
10月24日、単一コントローラモデルに基づく新しい分散プログラミング基盤「PyTorch Monarch」がリリースされた。Monahchを用いると、単一マシンのPyTorchの開発体験をそのまま大規模GPUクラスターへ拡張することができる。

以下に、その内容を紹介する。
背景:マルチコントローラから単一コントローラへ
従来のPyTorch分散実行は、HPC起源のマルチコントローラ(SPMD)モデルが中心であり、各ノードが局所状態に基づいて振る舞いを決めるため、非同期・部分的な故障・RL後処理のような動的ワークロードでは、実装が複雑になりやすかった。Monarchは単一コントローラのプログラミングモデルへ転換し、1つのPythonスクリプトからクラスタ全体を指揮する。クラス・関数・ループ・タスク・FutureなどのPythonネイティブ構成要素で分散アルゴリズムを自然に表現できる点が特徴である。
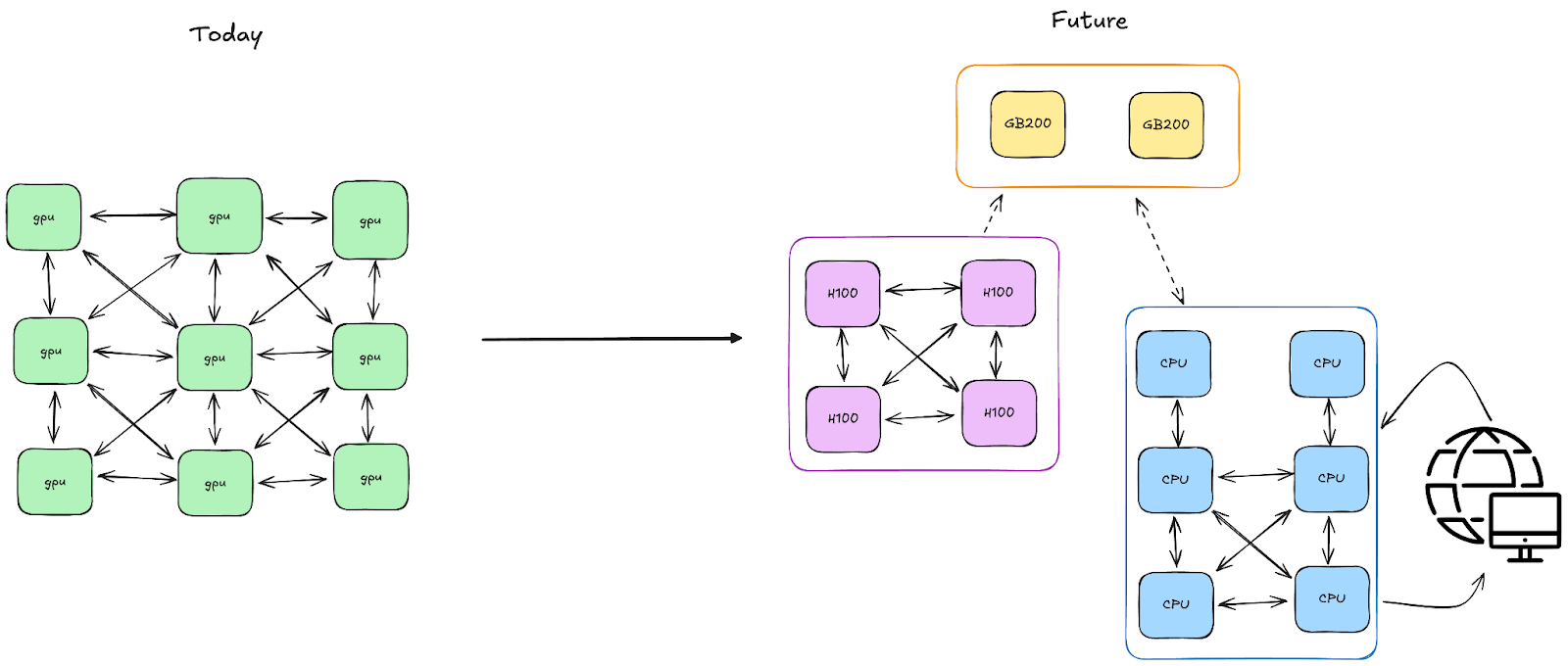
4つの特徴
- クラスタを配列のように扱う。 「メッシュ(mesh)」としてホスト・プロセス・アクタを多次元配列に整理し、API呼び出しをベクトル化して一括操作できる。
- 段階的フォールトハンドリング。 まずは「失敗しない前提」で直感的に書き、必要箇所だけ例外処理を段階的に追加できる。
- 制御とデータの分離。 メッセージングの制御プレーンと、RDMAを用いたデータプレーンを分離し、GPU間の直接転送を可能にする。
- ローカルのように扱える分散テンソル。 PyTorchと統合した分散テンソルを提供し、ローカル演算の感覚で数千GPU規模に拡張できる。
プログラミングモデル
基本API:プロセスメッシュとアクタメッシュ
プロセスメッシュ(多数ホストに跨るプロセス配列)上にアクタメッシュ(各プロセス内で動くアクタの配列)を配置する。開発者はNumPy/PyTorchの配列操作に近い思考で、広域に分散された演算を指示できる。
