
7月3日、n8nが「LLM Tool Calling Error Handling: Retries and Fallbacks」と題した記事を公開した。LLMがツールを呼び出す際のエラーを本番環境で適切に処理するためのリトライ・フォールバック・サーキットブレーカー設計について詳しく紹介されている。
開発環境でAIエージェントが外部APIを呼び出す処理はスムーズに動く。しかし本番環境では話が変わる。エラーハンドリングをモデル任せにしたまま運用すると、接続先サービスが少し揺らいだだけでパイプライン全体が落ちる。
本記事が提唱するのは「多層防衛戦略」だ。概念的には「インフラ起因の一時障害はワークフロー基盤側で吸収し、ペイロードやロジックに起因する問題はモデル側で解釈・修正する」という二層構造になっている。具体的には、失敗の種類を4カテゴリに分類したうえで、オーケストレーション層(ワークフロー基盤側)とLLM層(モデル側)にそれぞれ適切な責任を割り当てることが核心にある。
失敗の種類で回復責任を分ける
ツール呼び出しの失敗を「なんでもリトライ」で処理しようとするのが、本番エージェントが壊れる最速の原因のひとつだ。記事では失敗を以下の4カテゴリに整理している。
| カテゴリ | 例 | 回復責任 |
|---|---|---|
| トランスポート・ネットワーク障害 | TCP切断、DNS解決タイムアウト、503 | オーケストレーション層(LLMに知らせない) |
| 外部サービスエラー | 429 Too Many Requests、500 Internal Server Error | オーケストレーション層(Retry-Afterヘッダーを解釈) |
| 入力バリデーション失敗 | スキーマ不一致、400 Bad Request | LLM層(モデルがエラーを読んで修正リクエストを生成) |
| ロジックエラー・予期しない出力形式 | ゼロ件レスポンス、不正なJSON | LLM層(モデルが実行パスを変更または人間にエスカレーション) |
インフラ起因の一時的な問題はモデルに見せない、逆にペイロード自体が壊れている場合はオーケストレーション層では修正できない——この原則で責任の境界を引くことが設計の起点になる。
リトライ設計の核心:指数バックオフ+フルジッター
トランスポート障害やレート制限への対処として、記事が「本番標準」と位置づけるのが指数バックオフ(Exponential Backoff)+フルジッター(Full Jitter)の組み合わせだ。
