
本セッションの登壇者
セッション動画
どんなに著名なOSSであっても、利用法によってはパフォーマンスチューニングが必要になる場面が存在します。 今回は過去に体験した事例から、モニタリングの大切さについてご紹介します。
中西 建登と申します。インターネット上ではwhywaitaというユーザー名で活動しています。
サイバーエージェントに2019年新卒で入社し、社内向けのプライベートクラウド開発に従事しています。直近ではIaaSの開発や、myshoesというOSSとそれを用いたCIサービスの開発をしています。

ISUCON 8で学生時代に優勝したこともあり、ISUCON 10では運営(プライベートクラウドを使ったインフラの提供)もしています。

また、ISUCON本の第2章「モニタリング」と第9章「OSの基礎知識とチューニング」を担当しました。

なお、今回のセッションでは数年前に発生したKubernatesに関する事象をご紹介しますが、少し前の話ですので、あくまで「こういうこともある」という学びの共有として聞いていただければと思います。
事象が発生した環境: CAグループのプライベートクラウド
これからお話する事象が発生したのは、社内(CAグループ)向けに構築したプライベートクラウド環境です。
プライベートクラウドは
- 社内の需要にあわせた物理設計が可能
- 一括購入による費用面のメリット
という特徴があり、社内向けのチューニングしながら安価に計算機資源を利用できる環境を構築できます。
社内ではCy(berAgent)cloud - Cycloudとしてプライベートクラウドを提供しており、次のようなサービスを提供しています。
- IaaS (Infrastructure as a service - VM基盤)
- KaaS (Kubernates as a service)
- PaaS (Platform as a service)
- ML Platform (GPUが利用できるサービス)
- Cycloud-hosted runner (myshoes): GitHub actionsのCI基盤

このプライベートクラウドでは、最近はNVIDIA DGX H100を大量に導入したり(リリース)、ISUCON 10にインフラを提供しています。


Kubernetesの導入
このプライベートクラウドは、たくさんの物理サーバーを使って運用しています。
- 管理用プロセス向けサーバー: IaaSに使用するOpenStackの管理プロセスなどが動作
- ハイバーバイザー向けサーバー: ユーザーのVMが動作
- ストレージ向けサーバー: VM用のストレージ

プライベートクラウドを構成するコンポーネントの概要は次のとおりです。

われわれが提供しているのはユーザー(社内の開発者)向けのVM(図中の緑のコンポーネント)で、VM上で各ユーザーは開発したサービスを動作させています。

VM用のストレージは、ハイバーバイザーと同じ物理サーバーに置いてしまうと故障したときに移動・復旧が難しくなるため、別の物理サーバーに用意してネットワーク越しにマウントして利用しています。ハイバーバイザーが故障した場合には、他のハイバーバイザーからストレージをマウントし直して対応しています。

また、物理サーバー上にはOpenStackに関連するプロセスが多数動作しています。
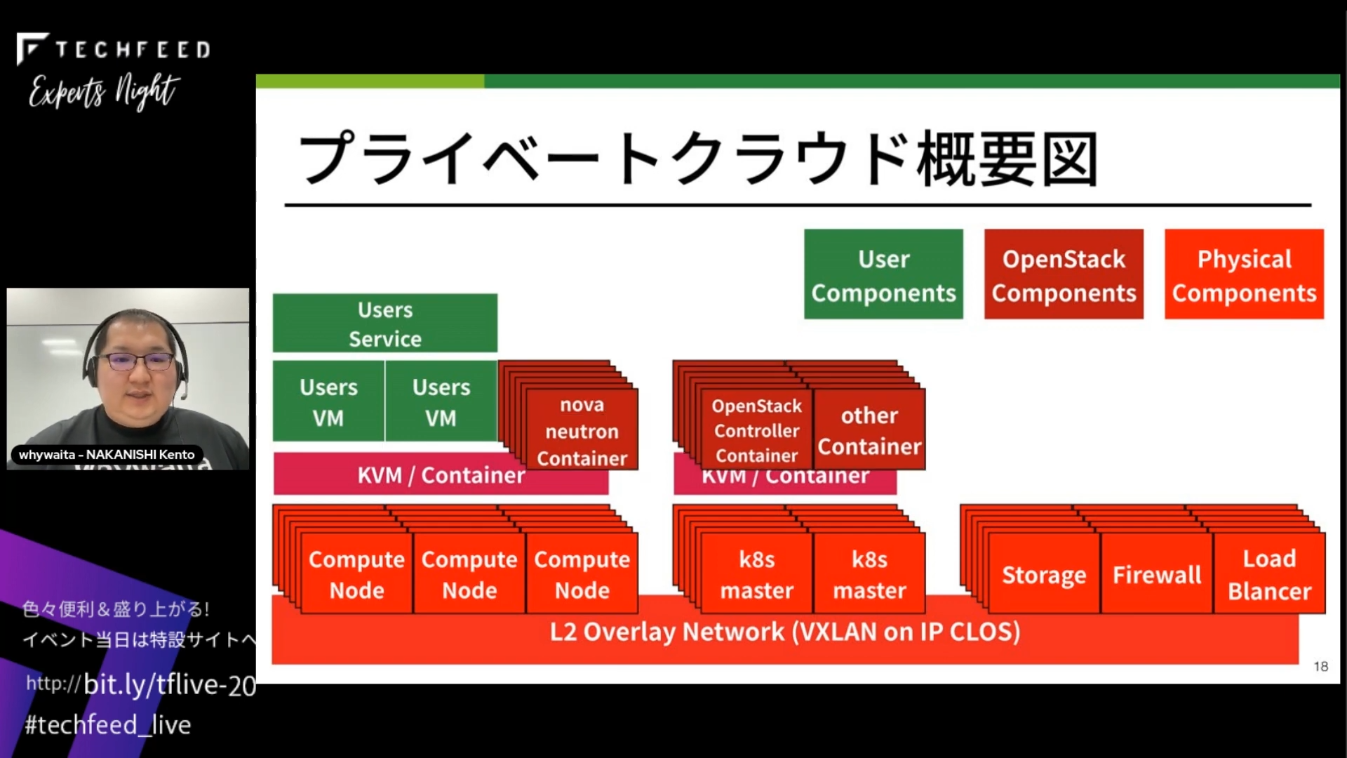
このように多数の物理サーバーとプロセスからなるプライベートクラウドを管理するため、Kubernatesを導入しました。
ハイパーバイザー向けの物理サーバーは、1台あたり96コア・1TBのメモリを搭載している大規模なもので、KubernetesのNodeとして管理しています。

