
本記事は、インフルエンサーマーケティングプラットフォーム『toridori marketing』を展開する株式会社トリドリ様の2024年に行ったサービス基盤構築について、実際に開発に従事しているエンジニアの皆様に詳しく伺ってきました。
toridoriのサービス基盤構築プロジェクトとは?
──本日はよろしくお願いします。まずは自己紹介をお願いできますか?
柴田: 柴田です。基盤チームのテックリードをやっています。基盤開発については全体的に関わっていますが、最近は機械学習のインフラ基盤構築の比重が大きいです。
井上: 井上です。機械学習のモデル開発をメインで担当しているほか、そのモデルをデプロイして、実際に利用するための環境構築なども担当しています。
向井: 向井です。私は主にサービスのバックエンド開発やインフラ構築を行っています。基盤という話で言うと、既存のデータベースを統合したデータ基盤の設計・開発を担当しました。
髙瀬: 髙瀬です。エンジニア採用や開発組織全体のマネジメントを担当しています。今日は裏方でいいので、顔出しなしでOKです(笑)
──御社は今年、サービス基盤の構築に力を入れたと聞きました。今改めて基盤構築に臨んだのは、どういう背景があるんでしょうか。
髙瀬: toridoriのメインとなる事業は、インフルエンサーと広告主をマッチングするプラットフォームサービスです。特に、全国のSMB(中小企業・個人事業主)の皆様とインフルエンサーのマッチングの多さが特徴で、毎日約10,000件のマッチングが発生するため、データもかなり蓄積していました。
ただ、今年(2024年)のはじめまでは、そうしたデータが「ただ存在する」状態。それらのデータを活用して、よりサービスを改善していくために、新たなサービス基盤の開発が必要でした。
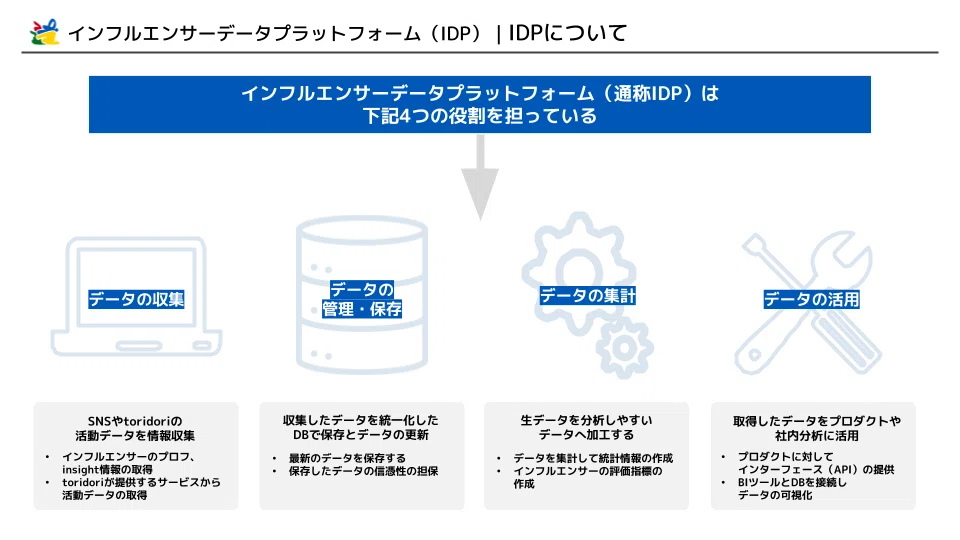
※編注: 本記事におけるサービス基盤とは、toridori様が公式に発表している「インフルエンサーデータプラットフォーム(IDP)と深い関わりがあります。
──具体的には、どのような基盤を構築したんでしょうか?
柴田: まずはデータの統合基盤と分析基盤ですね。
toridoriでは、インフルエンサーサービスが複数あるのですが、サービスごとにデータが独立している状態でした。サービスとデータが分かれていることで良い点もあるのですが、データを横断的に分析したり活用しようとすると、分析処理に時間がかかったり、やはり不便が出てきます。
そこで、複数のサービスにおけるインフルエンサーデータを統合した基盤を構築し、その上で分析を行える基盤を構築しました。
──そうした基盤というのは、具体的にはどのようなものでしょうか?
