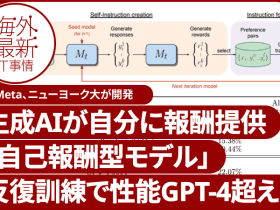
AIが自分自身に報酬を与えて進化する「自己報酬型言語モデル」 米Metaなどが開発、実験でGPT-4を上回る【研究紹介】
ARANK
米Metaなどの研究者らは、LLMが自分自身に報酬を与えることで繰り返し学習する「自己報酬型言語モデル」を提案した。このモデルは、自身が生成した問題に対する応答に報酬を割り当て、その結果をトレーニングデータとして使用。自己を反復して訓練することで、精度を向上させられる。