
7月31日、Google Researchが「SensorLM: Learning the language of wearable sensors」と題した記事を公開した。この記事では、 ウェアラブルデバイスから取得されるセンサ信号を自然言語で理解・生成する大規模基盤モデル SensorLM の開発背景、学習方法、評価結果、そして将来展望について詳しく紹介されている。以下に、その内容を紹介する。

データが語る「からだのことば」を解読する試み
スマートウォッチやフィットネストラッカーは、心拍数や歩数、睡眠パターンなど膨大なライフログを絶え間なく記録している。しかし「150 bpm」という数字だけでは、その瞬間にジョギングをしていたのか、緊張して講演をしていたのかを読み取れない。センサデータが示す 「なにか」 を捉えるには、信号を豊かな文脈に結びつけるモデルが必要だった。
SensorLMは、この課題を解決するために設計された。FitbitおよびPixel Watchから得た 計5,970万時間分 のマルチモーダルデータ(心拍、加速度、皮膚温など)を用い、103,643人・127 か国 規模のライフログを学習することで、センサデータが「何を表しているのか」を精度高く推論する言語モデルが出来上がった。
以下の図は、膨大な時系列信号と自然言語キャプションを結ぶ訓練パイプラインを示す。
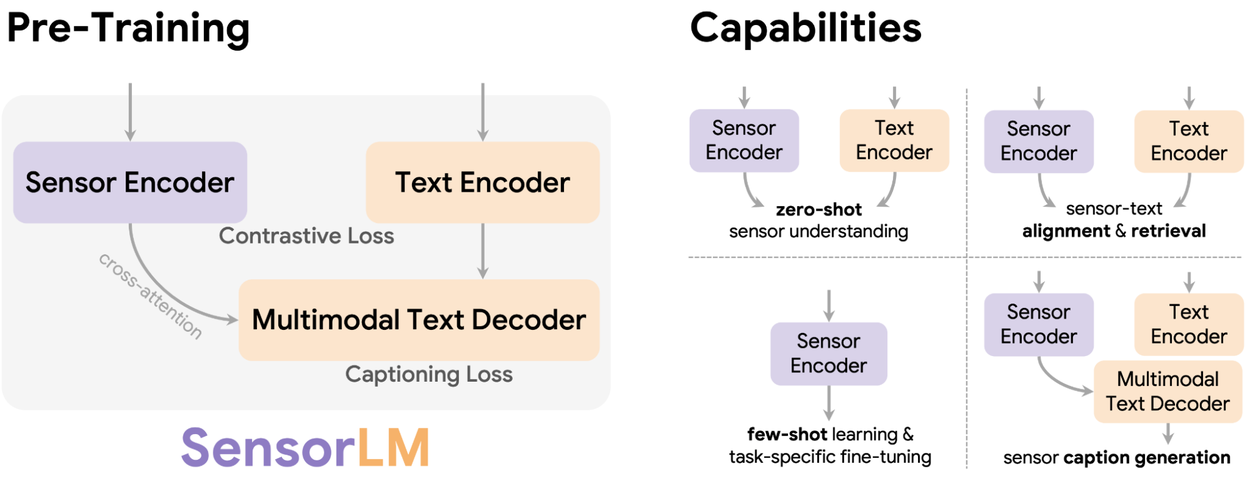
自動キャプション生成という突破口
センサデータには手作業で注釈を付けられた大規模コーパスが存在しない。そこで研究チームは、以下の段階を縦に連ねた階層型キャプション生成パイプラインを考案した。
- 統計情報抽出 ― 心拍・歩数などから平均値やピークを算出。
- トレンド検出 ― 上昇・下降などのパターンを把握。
- イベント描写 ― 「緩やかな上り坂をジョギング」「深い睡眠が90分続いた」など、人間が読める文章を自動生成。
この仕組みにより、従来研究の数桁上を行くセンサ‑言語データセットが構築された。
学習アーキテクチャ ― コントラストと生成の融合
SensorLMは、コントラスト学習(Contrastive Learning)と生成的事前学習(Generative Pre‑training)を同一フレームワークに統合している。
コントラスト学習では、センサ区間と言語記述の正しい組を当てるタスクを通して「軽い水泳」と「筋力トレーニング」を識別できる表現を獲得する。
生成的事前学習では、センサ信号だけを入力し、状況に即したテキストキャプションを生成する能力を養う。両者をあわせた統合モデルが、信号と言語の深い意味対応を可能にした。
実証された能力
ゼロショットで活動を見抜く
評価では、SensorLMがラベルなしの状態で20種類の活動を識別し、AUROC指標で従来モデルを大幅に上回ったと報告されている。
以下のグラフに示される通り、汎用LLMがランダムに近い性能にとどまるのに対し、SensorLMは着実に高いスコアを示した。

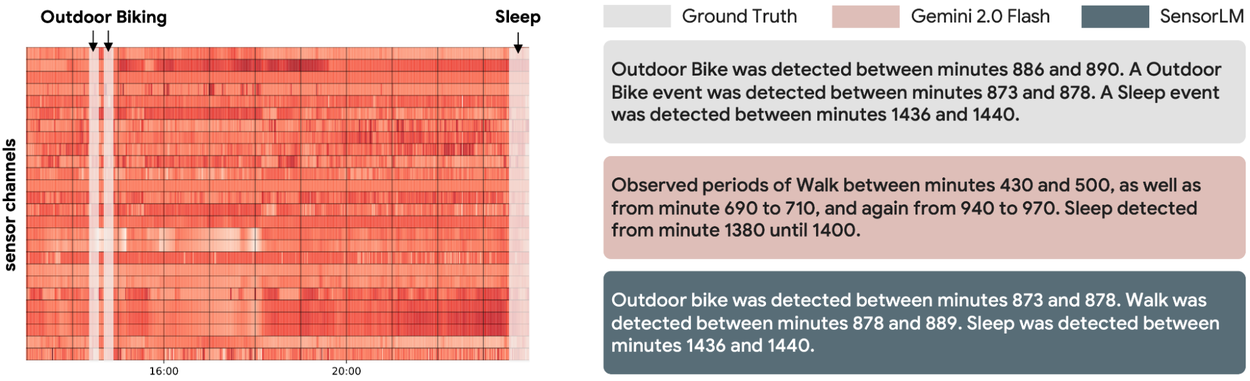
センサから物語を紡ぐキャプション生成
SensorLMは、心拍や加速度の波形のみから階層的で文脈豊かな説明文を生成できる。下図の比較例では、汎用LLMよりも一貫した記述を提示し、高次元の信号を「40 分間のテンポ走」「午後の軽い散歩」のような自然言語に変換している。
スケールすれば伸びる ― 典型的なスケーリング則
研究者らは、計算量・データ量・モデルサイズを変化させる実験も実施。
以下のように、いずれの軸でも性能が単調に向上し、言語モデル研究で知られるスケーリング法則がセンサ分野でも成立することを示した。

センサデータの“読み書き”が拓く未来
論文の結語では、SensorLMを代謝や睡眠解析など新領域へ拡張し、自然言語でのクエリや対話によってパーソナライズされたヘルスコーチや臨床モニタリングを実現するビジョンが語られている。巨大な時系列信号を「読み」、人間と同じ言語で「書く」AIが、健康データの可視化を超えた“説明可能なウェアラブル体験”をもたらす日は近いかもしれない。
詳細はSensorLM: Learning the language of wearable sensorsを参照していただきたい。