例:最小のアクタ実装
from monarch.actor import Actor, endpoint, this_host
procs = this_host().spawn_procs({"gpus": 8})
# 単一メソッドを持つアクタ
class Example(Actor):
@endpoint
def say_hello(self, txt):
return f"hello {txt}"
# アクタを起動
actors = procs.spawn("actors", Example)
# まとめて呼び出し
hello_future = actors.say_hello.call("world")
# 結果を取得
print(hello_future.get())
例:メッシュのスライス操作
from monarch.actor import Actor, endpoint, this_host
procs = this_host().spawn_procs({"gpus": 8})
class Example(Actor):
@endpoint
def say_hello(self, txt):
return f"hello {txt}"
@endpoint
def say_bye(self, txt):
return f"goodbye {txt}"
actors = procs.spawn("actors", Example)
# 前半のGPU(0–3)にhello
hello_fut = actors.slice(gpus=slice(0, 4)).say_hello.call("world")
# 後半のGPU(4–7)にgoodbye
bye_fut = actors.slice(gpus=slice(4, 8)).say_bye.call("world")
print(hello_fut.get())
print(bye_fut.get())
例:フォールトリカバリ(例外処理)
from monarch.actor import Actor, endpoint, this_host
procs = this_host().spawn_procs({"gpus": 8})
class Example(Actor):
@endpoint
def say_hello(self, txt):
return f"hello {txt}"
@endpoint
def say_bye(self, txt):
raise Exception("saying bye is hard")
actors = procs.spawn("actors", Example)
hello_fut = actors.slice(gpus=slice(0, 4)).say_hello.call("world")
bye_fut = actors.slice(gpus=slice(4, 8)).say_bye.call("world")
try:
print(hello_fut.get())
except Exception:
print("couldn't say hello")
try:
print(bye_fut.get())
except Exception:
print("got an exception saying bye")
Pythonフロントエンド × Rustバックエンドによる実装
フロントはPython(Jupyterや既存PyTorchコードと親和)、バックエンドはRustで実装され、fearless concurrencyを活かして性能・拡張性・堅牢性を確保する。最下層にはRust製アクタ基盤hyperactorと、そのベクトル化拡張hyperactor_meshがあり、Python APIはその薄いラッパである。
スケーラブルメッセージング