指数バックオフだけだと、複数のエージェントが同じタイミングでリトライを束ねて「サンダリングハード問題(thundering herd)」を引き起こす。ここにランダムな遅延(ジッター)を加えることで、リトライの集中を分散させる。
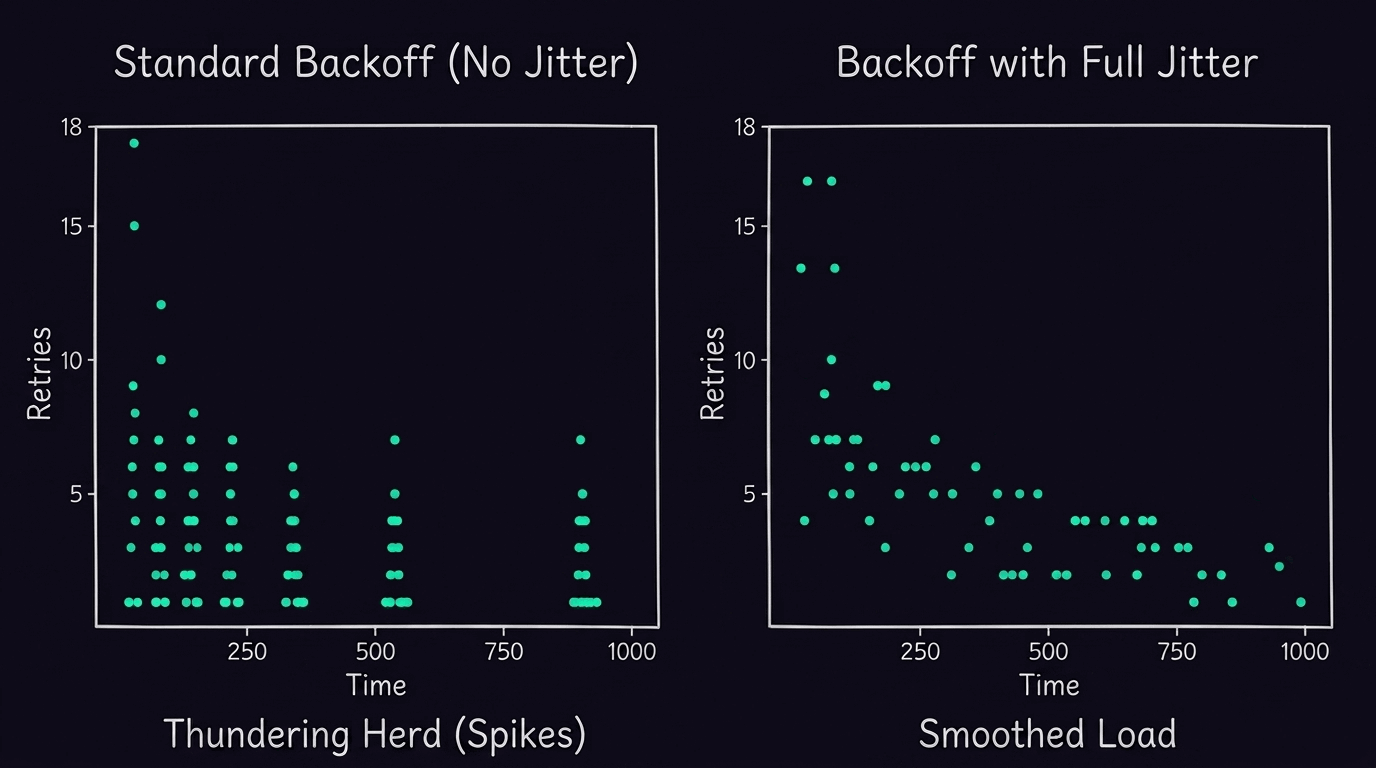
ジッターなしの指数バックオフは依然としてスパイクを生む。ランダム遅延を加えると負荷が平滑化される。出典: AWS Architecture Blog
また、サードパーティAPIが返すRetry-Afterヘッダーを必ず解析し、デフォルトの待機間隔を上書きする実装も必須だとされている。
本番で使うフォールバックパターン6選
記事はシステムレベルのリトライが失敗した後の多層フォールバック設計を具体的に列挙している。
1. エラーをツール結果として構造化して返す
例外が発生したとき実行を止めるのではなく、エラーをクリーンな構造化文字列に整形してツール結果としてモデルに返す。モデルはエラー内容をデータとして読み、次の行動を自律的に決定できる。
2. 存在しないツール名・スキーマ不一致のハンドリング
LLMは稀に定義されていないツール名を呼び出したり、無効なJSONスキーマのペイロードを生成したりする。オーケストレーション層がこれを捕捉し、会話履歴に修正フィードバックを注入する流れが有効だ。
[LLM が存在しないツール "Fetch_User_Data_v2" を呼び出す]
↓
[オーケストレーション層がエラーを捉え、システムメッセージを追記]
"Error: Tool 'Fetch_User_Data_v2' does not exist.
Available tools are: ['get_user_profile', 'update_user']."
↓
[LLM が修正コンテキストを読み、'get_user_profile' を正しく呼び出す]
3. モデルの回復ループに上限を設ける
エラーを見て自律的にリトライするエージェントは強力だが、持続的なロジックエラーに当たると同じ壊れたツールを延々と呼び続けてトークン予算を消費し尽くすリスクがある。記事は最大3回を目安にハードカウンターを設けてループを切断し、明示的なアラートを上げる設計を推奨している。
4. モデルおよびツールのフォールバックチェーン
プライマリのLLMがダウンした場合、セカンダリのクラウドプロバイダーやローカルOSSモデルに実行コンテキストを切り替える。ツール層でも同様で、プライマリCRMツールが失敗し続ければセカンダリDBツールにルーティングする。
