
本セッションの登壇者
セッション動画
面白法人カヤックでSREをしています、藤原俊一郎(Twitter: @fujiwara)です。個人的な活動として、ecspresso(Amazon ECSのデプロイツール)やlambroll(AWS Lambdaのデプロイツール)を作ったり、先ほどのセッションで登壇された馬場さんと共著で達人が教えるWebパフォーマンスチューニング(通称「ISUCON本」)を出版したりしています。

SRE不在のチームに加わった背景
SREが不在だったチームの例として、弊社のSMOUTというサービスのチームをご紹介します。SMOUTは2018年にリリースされた、移住したい人と移住して来てほしい地域をマッチングするサービスです。コロナ禍の影響もあって移住希望者が増え、登録ユーザ数が伸びています。SMOUTのチームには専任のSREがいませんでした。

このチームに私がSREとして加わることになったきっかけは、SMOUTが利用しているミドルウェア(ElastiCache Redis 3やRDS for PostgreSQL 10)のEoLです。これらのミドルウェアが新バージョンに強制的にアップデートされる前に対応する必要がありましたが、開発チームはサービスの開発/運用で手がいっぱいで対応できない状況でした。ほかにも次のような課題がありました。
- サービスが成長したことで増大したサーバーコストを削減したい
- CIに強すぎる権限がついているので絞りたい
- サービスの安定性を高めたい、監視を整備したい
- 1億行のテーブルから9000万行消してALTERしたい
これらの課題を解決するために2カ月の期間限定でSREとしてチームに加わることになりました。

チームにはそれまで専任のSREは不在でしたが、サービスはとてもよくメンテナンスされていました。
- Railsはリリース当初の5.1から順調に6.1までアップデートされている
- Dependabotによる定期的なアップデートが実施されている
- リリース当初はElastic Beanstalkで構築されていたものが、ECSに置き換わっている
- 手作業でおこなわれてきたインフラ管理がTerraformで管理されている
- デプロイはCircleCI経由で行われている
このように専任のSREはいないものの、やる気も能力もあり、開発/運用チームがちゃんとDevOpsをまわしている状態でした。
今回チームにSREとして加わるにあたって、私は期間限定なのでただ作業を代わりにやってあげるのではなく、せっかくなので今後も使える考え方や手法/SREプラクティスを導入し、私がいなくなったあともこのチームがSREの業務をまわせるようにしようと考えました。

最初にやったこと - Grafana k6による負荷テストシナリオの作成
Grafana k6はOSSの負荷試験ツールで、JavaScriptでシナリオ(HTTPリクエストの送信/レスポンスの確認など)を記述して並列度/実行時間を指定して負荷テストを実行できます。
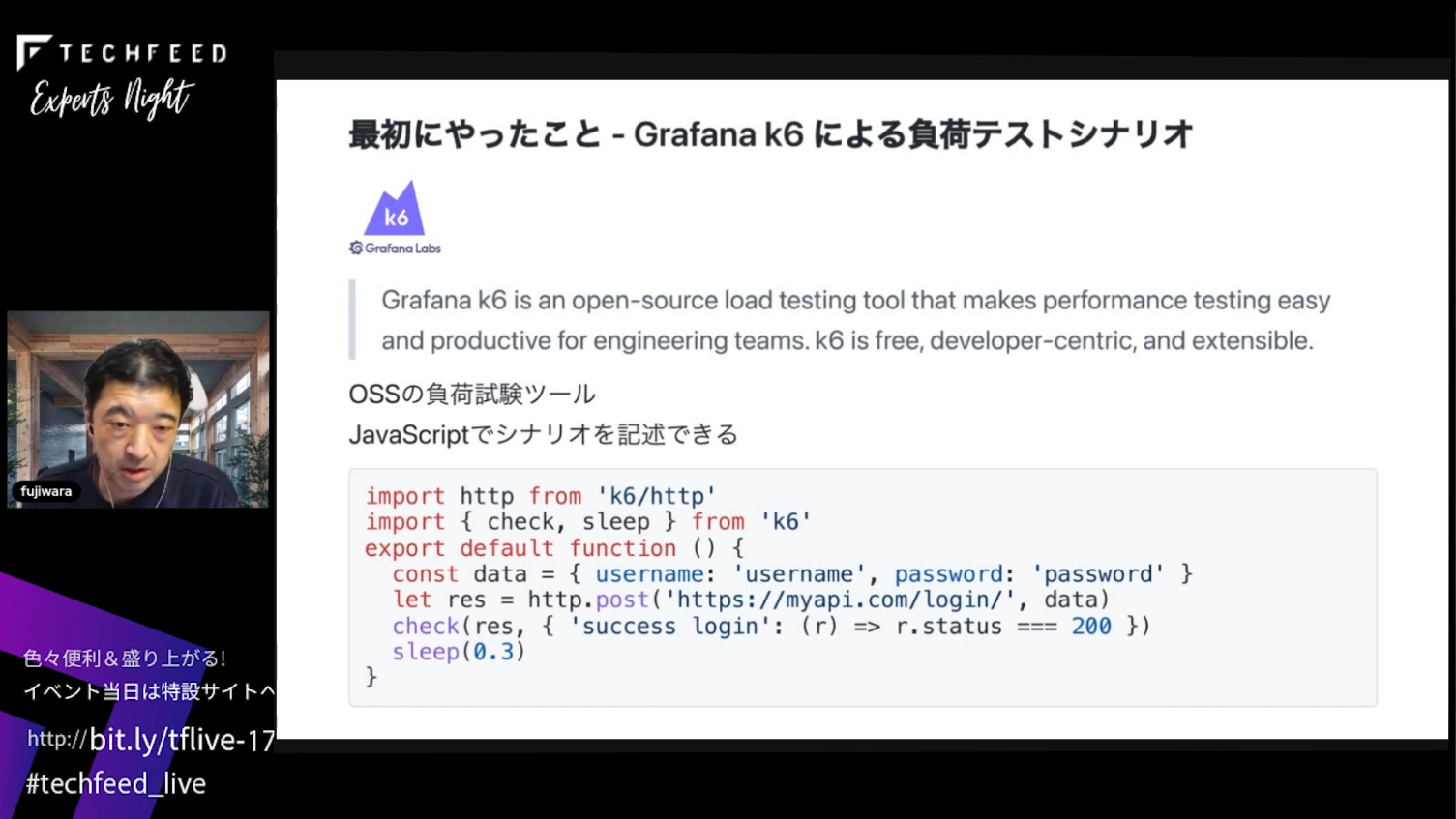
負荷試験ツールを最初に導入した主な理由は、各種サービスのバージョンアップを行うときにRailsアプリケーションの挙動がどのように変わるかわからないので、継続的にアクセスがある状態でFailoverさせたときに正しく動作するか確認するためです。また、サービスの安定性向上やパフォーマンス改善の確認のための負荷テストに使えるように整備しました。
このような負荷試験ツールは非常に便利ですが、負荷テストを実施した経験や知見がないととっつきづらく、とくにこれまでアプリケーションの開発/運用に集中し、パフォーマンスチューニングの経験がないと手を出しにくいものでした。そこで、簡単なサンプルを最初に用意し、チーム内の誰でも利用できるようにしておきました。