柴田: toridoriではアプリケーションのDBとしてはMySQL、外部から収集したデータの保存にはBigQueryを使っています。

柴田: それらをAWSのAmazon Athenaを使って統合したことで、複数のデータベースを横断して分析を行えるようにしました。
── 具体的な技術やプロダクトも教えていただきありがとうございます。他にはどのような基盤を構築しましたか?
柴田: 機械学習基盤、あと認証基盤でしょうか。
先ほど述べた分析基盤の上で機械学習モデルを構築して、アプリケーションで活用できるようにしたのが機械学習基盤。
また認証基盤は、複数のサービスにまたがって認証を行えるようにしたものです。これによってユーザーの利便性を向上させただけでなく、SNSデータの収集に必要な認証処理もスマートに行えるようになりました。
インフルエンサーをデータ化すると、「SNSの集合化」になる
──たった1年でそれだけの基盤を開発するというのはすごいですね。特に苦労した点はどんなところでしょうか?
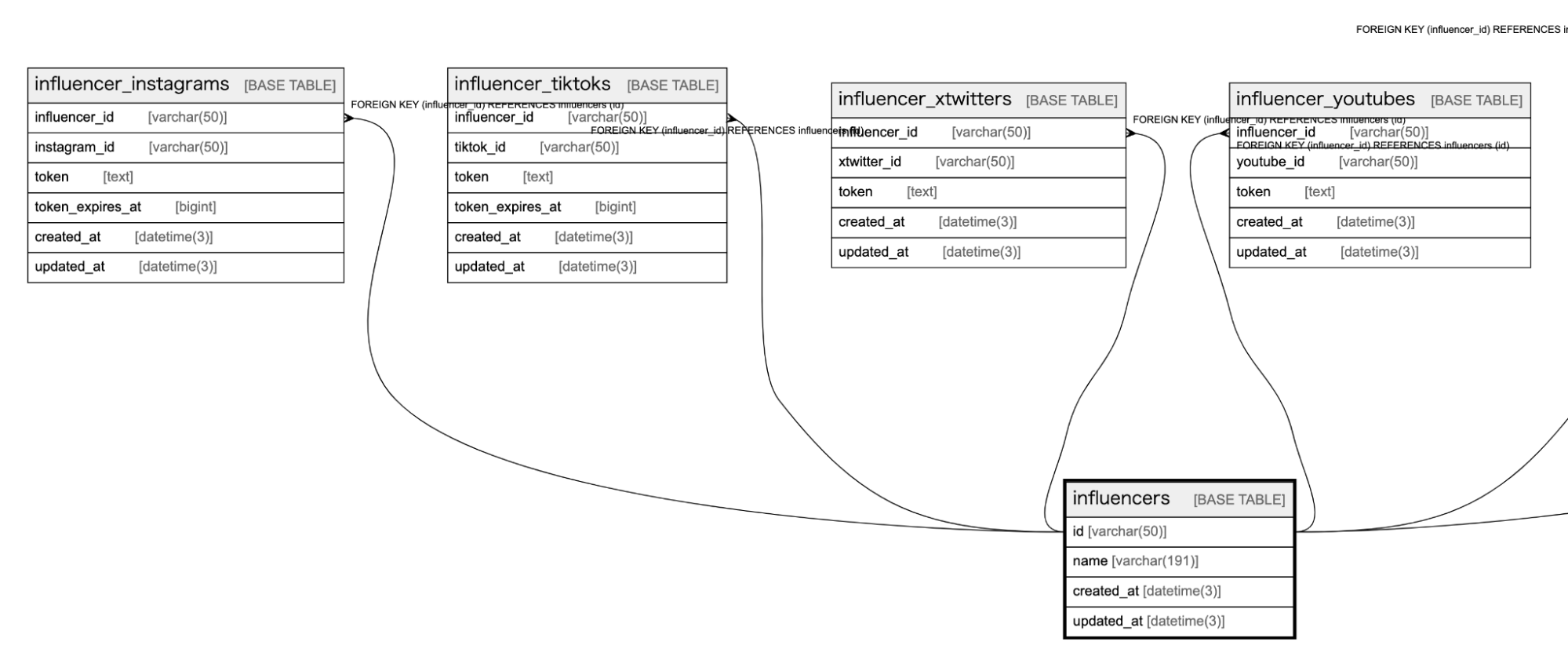
向井: やはり、複数にまたがるデータを統一的に扱えるようにする設計には苦労させられました。

向井: 具体的には、インフルエンサーに関するデータを統一したんですが、それぞれのサービスでのデータの扱いをまず深く理解した上で、試行錯誤が必要でした。
特に、インフルエンサーデータが、他のデータと深く依存している点には苦労しました。
そうした依存関係を慎重に切り離し、抽象化していった結果、インフルエンサーのデータ形式は「SNSアカウントを集合化した存在」になりました。
──それは興味深いですね。「インフルエンサーとは」を本質的に表す一つのかたち、のように聞こえます。
髙瀬: 苦労したといえば、井上が一人目の機械学習エンジニアとして、何をどこまで期待されているのか見えづらい中で成果を出すのは大変だったんじゃないかと思いますが、どうでしょう?
