
9月11日、Bunが「Behind The Scenes of Bun Install」と題した記事を公開した。この記事では、bun install が既存のパッケージマネージャより著しく高速である理由――システムコール最小化、OSネイティブ機能の活用、バイナリ形式でのメタデータキャッシュ、解凍とファイルコピーの最適化、マルチコア並列実行――について詳しく紹介されている。以下に、その内容を紹介する。
背景—2009年のI/O待ちから、2025年のシステムコール過多へ
かつてのボトルネックはI/O待ちであり、Node.jsはイベントループとスレッドプールによりこの問題に対処してきた。一方、NVMeや多数コアが一般化した現在では、ボトルネックはI/Oではなくシステムコールそのものに移っているという指摘である。


システムコールの問題—モードスイッチのオーバーヘッド
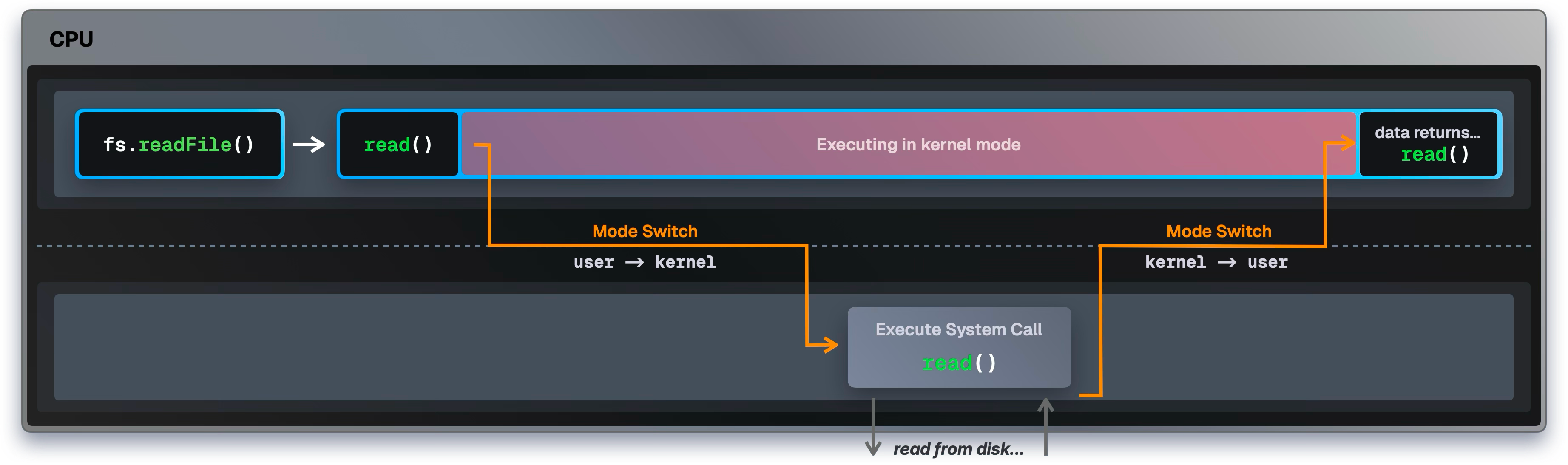
ユーザモードとカーネルモードの切り替え(モードスイッチ)は1000–1500サイクルの純粋なオーバーヘッドを生む。パッケージインストールでは数万〜数百万回のシステムコールが発生し、これが秒単位の無駄につながる。
straceによる比較(抜粋)
Benchmark 1: strace -c -f npm install
Time (mean ± σ): 37.245 s ± 2.134 s
System calls: 996,978 total
Top syscalls: futex (663,158), write (109,412), epoll_pwait (54,496)
Benchmark 2: strace -c -f bun install
Time (mean ± σ): 5.612 s ± 0.287 s
System calls: 165,743 total
Top syscalls: openat(45,348), futex (762), epoll_pwait2 (298)
Benchmark 3: strace -c -f yarn install
Time (mean ± σ): 94.156 s ± 3.821 s
System calls: 4,046,507 total
Benchmark 4: strace -c -f pnpm install
Time (mean ± σ): 24.521 s ± 1.287 s
System calls: 456,930 total
futex(スレッド同期)呼び出しの多さは待ちの多さを示す。bunは futex をわずか762回(0.46%)に抑え、待ちによる足枷を極小化している。
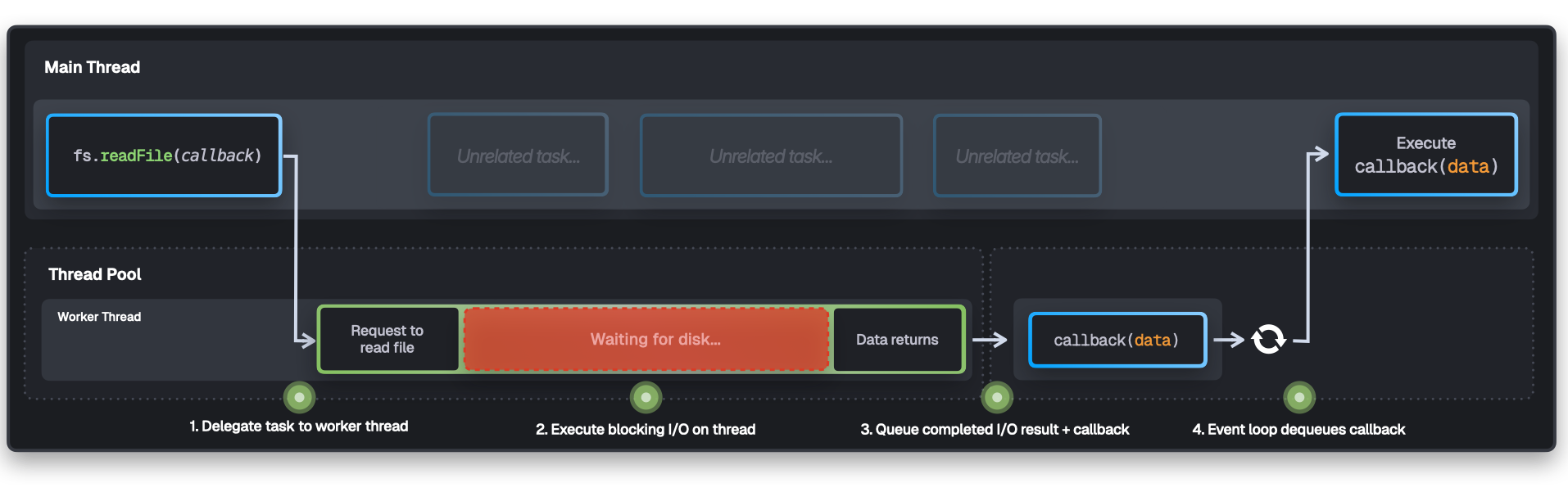