5. グレースフルデグラデーション(段階的劣化)
翻訳ツールが失敗したとき、レポート生成ジョブ全体を落とす必要はない。翻訳モジュールが一時利用不可であることをノートとして付記し、ネイティブ言語で成果物を出力するよう指示する。空のエラーページよりも部分的に完成した高価値の成果物を返す方が常に優れている、というのが記事の立場だ。
6. サーキットブレーカー
長時間の外部障害時に自動リトライを打ち続けるとネットワークリソースを無駄に消費し、タイムアウト待機でシステムが停滞する。サーキットブレーカーパターンはこの問題を解決する分散ステートマシンで、連続失敗を追跡して障害中の依存サービスへのリクエストを遮断し、復旧確認後に再開する。
状態は3つに分類される。Closed(通常)はリクエストを通す通常状態、Open(遮断)は連続失敗が閾値を超えてリクエストを即時拒否する状態、Half-Open(探索)はOpenから一定時間後に少数のリクエストを試験的に通して回復を確認する状態だ。回復確認が成功すればClosedに戻り、失敗すればOpenに戻る。
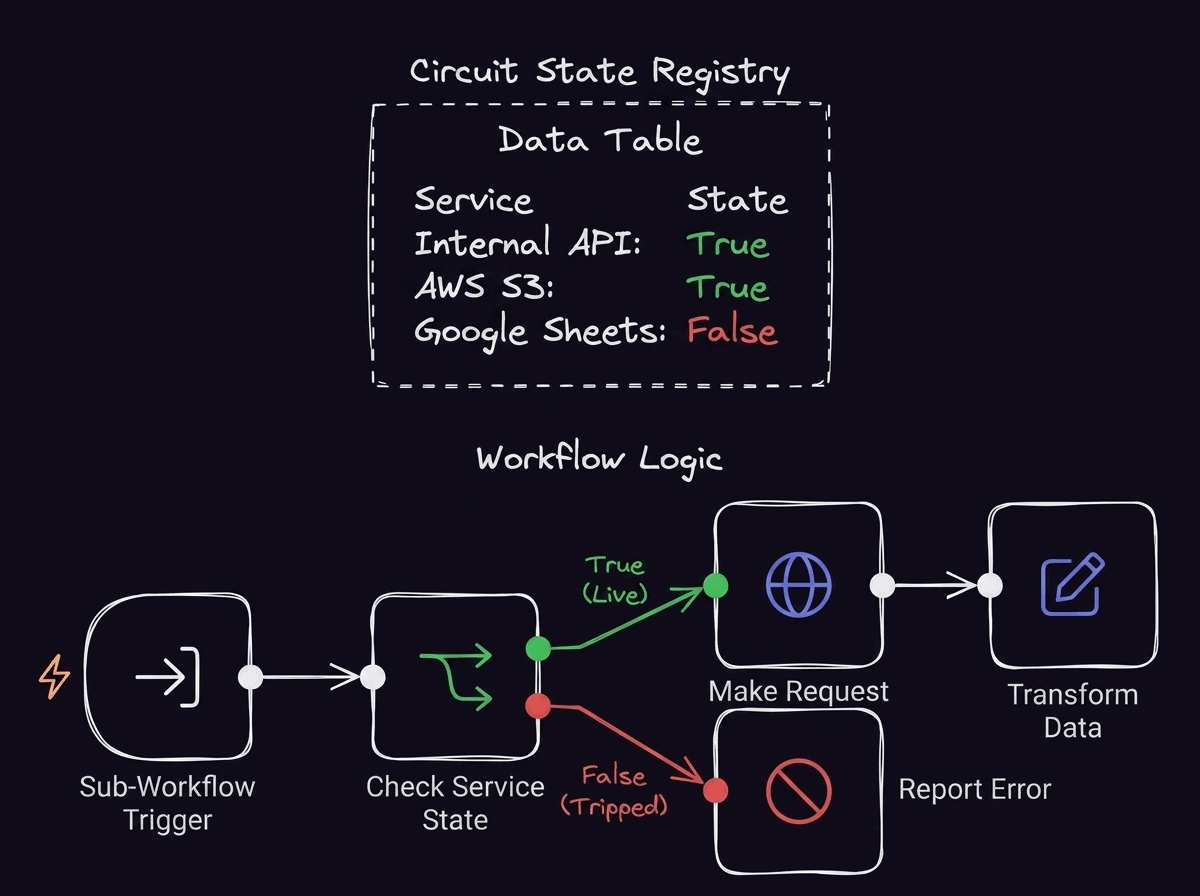
n8nではサービスの状態レジストリをData Tableに保持し、APIコール前に死活確認を挟むことでサーキットブレーカーをビジュアルキャンバス上に実装できる
n8nでの実装:3つのコア機能
記事後半はn8nの具体的な実装方法に踏み込んでいる。ツールをサブワークフローに包むことが完全実装の前提条件として挙げられており、以下の3機能を組み合わせる構成が示されている。
- ノードレベルのリトライ設定: 各ノードの設定で最大試行回数と待機時間を定義。上級のリトライ戦略にはループ付きIFノードを使う。
- エラーワークフローと条件分岐フォールバック: ノードの明示的なエラーパスをIF/Switchノードに繋ぎ、バックアップサブワークフローや代替ツールへ動的にルーティング。
- 失敗したツール呼び出しの可視化: ビジュアル実行トレースで入力パラメーター、生のJSONペイロード、HTTPステータスコードを一覧できる。ただし、モデル側の隠れた推論トレースの完全な可視化にはLangSmith等の外部テレメトリ層が必要と明記されている。
詳細はLLM Tool Calling Error Handling: Retries and Fallbacksを参照していただきたい。