
Li Haoyi氏が2017年に執筆した「What's Functional Programming All About?」と題した記事が、どういうわけかTechFeedの記事収集エンジンに最近(2024年9月)拾われた。古い記事なので、読者の皆様に紹介するかどうかためらわれたが、時代を超えて普遍的な内容であり、非常にためになる情報源にもかかわらず、日本ではほとんど読まれていない記事なので、ここに簡単に紹介することとした。

この記事では、関数型プログラミングの本質と、その利点についてわかりやすく解説している。関数型プログラミングを初めて聞く人から、すでに知識を持っているエンジニアまで、幅広い読者が理解しやすい内容になっている。
ここに紹介するのは、元記事の要約である。原文は非常に詳しく、ウィットに富んだ内容となっているので、ぜひ原文も併せて参照していただきたい。
関数型プログラミングとは?
関数型プログラミング(FP)は、データフローに基づいてプログラムを設計する方法だ。これは、命令型プログラミングとは異なり、操作の順序ではなく、どのデータがどの関数によって処理され、どう変化していくかに焦点を当てている。
関数型プログラミングを使うことで、コードの構造が明確になり、デバッグやリファクタリングが容易になる。この点は、特に大規模なシステムや複雑なプロジェクトで重要だ。例えば、関数型プログラミングでは、並行処理や非同期処理を自然に扱うことができ、効率的なコードを実現できる。
関数型プログラミングの誤解
FPについては、以下のような誤解が広まっている。
単なるヘルパーメソッドではない
FPを単に「手続き的な命令を関数にまとめる方法」と捉えることが多いが、それは誤解だ。FPは、コードの再利用や簡潔さを目的とするだけではなく、データフローの管理に重点を置く。この点を理解しないと、本来のFPの力を引き出すことが難しい。HaskellだけがFPではない
HaskellはFPの代表的な言語だが、PythonやJavaScriptなど他の多くの言語でもFPスタイルを取り入れることができる。FPは言語に依存しないスタイルであり、どんな言語でも応用可能だ。
命令型プログラミングの問題点
命令型プログラミングは、手順に従って一つ一つの命令を順番に実行していくスタイルだが、この方法にはいくつかの課題がある。たとえば、以下のようなティラミスのレシピを考えてみよう。
def make_tiramisu(eggs, sugar1, wine, cheese, cream, fingers, espresso, sugar2, cocoa):
# エスプレッソに砂糖を溶かす(状態変更)
dissolve(sugar2, espresso)
# 卵を泡立てる(状態変更)
mixture = whisk(eggs)
# 砂糖とワインを加えてさらに泡立てる(状態変更)
beat(mixture, sugar1, wine)
# 湯煎で混ぜる(状態変更)
whisk(mixture)
# 生クリームを泡立てる(状態変更)
whip(cream)
# マスカルポーネチーズを泡立てる(状態変更)
beat(cheese)
# 卵とチーズを混ぜる(状態変更)
beat(mixture, cheese)
# 生クリームを加える(状態変更)
fold(mixture, cream)
# レディーフィンガーをエスプレッソに浸す(状態変更)
soak2seconds(fingers, espresso)
# ティラミスを組み立てる(状態変更)
assemble(mixture, fingers)
# ココアを振りかける(状態変更)
sift(mixture, cocoa)
# 冷蔵庫で冷やす(状態変更)
refrigerate(mixture)
return mixture # ティラミスが完成
説明
- 状態変更が中心: 命令型プログラミングでは、各ステップでデータや変数の状態が逐次変更される。このコードでは、
mixtureやcheeseなど、同じ変数が何度も異なる状態に変わる。 - ステップの順序依存: すべてのステップは順番に実行されなければならない。たとえば、生クリーム (
cream) を泡立てる前に、他のステップをスキップすることはできない。 - 並行処理が難しい: 状態が逐次変更されるため、各ステップが終わるまで次のステップを進められない。例えば、エスプレッソが準備できていない場合、ティラミスの他の部分も準備できない。
関数型プログラミングの利点
FPでは、各ステップが関数として定義され、その関数がどのデータを受け取り、どう変換するかが明確にされる。この構造により、エラーチェックが容易になり、再利用性が高まる。FPスタイルのティラミスのレシピは次のようになる。
def make_tiramisu(eggs, sugar1, wine, cheese, cream, fingers, espresso, sugar2, cocoa):
# 卵を泡立てる(不変)
beat_eggs = beat(eggs)
# 卵と砂糖、ワインを混ぜる(不変)
mixture = beat(beat_eggs, sugar1, wine)