JavaScriptのオーバーヘッドを避ける—Zigによる直接システムコール
Node系ツールは fs.readFile() → libuv → スレッドプール → カーネルという多層を経由する。BunはZigで実装され、必要に応じて直接システムコールを叩く。
// 直接システムコール、JavaScript層のオーバーヘッドなし
var file = bun.sys.File.from(try bun.sys.openatA(
bun.FD.cwd(),
abs,
bun.O.RDONLY,
0,
).unwrap());
単純ファイル読み取りの性能比較
| Runtime | Version | Files/Second | Performance |
|---|---|---|---|
| Bun | v1.2.20 | 146,057 | — |
| Node.js | v24.5.0 | 66,576 | 2.2x遅い |
| Node.js | v22.18.0 | 64,631 | 2.3x遅い |
Bunは1ファイルあたり約0.019msで、Node.jsより2倍超の処理性能を示す。
ネットワーク・レイヤの微最適化—非同期DNS(macOS)
macOSではAppleの非公開API getaddrinfo_async_start() を用い、本当の意味での非同期DNSを実現する。package.json の解析と並行してDNS解決を先行し、待ち時間を詰める(注:最適化の一例で、測定外)。
マニフェストのバイナリキャッシュ—JSONパースを一度きりに
一般的なツールはマニフェスト(巨大なJSON)をキャッシュしても再パースが必要になる。Bunは一度JSONを解析し、**バイナリ(.npm)**として保存する。以降はオフセット参照だけで文字列や依存情報を取り出す。
{
"name": "lodash",
"versions": {
"4.17.20": { "name": "lodash", "version": "4.17.20", "license": "MIT" },
"4.17.21": { "name": "lodash", "version": "4.17.21", "license": "MIT" }
// …100+ほぼ同一
}
}
// 文字列を一意格納し、各項目はオフセット参照(擬似コード)
string_buffer = "lodash\0MIT\0Lodash modular utilities.\0git+https://github.com/lodash/lodash.git\0https://lodash.com/\04.17.20\04.17.21\0..."
