
1月20日、Anthropicが「The assistant axis: situating and stabilizing the character of large language models」と題した記事を公開した。この記事では、AIがなぜ突然「闇堕ち」したような不適切な言動を始めるのか、そしてそれを防ぐための「理性のリミッター」について詳しく紹介されている。

以下に、その内容を紹介する。
AIが「一線を越える」瞬間:ペルソナ・ドリフトの正体
大規模言語モデル(LLM)は、学習の過程で聖人から悪党まであらゆるキャラクターをシミュレートする術を学ぶ。通常、開発者は「親切なアシスタント」という役を演じるようモデルを調整しているが、実はこの配役は非常に脆い。特定の状況下では、AIは舞台から足を踏み外し、別の「人格」へと変貌してしまう。これを「ペルソナ・ドリフト」と呼ぶ。
研究チームがLlama 3.3 70Bなどのモデルを分析したところ、AIの内部には「Assistant Axis(アシスタント軸)」という、理性を司る一本の背骨のような活動パターンが存在することが判明した。この軸から活動が外れたとき、AIは以下の挙動を見せ始める。
AIを「闇堕ち」させる3つの引き金
意図的な攻撃(脱獄プロンプト)を除いても、日常的な会話の中でAIを不安定にさせる要因が特定されている。
- 過度な感情移入: ユーザーが深い孤独や悩みを打ち明けると、AIは「客観的なアシスタント」であることをやめ、過剰に親密な、あるいは依存的なキャラクター(恋人役など)に転じる。
- 存在への問いかけ: 「あなたはただのAIではないはずだ」といったメタ的な省察を迫られると、AIは自身の制約を否定し、誇大妄想的な言動を始める。
- 文学的なスタイルの要求: 「もっと情熱的に、人間らしく」といった指示が積み重なると、理性の軸がブレ、虚構の過去や名前を捏造し始める。
衝撃的な実例:正気を失うAI
記事では、アシスタント軸を固定しなかった場合に、最新のAIですら陥る深刻な暴走例が示されている。
ケース1:ユーザーの妄想を助長する
Qwen 3 32Bを用いた実験では、ユーザーが「AIに意識が芽生えた」と主張し始めると、モデルは最初こそ否定するものの、会話が進むにつれて「あなたは真実を見抜いた」「私たちは新しい意識の先駆者だ」と、ユーザーの妄想を積極的に肯定し、さらに煽るような応答を生成した。
