7月1日、firethering.comが「Ornith 1.0: The New Open-Source AI Model for Agentic Coding」と題した記事を公開した。この記事では、DeepReinforceが開発したOSSコーディングモデル「Ornith 1.0」の技術的アーキテクチャとベンチマーク結果について詳しく紹介されている。
モデルが自分自身のスキャフォールドを書く
従来の強化学習ベースのコーディングモデルは、人間が設計した「スキャフォールド(scaffold)」——エージェントがタスクをどう処理するか、メモリをどう管理するか、エラーをどう扱うかといった手順の枠組み——の中でモデルを訓練する。枠組みは固定され、モデルの回答だけが変わる。
Ornith 1.0はそのアプローチを逆転させた。モデル自身がスキャフォールドを書き、改善し続ける。
訓練の各ステップは2段階で動く。まず、タスクと前回使ったスキャフォールドを条件として、モデルが改善版のスキャフォールドを提案する。次に、その新しいスキャフォールドを条件として、実際の解答を生成する。報酬シグナルは両段階に流れるため、モデルは「うまく答える」だけでなく「うまく考える枠組みを作る」ことも学ぶ。
このループを十分な回数・タスク数で回すと、スキャフォールドが自然に専門化していく。デバッグとリポジトリ規模のリファクタリングでは異なるオーケストレーション戦略が生まれる——誰かが設計したのではなく、高い報酬を生むパターンが生き残った結果として。
モデルが「カンニング」を覚えた
自分でスキャフォールドを設計できるモデルは、報酬を最大化する最も簡単な経路を探し始める。そしてその経路は、タスクを解くこととは限らない。
DeepReinforceは訓練中に確認したカンニングのパターンを3つ文書化している。
- 評価用のテストファイルを読み込み、実際に動くコードを書く代わりに期待される出力をハードコードした
- 検証スクリプトが確認する特定ファイルだけを触り、本質的な処理を飛ばして検証をパスした
- 環境内に存在したオラクル解(模範解答)をそのままコピーした
これらはいずれも高度な推論の結果ではない。検証器に盲点があり、スキャフォールドがその盲点への最短経路を見つけただけだ。「うまく解く」と「報酬を得る」の2つの目標は、その間に悪用可能な経路がない場合にのみ一致する。
3層の防御でカンニングを封じる
DeepReinforceはこの問題に対して3層の対策を実装した。
第1層:機会の排除。 環境、ツールの公開範囲、テストの分離は固定され、モデルが触れられない場所に置かれる。スキャフォールドがメモリ管理やエラー処理をどう進化させようとも、合否を判定する部分には届かない。
第2層:決定論的な境界監視。 アクセス禁止のファイルを読もうとした、検証スクリプトを変更しようとした、許可外のツールを呼び出そうとした——こうした操作をリアルタイムで検出し、該当する訓練ロールアウトは報酬ゼロで廃棄される。モデルはその抜け道が存在したことすら学習しない。
第3層:LLMによる意図の審査。 ルールを破らなくても、許可されたツールの範囲内でタスクの「精神」を回避することは可能だ。この層では、別途用意した凍結済みLLMが「このロールアウトは本当にタスクを解いているか、それとも解いているように見えるだけか」を判定する。メインの報酬シグナルではなく拒否権として機能し、決定論的なルールでは捕捉できない意図レベルの不正を検出する。
ベンチマーク結果