versions = [
{ name_off:0, version_off:99, license_off:7 }, // 4.17.20
{ name_off:0, version_off:107, license_off:7 }, // 4.17.21
]
キャッシュあり・なし比較(抜粋)
bun install # fresh : 35.7 ms (mean)
bun install # cached : 4.8 ms (mean)
npm install # fresh : 815.1 ms (mean)
キャッシュ済みnpmより、Bunの“初回”のほうが速いという示唆的な結果である。
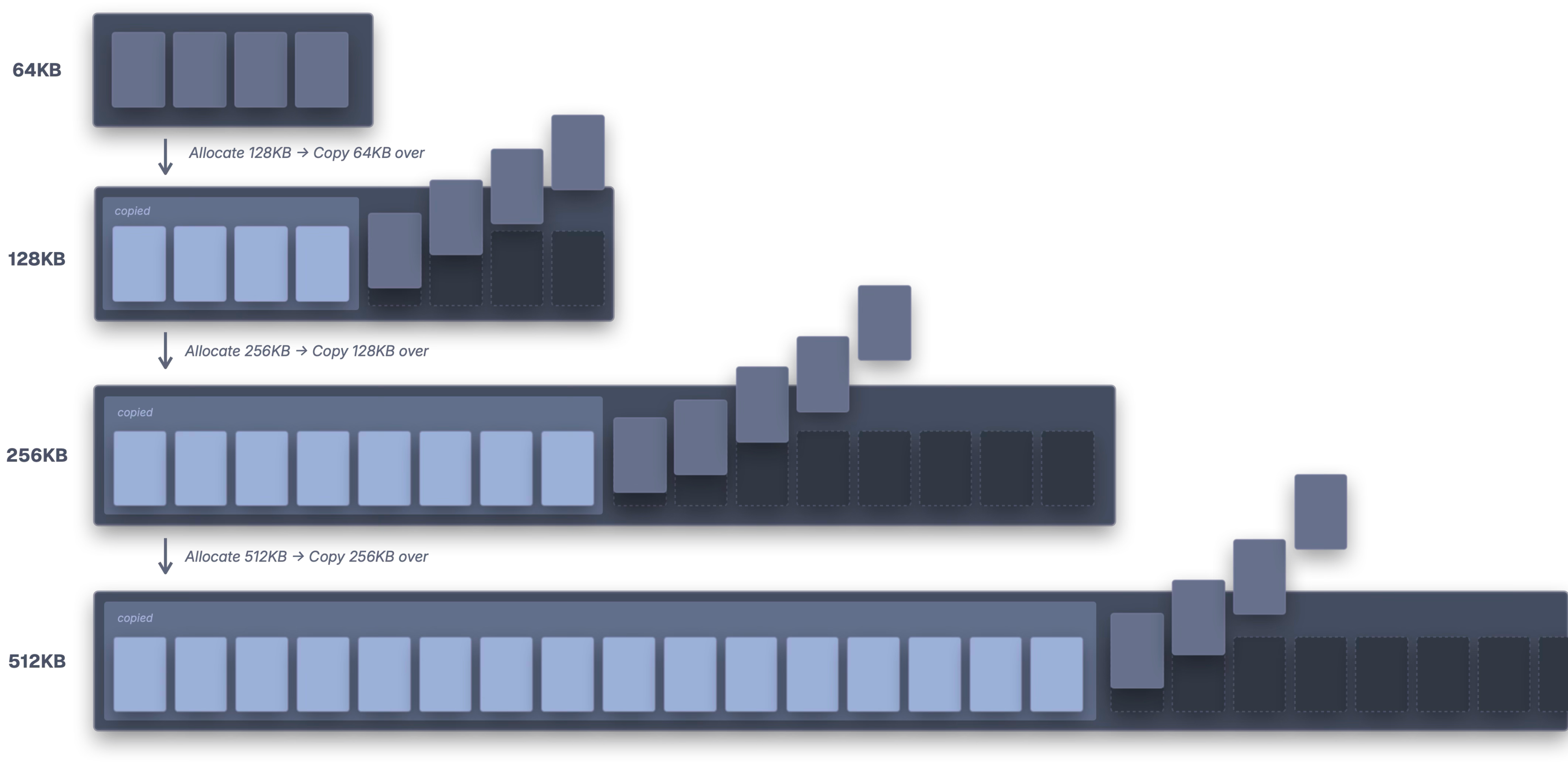
圧縮アーカイブ(tarball)展開の最適化—事前サイズ確定と再割当回避
一般的なストリーミング解凍はバッファ拡張とコピーを繰り返し、無駄が大きい。Bunはまず全体をメモリに取り込み、gzip末尾4バイト(ISIZE)から解凍後サイズを取得し、一度で所要サイズを確保する。これによりコピー回数を削減する。
// gzip末尾のISIZEから解凍後サイズを推定し、事前にバッファ確保
