
本セッションの登壇者
セッション動画
では、「ChatGPTを使って行われた試行錯誤の事例などに関する話」というテーマで話をさせていただきます。
最初に自己紹介をさせてください。豊田陽介といいます。@youtoyというIDでTwitterをやっています。基本的にプライベートでITイベントの主催や登壇、運営をしています。その活動を行う中で扱った技術に関する共著/単著の本を出版したことがあって、活動について賞をいただいたりもしました。個人的にはガジェットが大好きで、それを使ってIoT関連の試作をしたり、JavaScriptのプログラムで通信/制御をするようなこともやったりします。
ChatGPTに関しては、2022年12月2日から使い始めました。タイミング的にアドベントカレンダーの記事を書く時期で、もともとあったネタを捨ててChatGPTを試して2日目に記事にしました。その後もアドベントカレンダー期間中に、ローコードツールと組み合わせた記事も書いたので、そういうところを見ていただいて本日お声がけいただいたようです。

今日はChatGPTを取り上げて話していきます。
ChatGPTが登場してから現在までの流れ
もうすでにご存知の方もいらっしゃいますし、前のセッションですでに話されているので、ChatGPTが登場してからこれまでの流れについて、公式の記事のタイムスタンプベースで簡単に並べておきます。
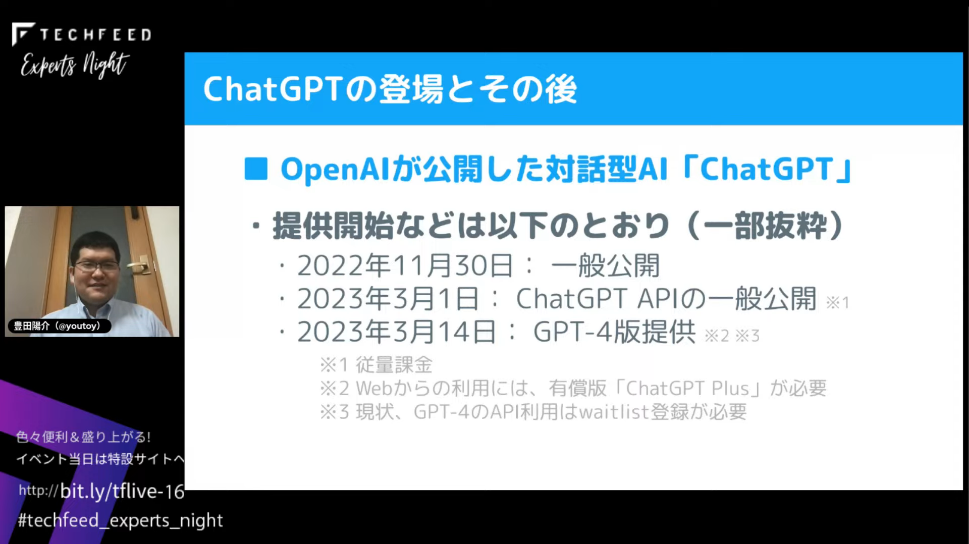
11月30日が一般公開で、日本のSNSでざわざわし始めたのは日本時間の12月1日ごろと記憶しています。私は翌日にさわり始めました。ChatGPTは当初、Web版のみの公開で、API版の公開は3月1日になってからです。3月14日にGPT-4のバージョンが提供されています。
APIに関しては無料枠で使っている方もいらっしゃると思いますが、従量課金制です。GPT-4については、Webから使えるバージョンは有償版のChatGPT Plusに加入していれば選択可能で、APIに関してはウェイトリストに登録をして利用可能にそれを使ってIoT関連の試作をしたり、JavaScriptのプログラムで通信/制御をするようなこともやったりします。私はまだウェイトリストに入っていますが、SNSなどで見ているともう使われている方もいらっしゃる状況だと理解しています。
ChatGPTにさせていること - 機能要件の作成、図の生成、文章要約、ドキュメント添削
個人的には、SNSや記事などで公開されているChatGPTの事例を見て、試行錯誤されている内容やノウハウが共有されているものを試しています。いろいろな情報が共有されている中で、今回は開発系の話に興味のある方が多いと思いますので、開発周りの内容から事例をいくつか抜粋して書いてみました。
ひとつは、大まかな要件のみを記載して、そこから細かな機能要件を作ってもらうというものです。もちろん思ったとおりにはなかなかならないので、出力後に軌道修正をしています。同じ要件を使って、テキストベースで図を生成させている事例もあります。自分で試したり他の方が試されている例を見ても、偶然うまくいったケースなのか定常的にうまくいくケースなのかを判断するにはまだ事例数が少ないのですが、試された方の感想では「抜け漏れを防ぎつつ、自分の作成作業を補助してくれるという点では良いのではないか」といった話が出ていました。一方でやっぱりうまくいかない場合もあるので、そのあたりを修正する必要があったり、内容の複雑さによってはうまくいかないところもあったりというのを観測しています。
また、ある文章をもとにして別の文章にする作文/文章要約の事例もよく見かけます。たとえば、テクニカルサポート系の問い合わせメールを英語で作るときに、おおまかな伝えたい内容から翻訳してメールの文章を作成したり、複合的なテキスト変換処理をいっぺんにやっています。また、たとえば技術系の難しい用語を使うと伝わりにくいと仮定して、「できるだけ専門用語を使わずに内容を説明する」という使い方もあります。自分の視点で書くと、相手がとある用語・意味を知っている前提で文章を書いてしまい、難しすぎて伝わらないことがあります。そのため、自分が書いた元の文章を、相手に合わせて「誰々向けに変換して」のように、難易度や専門用語の有無を変える事例を見かけました。
あとは、ドキュメントやコードの内容添削です。コードの事例についてはエラーが出たときにどんな原因があり得るかを出力させます。コードの事例に関してはたとえば間違いを直すなどもありますが、「長すぎる」など具体的に特定の観点を指定して、その観点に「引っかかる部分を指摘してください、そして修正前/修正後の文章と修正理由を明示的に書いてください」という形で指示します。直した結果だけをもらうのではなくて、なぜ直したのか、どこが悪かったのかを返してもらうという事例も見かけました。このあたりは、人に頼む場合には、相手のリソースを見てお願いする必要があるために、相手の時間に依存して進捗が変わってしまうという問題がなくなるので、こういった事例も非常に良いと思います。

