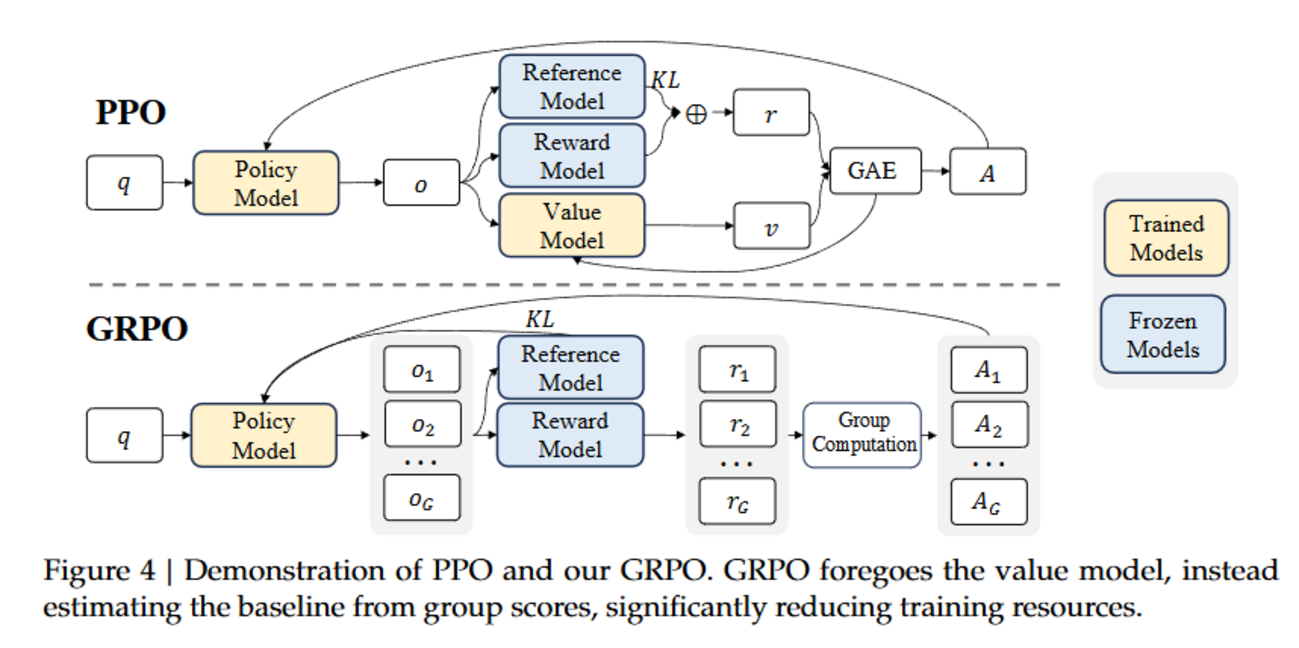
LLMチューニングのための強化学習:GRPO(Group Relative Policy Optimization)
ARANK
DeepSeek-R1にも採用されたLLMチューニングのための強化学習手法 GRPO(Group Relative Policy Optimization)について考えたことをまとめます。 GRPO: DeepSeek-R1の強化学習ファインチューニング手法 前提手法:TRPO/PPO TRPO: Trust Region Policy Optimization PPO: Proximal Policy Optimization GRPOとPPOの差分:①アドバンテージ算出と②参照モデルからのKL距離制約 変更点①: アドバンテージAの算出方法 REINFORCE: 価値関数近似なし方策勾配法…