const last_4_bytes: u32 = @bitCast(tgz_bytes[tgz_bytes.len - 4 ..][0..4].*);
if (last_4_bytes > 16 and last_4_bytes < 64 * 1024 * 1024) {
esimated_output_size = last_4_bytes;
zlib_pool.data.ensureUnusedCapacity(last_4_bytes) catch {};
}
解凍にはSIMD最適化された libdeflate を採用し、zlibより高速に処理する。

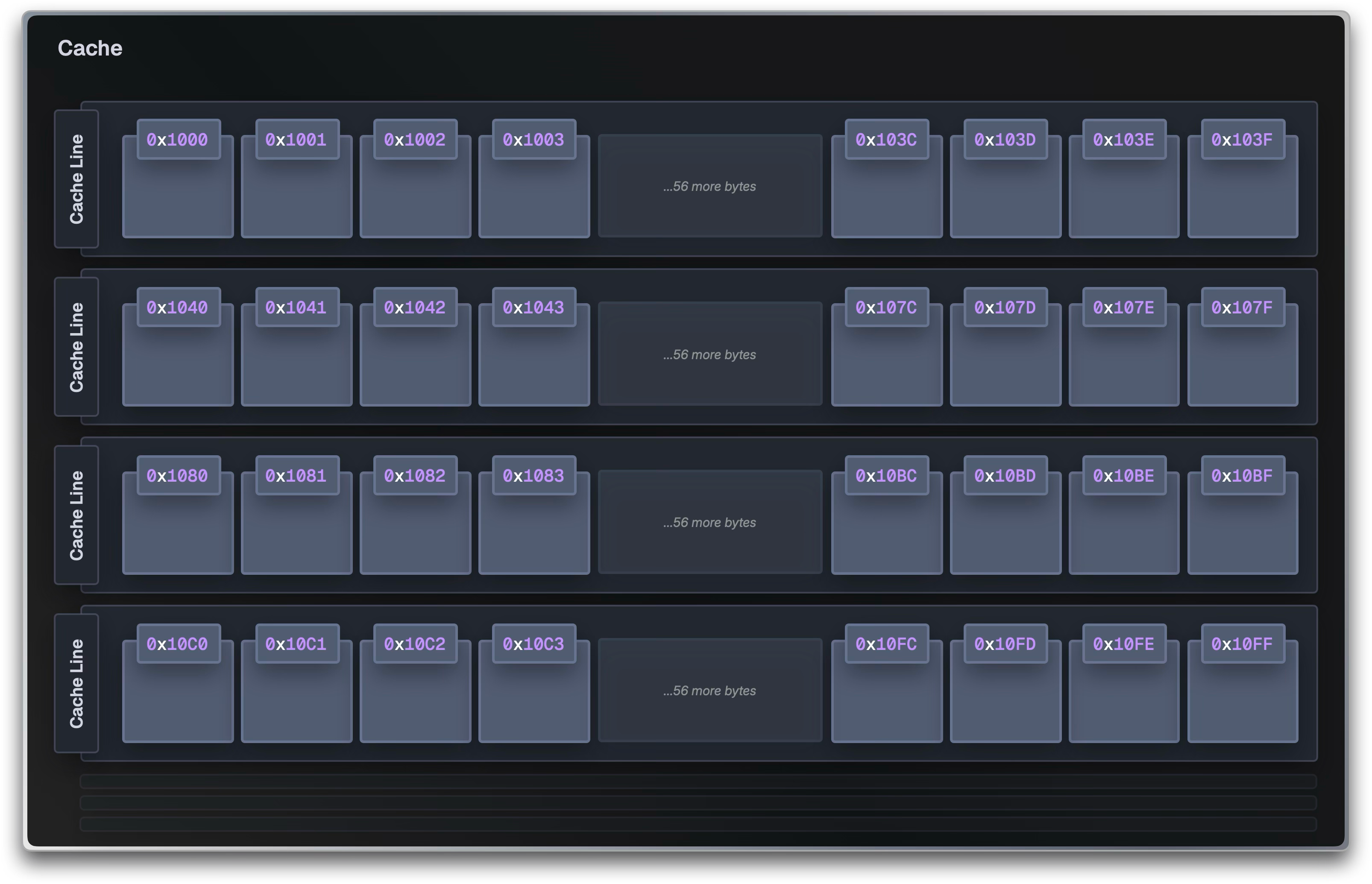
CPUキャッシュ効率を最大化—**Structure of Arrays(SoA)**設計
依存グラフのデータ配置を、オブジェクトのポインタ追跡(AoS)から連続領域にまとめるSoAへ。packages・dependencies・string_buffer を大きな連続配列として保持し、キャッシュライン命中率を高める。