井上: そうですねえ… SageMaker(編注: AWSが提供する機械学習のマネージド型サービス)を使うのは苦労しましたね。
──え、そこですか?
井上: はい(笑) APIのエンドポイントを作るのに、Sagemakerのお作法に則ってDockerコンテナを構築する必要があるんですが、イマイチ公式がいいものを提供してくれていなくて…やりたいことを実現するのが一苦労でした。
──機械学習でモデルを作るところが一番大変だったんじゃないんですね(笑)
インフルエンサーのパフォーマンスを予測する機械学習基盤
──とはいえ機械学習でどんなモデルを開発したのか、とても気になります。
井上: 現在は、エンゲージメントの予測(特許出願中「特願2025-009500」)が可能になっています。このインフルエンサーに広告を頼むと、どれくらいのエンゲージメントが得られるのか、という予測です。

井上: 具体的には、広告主とインフルエンサーの情報から、エンゲージメント数を予測してくれる、というモデルです。機械学習アルゴリズムとしてはLightGBMを使いました。
キャンペーン情報は広告のジャンルやカテゴリーなど。予測されるエンゲージメント数というのは、コメント、いいね、保存、シェアの数を足した数値です。
──エンゲージメント数の予測…面白いですね!サービス上でどのように活用されるのでしょうか?
井上: まだ開発中ですが、インフルエンサーごとの予想エンゲージメント数を広告主に提供できるようになるので、どのインフルエンサーに依頼するかの意思決定を支援できるようになります。
髙瀬: あと、現在は「広告主にインフルエンサーをおすすめする」というサービスを提供しているのですが、逆に「インフルエンサーに広告をおすすめする」ということもできるといいなと思っています。
toridoriのサービスは広告主とインフルエンサーのマッチングが大きな価値ですが、マッチングを双方向にして、より良いマッチングを増やしていきたいと考えています。
基盤づくりに興味のあるエンジニア、大募集!
──最後に、読者の方にメッセージをお願いします。
髙瀬: この記事を読んでくださっている中でデータや機械学習に強い方がいたら、ぜひ一緒に働きたいです。
機械学習領域を更に深掘りしていけるプロフェッショナルが集まった、ちゃんとしたチームにしていきたいんです。toridoriには、インフルエンサーの行動をベースにした面白いデータが揃っているので、それを活用した新しいサービスをたくさん生み出したいです。
柴田: バックエンド開発のエンジニアの方もぜひ。toridoriのバックエンドは現在Node.jsで開発していますが、一つのサービスや技術だけに閉じず、「会社としてこう進むべきじゃないか」とか、物事を広い視野で捉えられる方だと嬉しいですね。
──御社の開発チームについて、皆様がそれぞれ「ここが魅力」という点を教えて下さい
柴田: スタートアップなので、マネジメント的なことも含め、一つの職域に閉じずにいろんなことをやれるのがいいところかなと思います。
井上: そうですね、ゼロイチができること、新しいことにチャレンジしていけるところがいいところだと思います。私も、機械学習エンジニアとして入社して、今まで経験のなかった新しいことをたくさん経験でき、成長を感じています。
向井: 今の私たちは、自分たちの(開発)チームで考えたことが、会社のサービスの基盤となっていくフェーズ。わたしたちが作り上げた基盤の上で、思いついたことをどんどん実現していける。そういう基盤づくりに魅力を感じる人にとっては、とても面白いフェーズじゃないかと思います。
──ありがとうございました
※編注: toridori様のブログでも、エンジニア採用について詳しく書かれているので、ご興味のある方は参照してみてください。