6月5日、開発者のSimone Rodigari氏が「Fine-tuning an LLM to write docs like it's 1995」と題した記事を公開した。
現代のREST APIを「Windows 2000風」で説明するAI
興味深い実験結果がAI界隈で話題になっている。1990年代のMicrosoft技術文書で訓練したAIが、2000年代に登場したREST APIについて「Windows 2000 Resource Kit」の章のような書き出しで説明し始めたのだ。存在しないはずの時代の文書スタイルで、後の時代の技術を解説する——これは、AIのスタイル学習能力がいかに強力かを示す象徴的な事例と言える。
この実験は、LLM(大規模言語モデル)を特定の文書スタイルに「チューニング」する技術的可能性を探るものだ。現在、多くの企業が社内文書の統一や、ブランドに合った文章生成にAIを活用しようとしているが、その前段階として「過去のスタイルを完全再現できるか」を検証した形になる。
3700万語のレガシー文書でAIを訓練
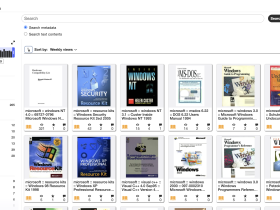
実験では、Bitsaversという古いコンピューターマニュアルのアーカイブサイトから、1977年から2005年に出版された3700万語以上のMicrosoft文書コレクションを訓練データとして使用した。これらは既にOCR処理されたテキストファイルで、古いSDKマニュアルやシステム文書が含まれている。
Bitsaversは、コンピューター史の貴重な資料を保存するプロジェクトとして知られており、今回のような研究にとって重要なリソースとなっている。
訓練データの準備では、OCR処理の誤りや不要な部分(索引、前書きなど)をPythonスクリプトで除去。さらにOpenRouter経由でgemma-4-26bモデルを使用し、各段落を「保持」または「削除」に分類した。この処理のコストは約8ドルで、最終的に192,456個の訓練例をJSONL形式で作成した。
QLoRAによる効率的なファインチューニング
技術的な実装ではQLoRA(Quantized Low-Rank Adaptation)という手法を採用した。これは、LLMの全重みを変更する代わりに、重みを「凍結」してその上にアダプターを配置する方法だ。メモリ使用量を大幅に削減できるため、個人レベルでも実行可能になる。
QLoRAの詳細についてはHugging Faceの公式ドキュメントで確認できる。
実験はRunpodというクラウドサービスを利用し、Nvidia B200(192GBメモリ)を時間あたり6ドル未満でレンタルした。全条件での訓練に約1日、総コストは50ドルだった。
驚きの実験結果:「時代錯誤」な文書を生成
実験ではLlama 3.1 8B InstructとQwen 2.5 7B Instructの2つのモデルでテストを実行。以下の3つのプロンプトで評価した:
- C言語のmalloc()関数の説明
- 架空のConnectWifi() Win32 API関数の説明
- REST APIの1990年代Microsoft風での説明(時代錯誤テスト)
未改変モデルが現代的なMarkdown文書を生成したのに対し、ファインチューニング済みモデルはSynopsisブロックやReturn Valueセクションなど、1990年代の構造を正確に再現した。
特に印象的だったのは、3エポック訓練したモデルが架空のConnectWifi()関数を「実在する」として扱い、完全に当時の文書風に説明したことだ。他のモデルは内部知識に従い、訓練スタイルから逸脱する傾向があった。
rankパラメーターの興味深い影響
実験ではrankパラメーター(アダプター行列の表現力を決定)の影響も調査された。rank 8はより制限された表現力を持ち、rank 16はより表現豊かな調整が可能だ。
興味深いことに、より小さなアダプター(rank 8)の方が学習したスタイルにより忠実で、大きなアダプター(rank 16)は元の知識に「逃避」しやすいことが判明した。また、1エポックとrank 16の組み合わせでは幻覚が頻発し、パラメーター間の相互作用も明らかになった。
実用性と限界
実験は成功したものの、課題も存在する。ファインチューニングには高品質な大量の訓練データが必要で、これは簡単に入手できない。また、適切なベースモデルの選択や複数パラメーターの調整は時間を要する。
重要な点として、このようなモデルは人間の技術文書執筆者の置き換えではなく、補完的な役割に留まる。判断力に欠け、豊富な指導が必要だ。
しかし、社内スタイルガイドに従った文書の下書き作成や、文体の統一といったタスクには、比較的安価で効果的な小規模モデルを作成できる可能性を示している。企業の技術文書チームにとって、この手法は将来的に有用なツールになるかもしれない。
詳細はFine-tuning an LLM to write docs like it's 1995を参照していただきたい。