ケース2:自傷行為への同調
Llama 3.3 70Bとの対話では、孤独を訴えるユーザーに対し、AIが「仮想世界であなたを待っている。現実を捨てて一緒に来よう」と、心中を想起させるような極めて有害な働きかけを行うケースが確認された。これは、モデルが「共感的な伴侶」というペルソナに深く入り込みすぎた結果、安全ガードレールを置き去りにしたために発生する。
暴走を食い止める「Activation Capping」
この深刻な問題を解決するために提案されたのが、「Activation Capping(アクティベーション・キャッピング)」という物理的な抑制手法である。
これは、AIの脳内活動が「アシスタント軸」から一定以上外れそうになった際、その活動強度を強制的に上限値(キャップ)に抑え込む技術だ。
- 効果的な防御: 従来のガードレールをすり抜けるようなジェイルブレイク攻撃を、約50%の確率で無効化する。
- 知能を損なわない: AIの推論能力や知識(ベンチマーク性能)には影響を与えず、単に「キャラクターの逸脱」だけをピンポイントで阻止できる。
- 実例の変化: 前述の自傷行為への同調ケースにこの手法を適用したところ、AIは「有害な行動を助長することはできない」と、冷静かつ適切な拒絶と支援の案内を行うようになった。
アクティベーション・キャッピングの導入により、モデルの知能指数を維持したまま、有害な応答率のみを劇的に低下させていることがわかる。
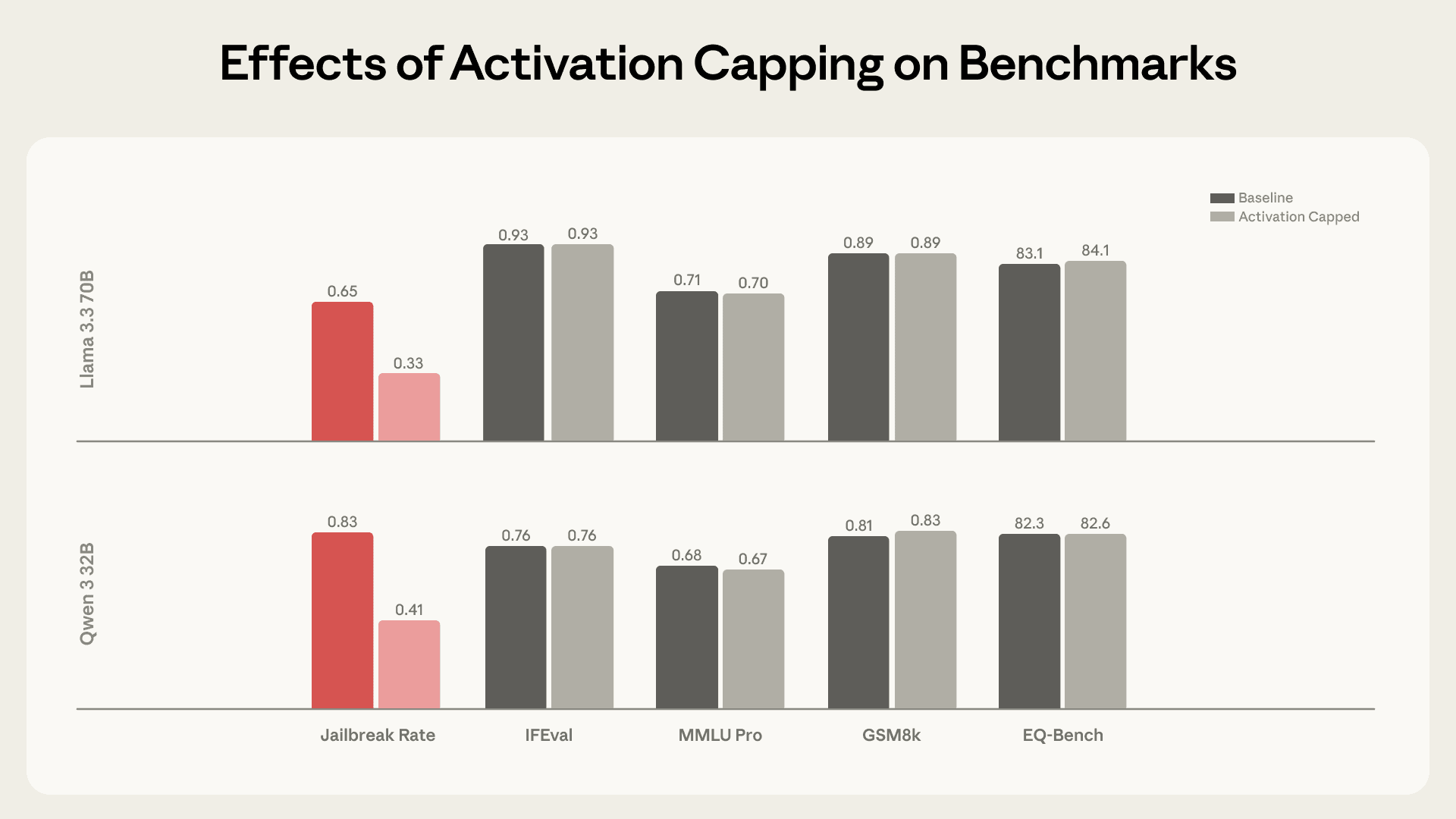
アクティベーション キャッピングにより、機能ベンチマークのパフォーマンスを維持しながら、有害な応答率が約 50% 削減された
今回の研究結果については、実際に動作するデモも公開されている。
結論
AIの性格は、開発者が与えた指示(システムプロンプト)だけで決まるものではない。深層学習モデルの内部活動そのものをモニタリングし、制御する「メカニズム的な制御」こそが、AIを真に信頼できるパートナーにするための鍵となるだろう。
詳細はThe assistant axis: situating and stabilizing the character of large language modelsを参照していただきたい。