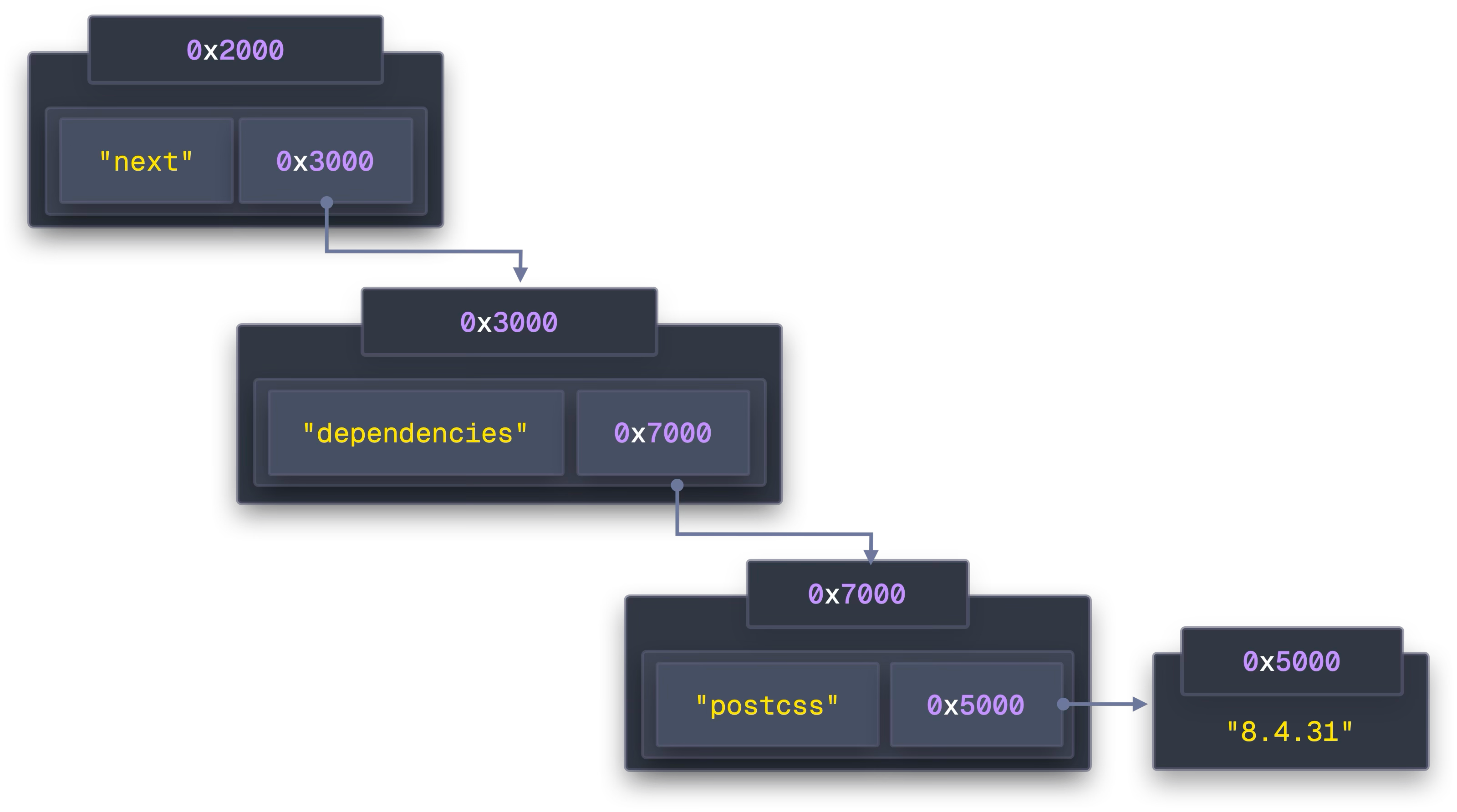
// 従来(AoS)
packages = { next: { dependencies: { "@swc/helpers": "0.5.15", "postcss": "8.4.31" } } };
// Bun流(SoA)
packages = [
{ name:{off:0,len:4}, version:{off:5,len:6}, deps:{off:0,len:2} }, // next
];
dependencies = [
{ name:{off:12,len:13}, version:{off:26,len:7} }, // @swc/helpers@0.5.15
{ name:{off:34,len:7}, version:{off:42,len:6} }, // postcss@8.4.31
];
string_buffer = "next\015.5.0\0@swc/helpers\00.5.15\0postcss\08.4.31\0";
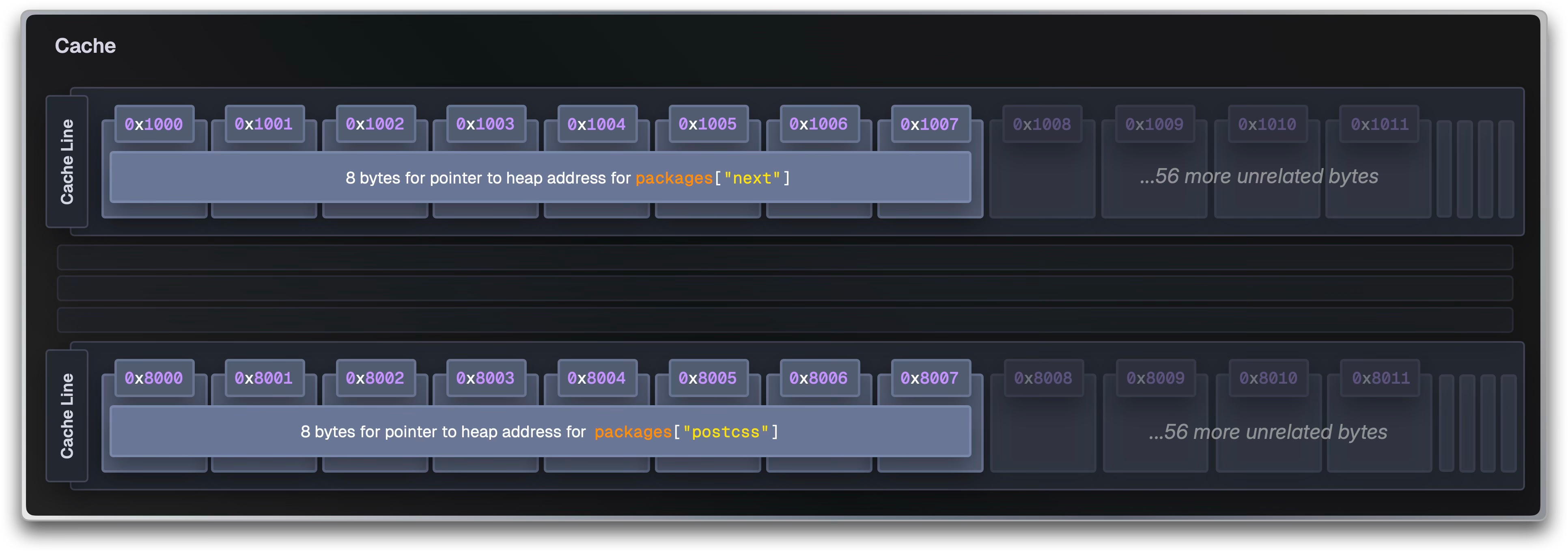