# 湯煎で泡立てる(不変)
whisked = whisk(mixture)
# マスカルポーネチーズを泡立てる(不変)
beat_cheese = beat(cheese)
# チーズと卵を混ぜる(不変)
cheese_mixture = beat(whisked, beat_cheese)
# 生クリームを泡立てる(不変)
whipped_cream = whip(cream)
# 生クリームをチーズミックスに加える(不変)
folded_mixture = fold(cheese_mixture, whipped_cream)
# エスプレッソに砂糖を溶かし、レディーフィンガーを浸す(不変)
sweet_espresso = dissolve(sugar2, espresso)
wet_fingers = soak2seconds(fingers, sweet_espresso)
# ティラミスを組み立てる(不変)
assembled = assemble(folded_mixture, wet_fingers)
# ココアを振りかけ、冷蔵する(不変)
complete = sift(assembled, cocoa)
ready_tiramisu = refrigerate(complete)
return ready_tiramisu # ティラミスが完成
- 不変(イミュータブル)なデータを扱う: 各ステップは、変数を再利用せずに、新しいデータを作成する。たとえば、
mixtureはbeat_eggsから生成され、さらに新しい変数whiskedが生成される。データが不変であるため、各ステップは他のステップに影響を与えない。 - ステップ間の独立性: 各関数は独立しており、順序に依存しない部分が多い。たとえば、エスプレッソがまだ準備できていなくても、他のステップを進めることができる。
- 並行処理が可能: 複数の部分を同時に処理することが容易である。たとえば、生クリームの泡立て (
whip(cream)) と、エスプレッソの準備 (dissolve(sugar2, espresso)) は独立して行うことができる。
関数型プログラミングによるリファクタリング
FPの利点の一つは、リファクタリングが容易である点だ。FPスタイルのコードはデータの依存関係が明示的であり、手順の変更や並列処理の適用が容易だ。以下の図は、ティラミスのレシピをFP的に表現したもので、どの部分が並行して実行できるかが一目で分かる。
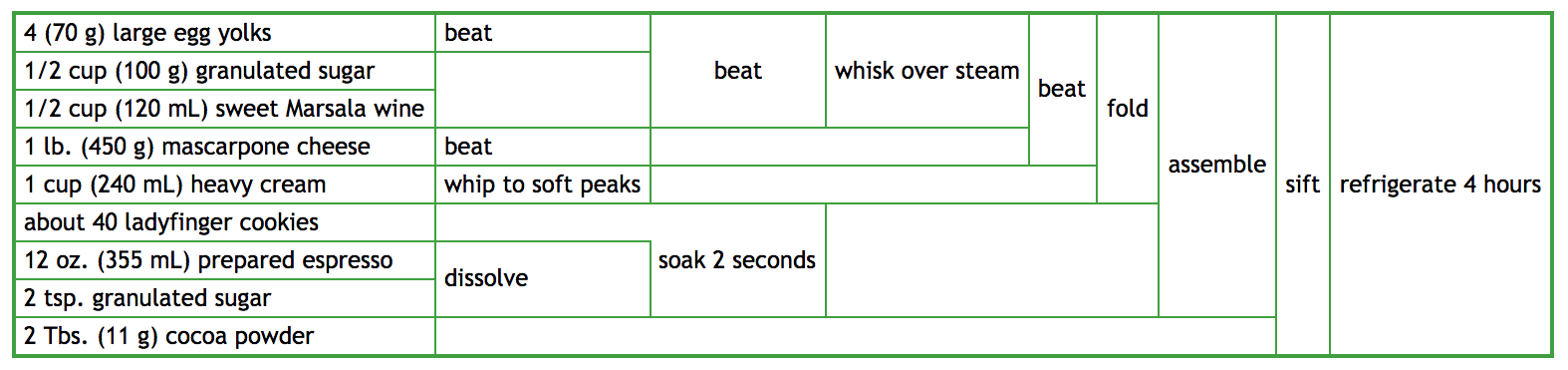
この図をもとに、どの部分を並列化できるかをすぐに判断できる。例えば、クリームの準備とチーズの準備は同時に進めることが可能だ。
関数型プログラミングの本質
FPの本質は、データフローに焦点を当てている点にある。各ステップが独立し、どのデータがどの段階で処理されるかが明確に示されているため、バグの原因となる複雑な状態の依存関係を避けられる。
たとえば、命令型プログラミングでは、エラーが発生した際に「どこで何が間違っていたか」を追跡するのが難しい。FPでは、データの流れがはっきりしているため、バグの発見が容易で、修正にかかる時間が大幅に短縮される。エラーメッセージやデバッグの結果も、具体的にどのデータが問題の原因となったのかを把握しやすい。
具体的な例を挙げると、fold関数が期待通りに動作しなかった場合でも、FPのコードではその前段階で何が起こっていたかが明確なため、すぐに原因を特定できる。例えば、whip関数やbeat関数の結果に問題があるかもしれないという仮説を簡単に検証できる。
関数型プログラミングの実践的な利点
FPのもう一つの大きな利点は、コードの再利用性と保守性の高さだ。FPでは、同じ関数を様々なコンテキストで再利用することが容易だ。関数が不変なデータを処理するため、どこで使っても副作用を心配する必要がない。
たとえば、ティラミスのレシピで使ったwhipやfoldといった関数は、他のデザートや料理でもそのまま利用できるだろう。同じ考え方で、プログラム内のロジックを再利用しやすくなる。こうした再利用可能なコードを持つことで、プロジェクトが成長してもコードベースが膨らみすぎず、シンプルさを保つことができる。
加えて、FPの特性を活かすことで、コードの変更が安全かつ迅速に行える。例えば、新しい要件が追加された場合、FPスタイルのコードでは既存の関数やロジックを壊さずに新しい処理を追加することができる。これにより、開発スピードが向上し、リリースサイクルも短縮される。
まとめ
関数型プログラミングの本質は、データフローを中心に考えることだ。この考え方を取り入れることで、コードの効率化、並列処理のしやすさ、デバッグの容易さといった実践的な利点が得られる。また、関数の再利用性が高いため、プロジェクト全体の保守性が向上する。FPを理解し、活用することで、開発者は効率的で保守性の高いプログラムを作成できるようになるだろう。
具体的な場面でFPの威力を実感しながら、その利点を最大限に活用して、次のプロジェクトに挑戦してみてほしい。
詳細は[What's Functional Programming All About?]を参照していただきたい。