API + ライブラリで外部データ参照の仕組みをつくる
APIを用いた事例も取り上げてみました。このあたりはAPI単体でできることというよりは、APIにプラスアルファの処理を加えた内容になっています。
- 非構造化データから構造化データへの変換 … 元の非構造化データの取り込みにはライブラリを利用して、その変換部分のところでChatGPTを使っています。
- 自前のデータを対象にした仕組み … 今のChatGPTで外部データを取り込む際に、標準機能では扱えない仕組みの部分をライブラリを使って補うことで、自前で持っているデータを参照対象にできるという事例があります。

このあたりは、ChatGPTに限らず、他の大規模言語モデルを使った開発でも、組み合わせて使えるライブラリです。よく見かけるのはLangChainやLlamaIndexですね。自分はまだ踏み込めていない部分ですが、先ほどお話しした外部データを参照する仕組みを作ったという事例の中でよく見かけるように思います。こちらはもともと持っている文章からインデックスを作成して、ChatGPTとの対話で入力される文章もそのインデックスに合うような変換をして、それらを比較する形で実装されるというのを見ています。
GPT-4以降のマルチモーダル対応とPlugins
入力可能なデータは今のところはテキストですが、GPT-4以降では前のセッションのお話にも出ていたマルチモーダル対応が気になっています。現状はテキスト入力以外の仕組みは未提供で、GPT-4はウェイトリストを通ってもAPIの入力にできるのはテキストのみですが、未公開の機能では画像入力にも対応しているというデモが公開されています。
下に載せている画像は公式のGTP-4のページで、画像入力を使ったサンプルが7つ表示されている中から拾ってきました。たとえば一番左は、グラフの横の文字や右側の数字を読み取って理解しないと対応できなような指示を出しても、処理結果を返してくれています。真ん中の例では説明文と図があって、その下に設問が2つあります。そこで書かれている設問の内容に関して、図や説明文を理解して回答させるという例です。最後の例はVGAの見た目なのにLightningケーブルのコネクタに挿さっているように見える画像に関するものです。3つのエリアに分かれた画像があって、それぞれ画像の意味とそれがなぜおもしろいかを説明させるといったことをやっています。