メッシュ全体へのcast(多播)を効率化するため、マルチキャスト木とマルチパートメッセージングを採用する。前者は全ノード転送のボトルネックを避け、後者はコピー回避と高扇出送信の効率化を図る。さらに制御プレーンをデータ配送のクリティカルパスから外す設計により、RDMA経由の大容量データを高速転送できる。
事例1:強化学習(RL)ワークロード
RL後処理では生成器・学習器・推論器・報酬パイプラインなどの異種計算が1つのループに共存する。Monarchでは各構成要素をメッシュ化し、単一のPythonオーケストレータがメッシュ間のデータ授受と進行を司る。RDMAによりメッシュ間のテンソル転送を直接行い、スケールと効率を両立する。
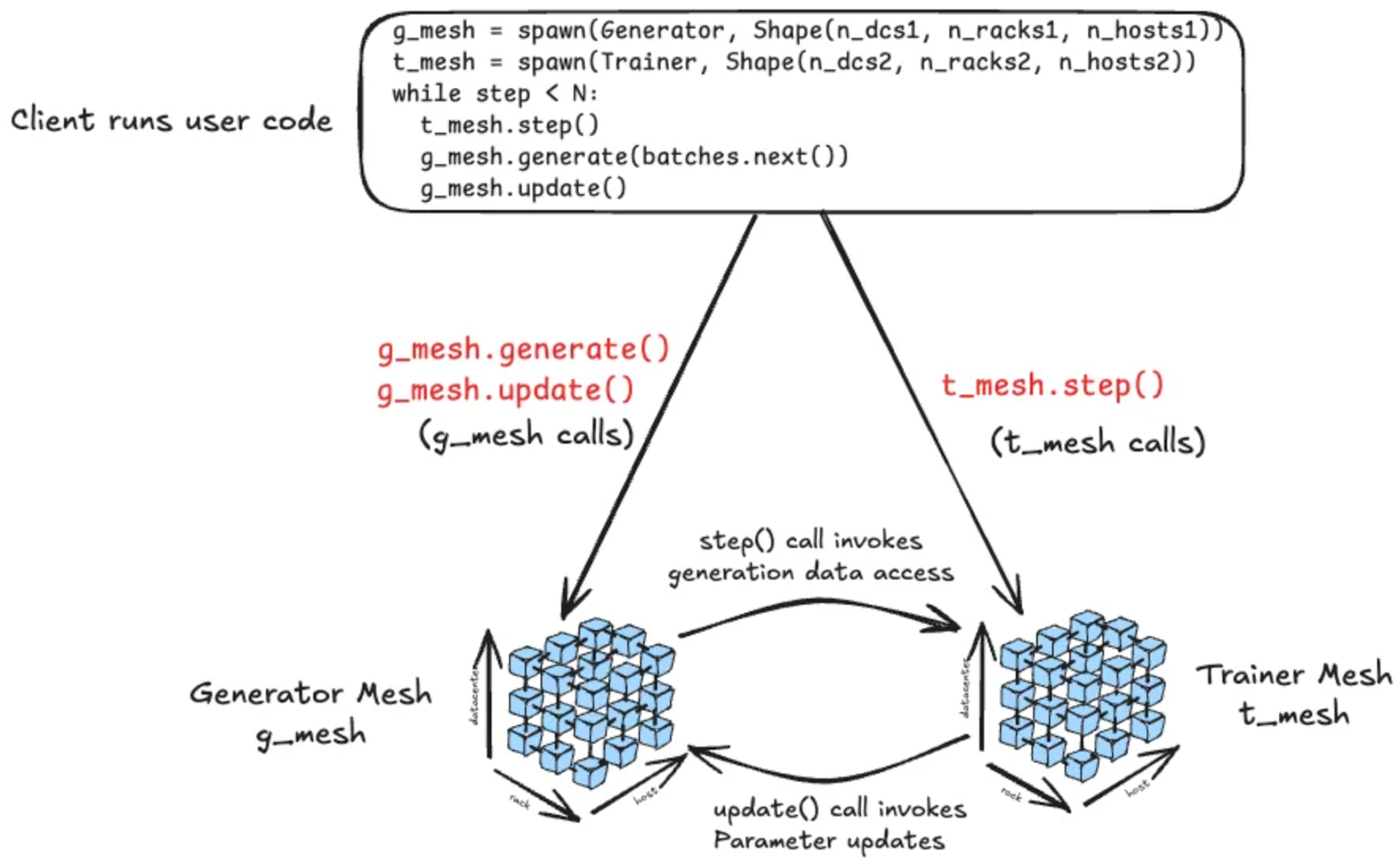
VERLとの連携(PoC)
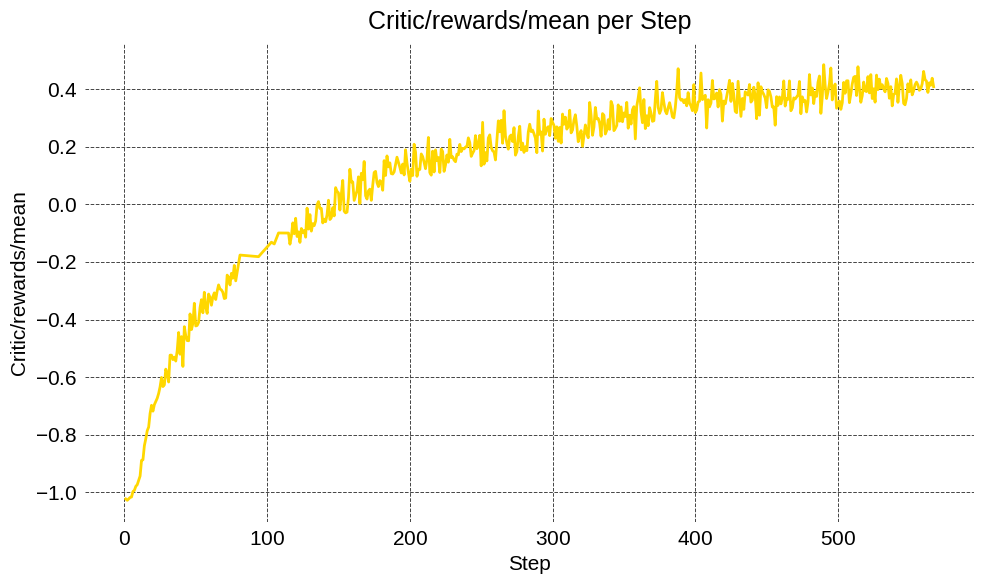
産業界で広く使われるRLフレームワークVERLと統合し、Qwen-2.5-7B(Math)をGRPOで後学習。H200 GPUで16→64→1024→2048 GPUへ段階的にスケールし、安定動作と数値同等性を確認した。統合は今後オープンソース化予定である。
TorchForge:Monarchプリミティブ直結のPyTorchネイティブRL
TorchForgeはMonarchのアクタ/RDMA/耐障害性を抽象化し、擬似コードのようにRLを書くことを狙う。
async def continuous_rollouts():
while True:
prompt, target = await dataloader.sample.route()
response = await policy.generate.route(prompt)
reward = await reward.evaluate_response.route(prompt, response.text, target)
await replay_buffer.add.route(Episode(...))