用意したシナリオは、次のような簡単なものです。
- トップページにアクセスする
- トップページから呼ばれるAPIを複数並列で呼び出す
- ログインフォームにアクセスする
- ユーザー名とパスワードをPOSTしてログインする
- ログインセッションが必要なAPIを呼び出す
このシナリオは、各コンポーネント(CDN / LB / WebApp / MySQL / Redis)をひと通り通過し、ストレージからの読み込み/書き込み両方の処理をカバーしています。このシナリオを実行しながらFailoverを行うと、各コンポーネントのエラーの発生数と回復時間を検知できます。

負荷試験ツールの導入によるSREの考え方とプラクティスの導入
負荷試験ツールを使ってFailover時の動作を検証した目的は、「不安だからサービス停止メンテナンスを入れましょう」という考え方からの脱却です。サービスがオンラインのままインフラの変更を行う際には、
- どのくらいエラーが起きるかわからない
- どのくらい壊滅的な問題が起きるかわからない (起きないかもしれない)
- 問題が起きたときにどのくらい復旧に時間がかかるかわからない
という不安がつきもので、「怖いので」1時間程度の予告サービス停止をして変更を実施したいということがよくあります。
SMOUTのインフラ変更の際にも予告サービス停止が提案されましたが、「不安だからサービス停止メンテナンスを入れる」の背景は「何が起きるか知らない」ということだけで、知らないから怖いのであれば、何が起きるか試せるようにすればよいのです。
SMOUTには検証/ステージング環境がすでに用意されていたので、これらの環境に負荷をかけた状態でミドルウェアのバージョンアップを行い、実際に何件のエラーが発生したか、何分程度で回復するかを観察しました。また、通常時に発生しているエラー数/頻度とバージョンアップ中のエラー数/頻度を比較して、ユーザーに影響があるか(サービス停止メンテナンスにしたほうがよいか)、オンラインのまま実施してサービスの可用性を高めたほうがよいかを評価しました。これはSREの世界の「エラーバジェット」や「SLO」の考え方につながるものです。

結果的には、本番環境でもk6で負荷をかけながらサービス停止なしで
- ElastiCache Redisのバージョンアップ
- RDS Blue/Green Deploymentsの昇格
を行うことができました。実際にこれらの作業を行うと、ミドルウェアの再起動時などにどうしても接続エラーが発生しますが、この接続エラーを踏む役目をk6が肩代わりし、アプリがミドルウェアに再接続されますので、実際に利用者が目にしたエラーはせいぜい数件程度におさまった(通常時のエラー件数と同程度だった)という効果もありました。

このように負荷試験ツールを導入したことで、今後も使えるSREの手法/考え方をチームに導入することができました。ほかにもチームにいた2カ月の間で行ったことは複数ありますが、今回は時間の都合上割愛します。

まとめ - プラクティスを導入できれば専任SREがいないサービスの運用も改善できる
今回は、専任のSREがいないチームに「エラーバジェット」「SLO」の考え方を導入するために負荷試験ツールを導入した例をご紹介しました。
SREは「エンジニアリング」の手法であり、専任のSREエンジニアだけがやるものではありません。正しく開発/運用ができているチームであれば、SREの手法/プラクティスを取り入れてより良い運用ができるようになります。ソフトウェアで扱える手法であれば、開発/運用担当者にとっても抵抗が少ないので、ここから導入していくのがいいのではないでしょうか。

以上となります。ご清聴ありがとうございました。