いろいろ活用していく中でテキスト以外の入力も使えるようになると、ドキュメントのテキストのみを処理する用途だけではなく、ドキュメントに図が混じってても活用できます。非常に幅広い使い方ができるようになると思うので、たいへん楽しみです。
また、先ほど「ライブラリを利用して外部データを取り込む」という話をしました。ご存知の方も多いと思いますが、Pluginsというものが出ています。公式で提供されているプラグインはブラウジングとコードインタプリタがあり、外部データをとってきたり、中でPythonが動いたりします。また、公式が出しているプラグイン以外にもサードパーティのサービスと連携できるものが発表されています。こちらも、API経由でのGPT-4利用と同様にウェイトリスト登録が必要で、私は今ウェイトリスト登録中なのでまだ使えるようにはなっていないです。こちらもちょっと気になるところです。
プロンプトは公式のベストプラクティスを推奨
このような事例を見てきた中で、プロンプトにも少し触れておきます。
SNSを見ていると非常に複雑な事例も出ていますが、今まで私が観測してきた範囲や自分で試してきたものに限れば、それほど複雑にしなくても使えています。一番シンプルにまとまっていて個数が少なめのものでは、公式のベストプラクティスが良いと思います。「これはあまり効果的じゃない」「こういうふうにするといい」というのが具体的な例を示しつつ説明されています。英語で書かれていますが、それを日本語化して記事を書かれているものもあり、それらを見てみるのはとても参考になると思います。
もう少し分量が多めで体系立てられている解説資料としては、最近日本語訳が作られて公式にもマージされた「Prompt Engineering Guide」を見てみるのが良いと思います。公式のベストプラクティスと一部は重複するところはありますが、幅広い情報が載っています。

ChatGPTを業務で利用する場合のリスクと注意点
ChatGPTの業務利用を考えたとき、データの扱いは非常に気になるところです。オプトアウトの話などがニュースでも話題になっているので、ご存知の方も多いかと思いますが、現時点ではAPI経由のプロンプトは基本的にChatGPT用の学習データとしては使われず、Web版は除外のための申請をしないと学習に利用されます。それとは別に、そもそも入力したデータがどう保存されてどう扱われるかについても別途定められています。公式サイトを見ると、オプトアウトしていてもデータは一定期間サーバに残るようです。
このあたりは、利用ガイドラインを策定した会社の話が参考になるかと思います。今のところ、クラスメソッドのガイドラインはいろいろな判断材料(原文のどこを見るべきか、考慮すべきリスクなど)が明記されており、データの機密レベルに応じた注意が作られていて、非常に良いと思いました。
また、Azureで OpenAIの言語モデルが利用できるサービスがMicrosoftから出ていて、運用/サービスのレギュレーションなどがChatGPTと異なっている部分があります。そういったデータの扱われ方/運用などのレギュレーションの違いといった注意を払うべき部分は、公式の一次情報を見るのが重要です。とくに、データの扱いに関する規定/要件が厳しい状況で利用する場合は、気をつけたほうが良い部分だと思われます。

まとめ - 現在も試行錯誤を継続中
時間がなくなってきたので、最後に自分が試したことを抜粋します。
- イベント登壇時のタイトルのアイデア出し、資料や話の流れの整理 … 抜け漏れの確認や自分の考え付かない案を出してもらうなどをしています。
- ソースコード生成 … JavaScript、Node.js系、IoT周りを少し試してみたり、特定の用途を仮定して、ゼロから自分で考えるのでなくベースとなる処理を生成させたらどうなるかを試しています。
- API … Slack、Discord、LINEに実装してみたり、ブラウザで動く音声認識や音声合成でと組み合わせて、ChatGPTと声でやりとりするというのを試してみたりしました。

ChatGPTの活用に関する話は、まだ情報が続々と出てきているので、自分が思いついた内容で効果的な使い方を見つけられないかを試しつつ、他の方のやり方も見ながら試行錯誤するのを引き続きやっていければと思っています。

以上です。ありがとうございました。