さらにServices抽象により、ロードバランス.route()、並列ブロードキャスト.fanout()、ステートフルなスティッキーセッション等を提供する。
# 16レプリカ × 各8GPU のポリシーサービス
policy = (
PolicyActor.options(procs=8, with_gpus=True, num_replicas=16)
).as_service()
response = await policy.generate.route(prompt) # 負荷分散
await policy.update_weights.fanout(version) # 並列ブロードキャスト
TorchStoreはMonarchのRDMAと単一コントローラ設計を活用した分散KVストアで、学習系と推論系で異なるレイアウト間のオンザフライ再シャーディングをDTensor APIで隠蔽する。
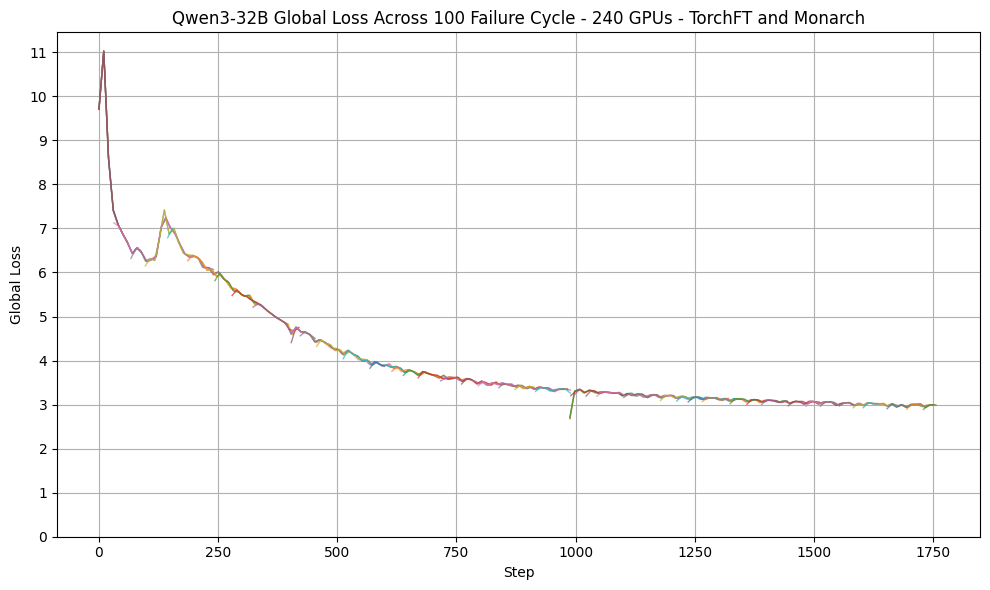
事例2:大規模事前学習の耐障害性
大規模学習では数時間に一度の頻度で障害が発生する。PyTorchのTorchFT(Fault Tolerance)とMonarchを統合し、障害検知後はプロセス再起動→必要時のみジョブ再割当の段階的回復を行う一方、健全レプリカは学習継続する。CoreWeaveの30ノード(240×H100)でQwen3-32Bを学習し、様々な障害(segfault/NCCL abort/ホスト退役等)を3分ごとに注入した結果、全面SLURM再起動比で最大60%短縮、平均回復はプロセス障害90秒、機械障害2.5分と報告されている。
