりました。これを設定しておくとメモリが足りなくなったからと無理やり奪われたりせずに必ずコンテナに割り当てられて、コンテナがちゃんと動くようになります。
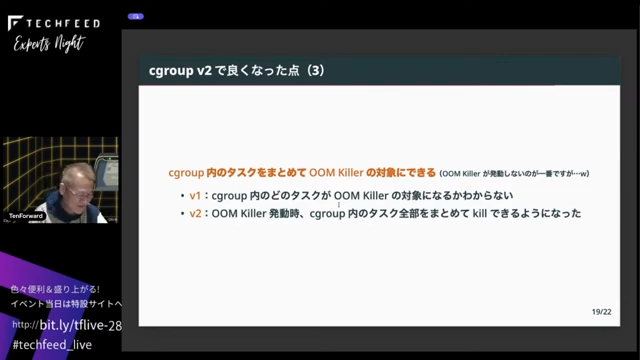
また、これはお世話にならないのが一番なんですけども、メモリが足りなくなったらLinuxではOOM Killerが走ってランダムにタスクがkillされていきます。cgroupでもメモリの上限の制限にかかるとOOM killerでkillされていましたが、v1ではcgroup内のどのタスクがkillされるかはカーネルが決めるので分かりませんでした。ただ、コンテナにたとえばタスクが5つあってその1個だけがkillされたらそのコンテナはちゃんと動くのかという話になるわけです。そういう時のために、仮にOOM Killerが発動した場合はコンテナごとkillする設定ができるようになっています。再度別にコンテナを立ち上げればいいので、その方が安定稼働ができます。
ここまで、良くなった点をセレクトしました。その他変わった点として、v1にあってv2でなくなったコントローラーがあります。たとえばネットワークのパケットにタグを付けて、iptablesでそのタグを指定する機能があったんですけども、そもそもiptablesなどのネットフィルター関係がcgroupを理解するようになってきたので、いらなくなって削除されました。また、eBPFは直接cgroupにアタッチできるようになったので、eBPFで制御するコントローラーがなくなっています。デバイスコントローラーでLinuxデバイスのアクセス制御をやっていたのですが、インターフェースのファイルは先ほどのツリーには出てこなくなって、裏側でBPFのプログラムで制御するようになっています。
まとめです。cgroup v1はまだコンテナがない時代からバラバラに実装されてきたのでいろいろ問題があったんですけども、今はもうcgroupが当たり前でコンテナも当たり前の時代になりましたので、それに向けてv2で書き直されてきちんと動くようになりました。以上がcgroup v2で変わった内容です。ご清聴ありがとうございました。