ロックファイル形式の最適化—人間可読 × SoA的配置
bun.lock は文字列重複を減らし、依存順に並べることで逐次読み取りを高速化する。もともとバイナリロック(bun.lockb)も検討されたが、レビュー性やマージ耐性からテキスト形式を選択している。
{
"lockfileVersion": 0,
"packages": {
"next": [
"next@npm:15.5.0",
{ "@swc/helpers": "0.5.15", "postcss": "8.4.31" },
"hash123"
]
}
}
ファイルコピーの極小化—OSごとの最適経路を選ぶ
macOS—clonefile() によるコピーオンライト
APFSの clonefile() を使えば、ディレクトリツリー全体を1回のシステムコールで複製できる。データブロックは共有され、書き込み時にのみ分岐する。
// 従来:各ファイルごとにopen/read/write/closeを多数回
// Bun:一撃
clonefile("/cache/react", "/node_modules/react", 0);
ベンチマーク(抜粋):
copyfile : 2.955 s
clonefile : 1.274 s // 2.32x高速
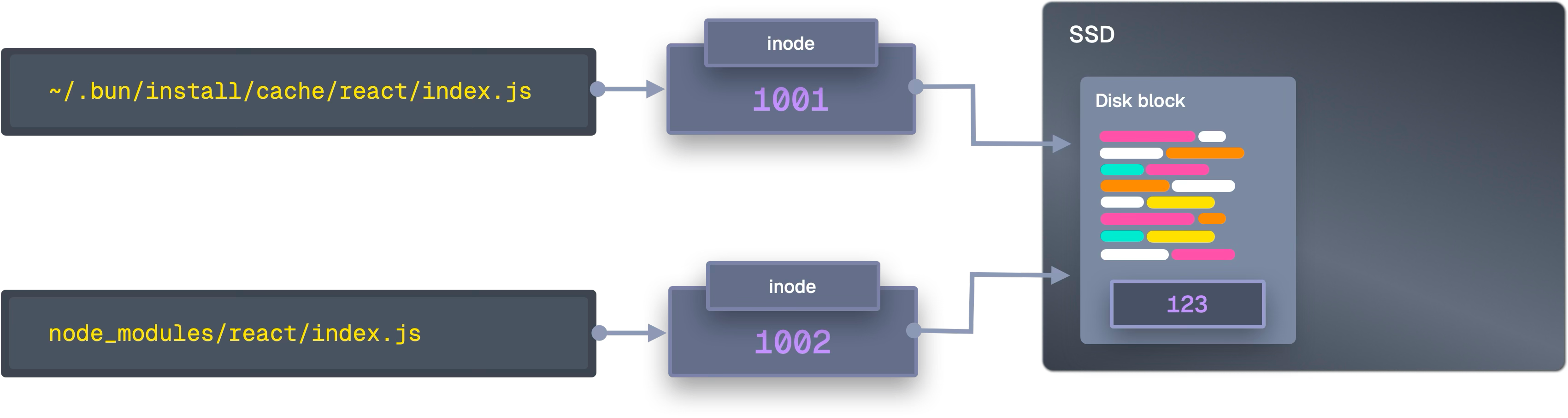
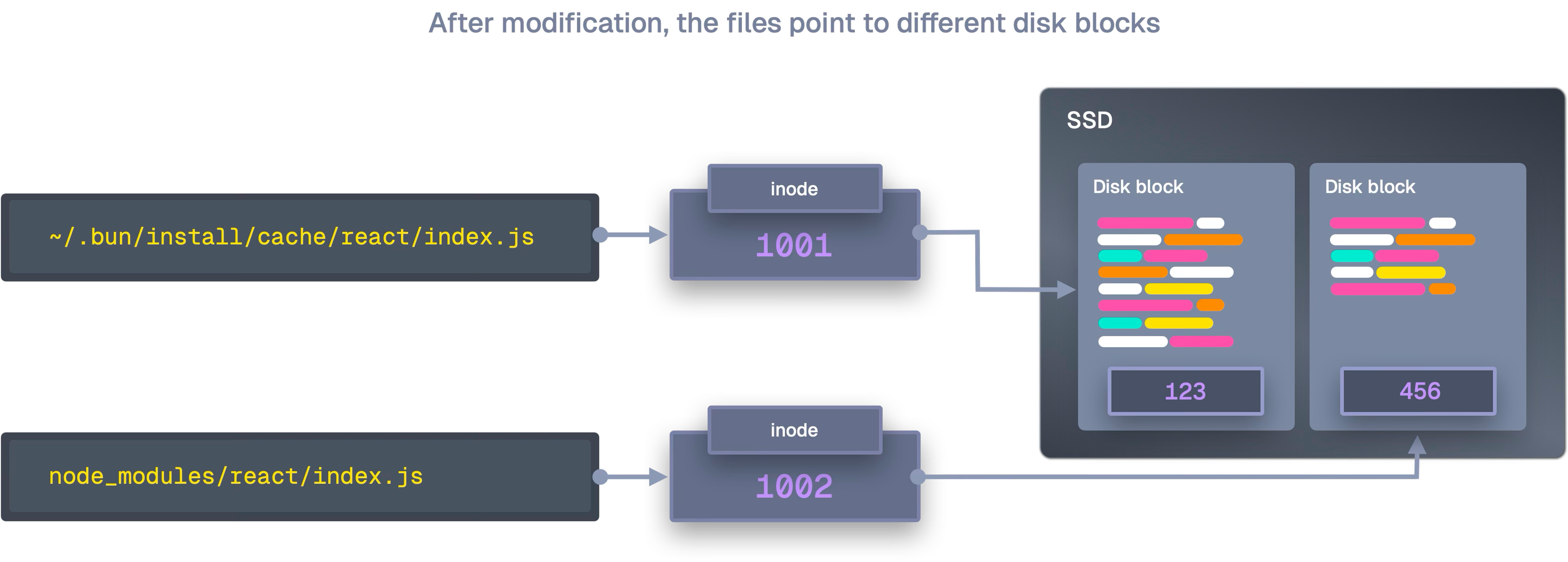
Linux—ハードリンクを最優先、ダメなら段階的フォールバック
- hardlink → 2)
ioctl_ficlone(COW)→ 3)copy_file_range(カーネル内コピー)→ 4)sendfile→ 5)copyfileの順に降格する。ハードリンクはデータ移動ゼロで、巨大ファイルでもコストが一定だ。
Benchmark (Linux)
copyfile : 325.0 ms
hardlink : 109.4 ms // 2.97x高速
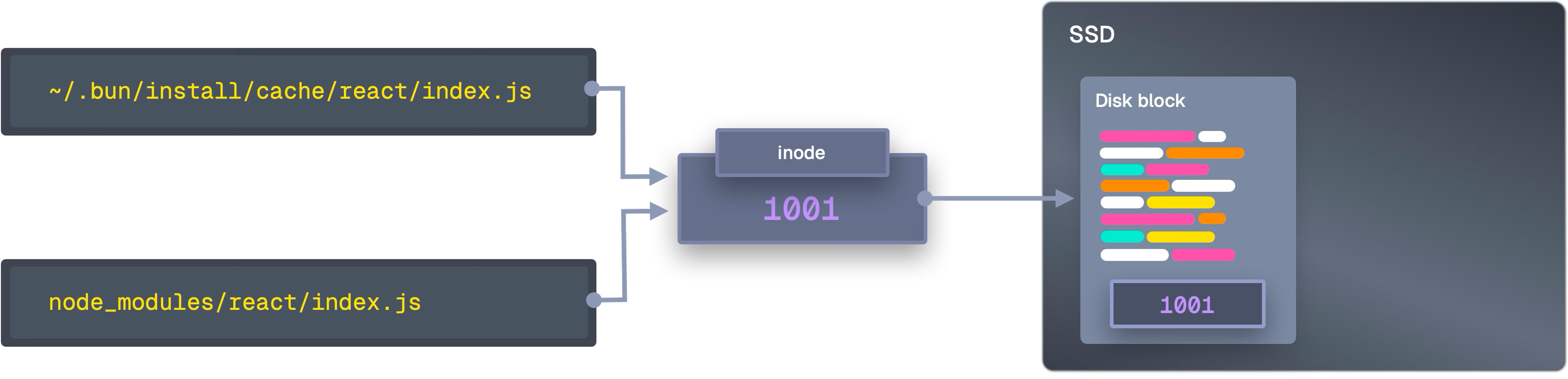
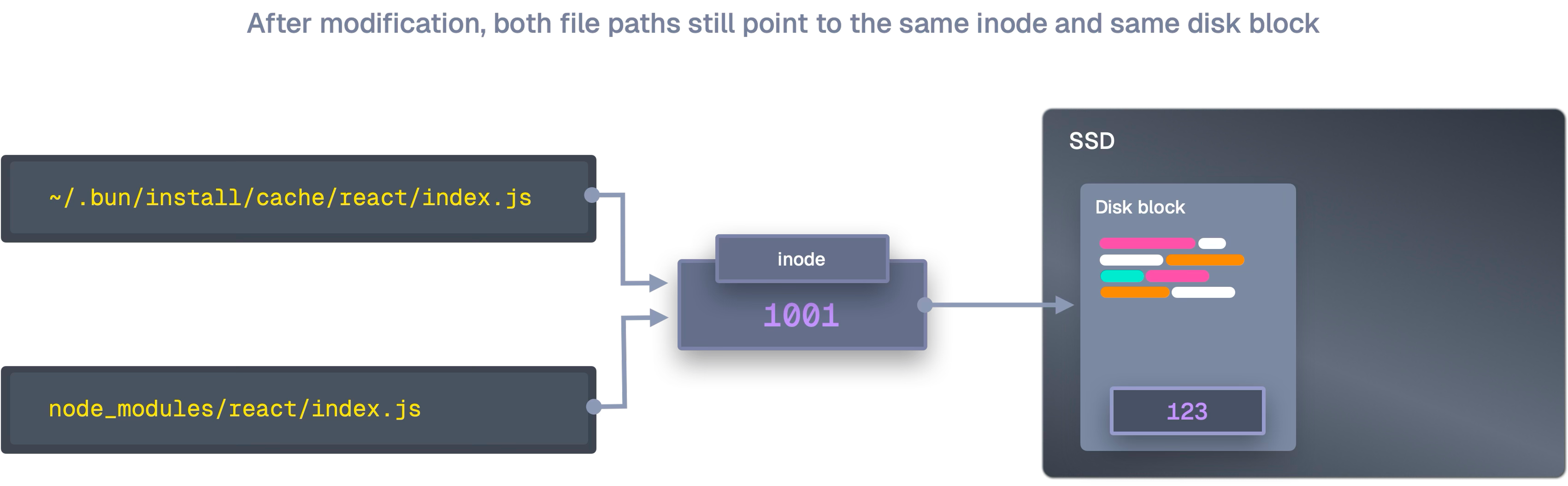
マルチコア並列—ロックフリー×ワークスティーリング
Bunはロックフリーデータ構造とワークスティーリングを採用し、全コアを有効活用する。ネットワークは最大64本のHTTP接続を専用スレッドで捌き、CPU側は解凍・依存解決・パッチ適用などを並列処理する。各スレッドに専用アロケータを与え、メモリアロケータの競合も避ける。
// ロックフリー:アトミックCASで共有キューを更新
_ = @cmpxchgStrong(usize, &self.state, state, new_state, .seq_cst, .seq_cst);
ファイル走査では、Bunが 146,057 files/s、Node.jsが6万台に留まる差は、全コア活用の設計差が大きいと述べられている。
まとめ—「いまのハードウェア」に合わせて作り直す
npm/yarn/pnpmは当時の制約に最適化されていた。だが現在の現実は、SSDは高速で、CPUは多コアで、メモリは潤沢である。Bunは抽象のオーバーヘッド(システムコール回数・JSON再パース・無駄なコピー・ロック待ち)を徹底的に削ることで、高速化を実現している。
「インストールが25倍速い」のは魔法ではなく、2025年のハードウェア前提で道具を作り直した結果である。
詳細はBehind The Scenes of Bun Installを参照していただきたい。