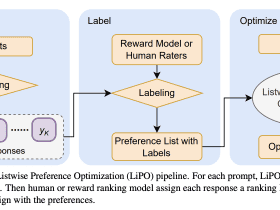
Google AI Research Introduces Listwise Preference Optimization (LiPO) Framework: A Novel AI Approach for Aligning Language Models with Human Feedback
DRANK
Aligning language models with human preferences is a cornerstone for their effective application across many real-world scenarios. With advancements in machine learning, the quest to refine these models for better alignment has led researchers to explore beyond traditional methods, diving into preference optimization. This field promises to harness human feedback more intuitively and effectively. Recent developments have shifted from conventional reinforcement learning from human feedback (RLHF) towards innovative approaches like Direct Policy Optimization (DPO) and SLiC. These methods optimize language models based on pairwise human preference data, a technique that, while effective, only scratches the surface of potential optimization strategies.