事例3:大規模GPUクラスタのインタラクティブデバッグ
バッチ志向の従来手法では多GPU固有のレース・デッドロック・通信ボトルネックに対処しづらい。MonarchはローカルのJupyterからクラスタメッシュを対話的に駆動できる。
- 永続的な分散計算リソースにより、高速な反復実行が可能である。
sync_workspaceAPIでローカル環境をメッシュへ迅速同期できる。- メッシュネイティブな分散デバッガを備える。
Lightning AI Notebookとの連携
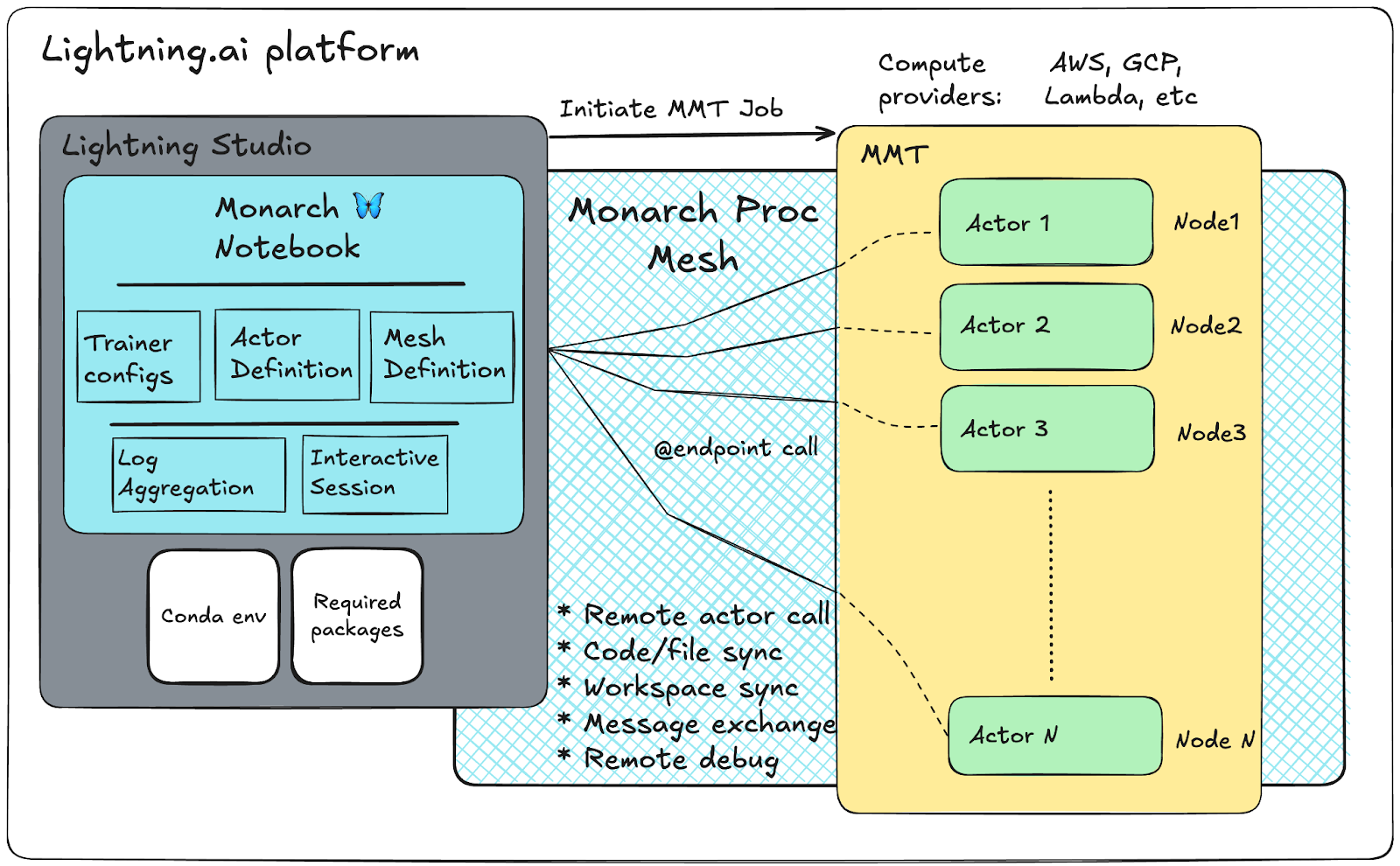
Lightning Studio Notebookから256 GPUのTorchTitanジョブを単一ノートブックで起動し、リソースの永続化(MMT)、ログ・メトリクスの可視化、アクタへのブレークポイント設定によるリアルタイム解析を実現する。ノートブック切断時もクラスタ割当は持続し、設定変更→再実行の反復を加速できる。
まとめ:単一コントローラで「書きやすさ」と「スケール」を両立
Monarchは、配列的メッシュ操作・段階的フォールトハンドリング・制御/データ分離・分散テンソル統合という設計で、単一マシン級の書き味を保ったまま数千GPU規模へスムーズに拡張する。RL、事前学習、ノートブック駆動の大規模実験など、現代的なAIワークロードの複雑なオーケストレーションを、Pythonそのままの表現力で実現する基盤である。
詳細はIntroducing PyTorch Monarch – PyTorchを参照していただきたい。