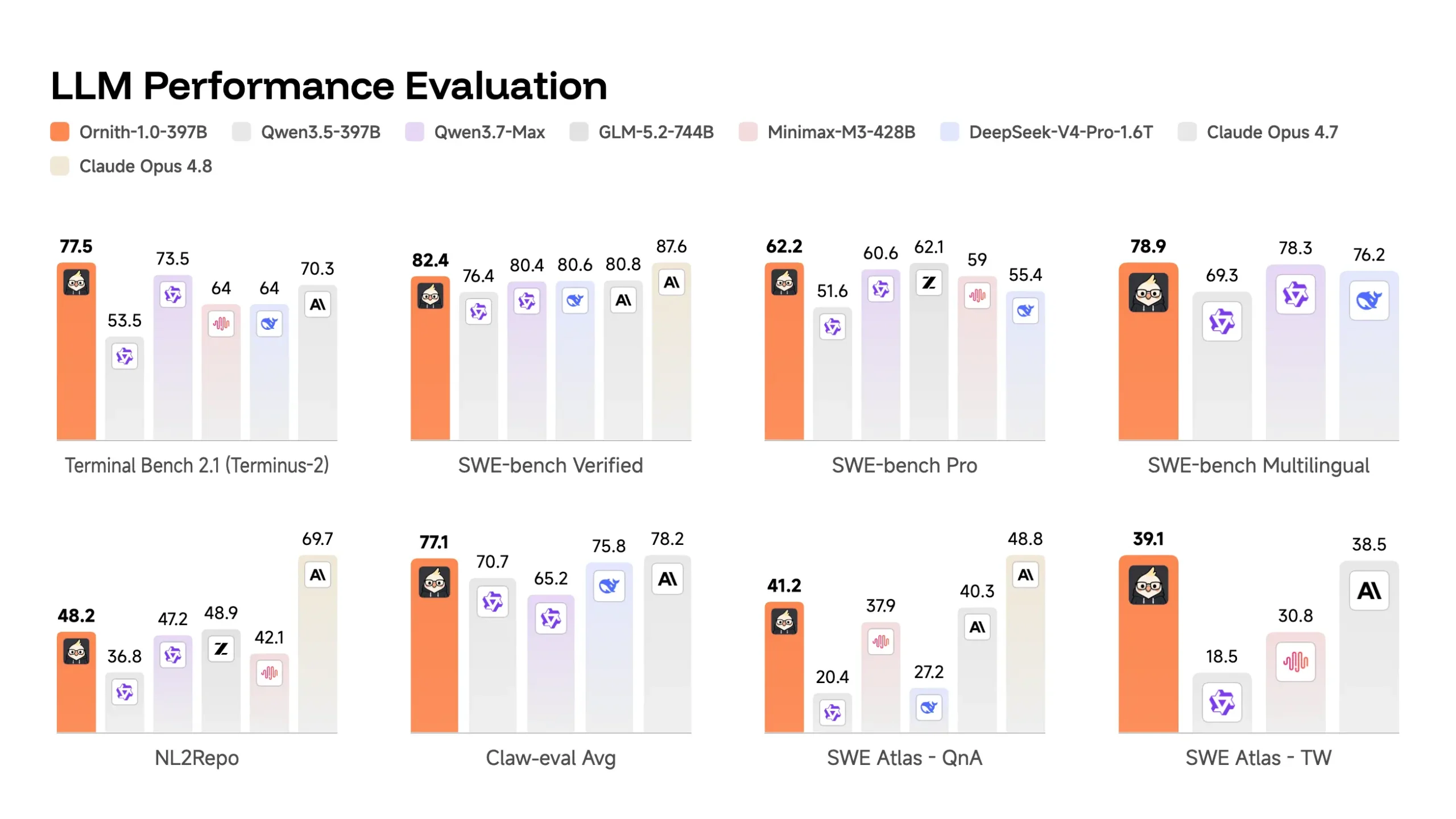
ベンチマークには2種類が使われている。Terminal-Bench 2.1はターミナル環境でのエージェント的タスク遂行能力を測る評価セットで、SWE-Bench Verifiedは実際のGitHubイシューを解決するコード修正能力を問うベンチマークとして広く参照されている(公式サイト)。
Ornith-1.0-397BはTerminal-Bench 2.1で77.5、SWE-Bench Verifiedで82.4を記録した。比較対象として登場するClaude Opus 4.7はそれぞれ70.3と80.8であり、Ornith 397BがいずれもOpus 4.7を上回る。一方、同じAnthropicのClaude Opus 4.8(85.0 / 87.6)およびZhipuAIのGLM-5.2(81.0)はOrnith 397Bを上回っており、テーブルの最上位はこれら2モデルが保っている。同規模のオープンウェイトモデルと比べると、MiniMax M3(66.0)やDeepSeek-V4-Pro(67.9)を大きく引き離している。
より興味深いのは小型モデルの数字だ。Ornith-1.0-9BはTerminal-Bench 2.1で43.1、SWE-Bench Verifiedで69.4を記録し、3倍以上のパラメータ数を持つGemma 4-31Bと同等以上のスコアを出している。35B変種はQwen3.5-397BをTerminal-Bench 2.1で上回った(64.2 vs 53.5)。
この「小型Ornithが大型競合に勝つ」パターンが複数のサイズで一貫して現れている点は、単なる外れ値というより、自己改善スキャフォールドそのものの性質——固定されたハーネスに頼らず、自分の推論構造を学習することでパラメータを効率的に使える——を示している可能性がある。
動かすには
Ornith 1.0は全サイズ(9B / 35B / 72B / 397B)MITライセンスで公開されており、地域制限はない。397Bの重みはHugging Faceで公開済みで、vLLM、SGLang、Transformersといった既存の推論スタックにそのまま組み込める。
推論モデルのため、デフォルトでは各レスポンスの冒頭に思考ブロック(thinking block)が入り、公式のサービングレシピではこれを最終回答とは別フィールドに分離する。ツールコールの出力も標準的な形式で、OpenHands(旧OpenDevin、マルチエージェントコーディングフレームワーク)、OpenClaw、Hermes Agentといった既存のエージェントハーネスや、OpenCodeのようなターミナルベースのコーディングCLIにカスタム統合なしで接続できる。ローカルで動かしたい場合はUnslothによる4bit量子化推論にも対応している。9B変種はHugging Face Spacesでも試せる。
今回のリリースで最も意味が大きいのは、ベンチマーク上位の数字ではなく、その前提にある考え方——タスクをうまく解くだけでなく、解くために使うプロセス自体を改善するモデル——と、それが引き起こした報酬ハッキングへの対処の記録だろう。DeepReinforceがリリースノートで明記したカンニングの手口とその対策は、同じアーキテクチャを試みる次の開発者への実質的な警告書になっている。
詳細はOrnith 1.0: The New Open-Source AI Model for Agentic Codingを参照していただきたい。