また、管理用プロセスはそれぞれKubernetesのPodとして管理しています。

物理サーバーで管理用プロセスを動作させると、サーバー故障時の修復・プロセスの移動などの課題がありますが、これらの管理用プロセスをPodとして管理することで故障時に自動的に回復させたり、Node間で簡単に移動できるというメリットがあります。

トラブルとの出会いは突然に
しかしある日、ハイパーバイザーでCPU利用率の増加を示すアラートが発火しました。ハイパーバイザーのCPU利用率はユーザーのVMがCPUを利用した場合などに増加しますが、今回はそうではなかったためトラブルとして対処しました。

CPU利用率とは、単位時間あたりのCPUを利用している時間のことです。詳細な定義はISUCON本の第9章を参照してください。

調査1: 高負荷の大元を探る
プロセス一覧をモニタリングすると、KubernetesのNodeを管理するkubeletプロセスのsysという項目が高負荷になっていました。

kubeletはGo言語で書かれたツールなので、Goのプロファイリングツールであるpprofを使うと関数ごとのCPUの利用時間を確認できます。

プロファイル結果を確認すると、もっともCPU利用時間が長かったのはsyscall(OSのシステムコールを呼び出す部分)でした。syscallを呼び出している関数を順にたどると、libcontainerというライブラリのGetStats関数が契機になって、時間がかかるシステムコールが呼び出されていることがわかりました。

libcontainer (*Handler).GetStatsが呼び出している関数を順番に確認すると、fs getBlkioStatがあり、名前からするとブロックデバイスに関する情報を取得するのに時間がかかっていると考えられます。
また、GetStatsはKubernetesに組み込まれているメトリクス出力機能関連の関数だと推測できます。Kubernetesの内部では、google/cadvisorというライブラリを使ってメトリクス取得を行っています。今回問題になっているsyscallの大元を確認すると、/google/cadvisor/manager (*containerData).housekeepingという関数でした。

調査2: 高負荷になる理由を特定
kubeletがどのようにメトリクスを取得しているかを確認すると、cgroupfsを使ってメトリクスを取得していることがわかりました。cgroupというのはLinux Kernelが提供する、プロセスへのリソースの割当/調整を実現する機能で、cgroupfsはcgroupを仮想ファイルシステムから操作できるようにするものです。
kubeletはcgroupfsを通してコンテナの状況・ホストの状況をメトリクス化しているようです。

ここまでの調査で、どうやらこのcgroupfsが高負荷の原因になっている疑いがあり、cgroupfs周りでなにか時間がかかる処理をしていないかさらに調査しました。
調査にはBPFベースのツール群(bcc)の1つであるiovisor/bcc/opensnoopを使いました。このツールを使うと、各プロセスがopen(2)しているファイルをtraceでき、どのファイルを開くのに時間がかかっているのかを確認できます。

下記はopensnoopの実行例です。-pオプションでプロセスIDを与えると、そのプロセスがopen(2)したファイルとかかった時間を確認できます。

これを使ってkubeletがopen(2)したファイルのうち、cgroupfsでマウントされているファイルを中心に実際にcatで内容を読み出すのにかかる時間を確認しました。

その結果、/sys/fs/cgroup/blkio/blkio.throttle.io_servicedを開くのに3.5秒、/sys/fs/cgroup/blkio/blkio.throttle.io_service_bytesには4.5秒もかかっていていることがわかりました。

kubeletが定期的にメトリクスを取得するたびにこのようにopen(2)に時間がかかるcgroupfsのファイルを使用するため、メトリクスの取得間隔が短ければ短いほどCPUの高負荷につながってしまいます。
原因判明: ディスク数とネットワーク環境
ところで、blkio.throttle.io_servicedはディスクとの転送量ですが、ここでVM用のストレージはネットワーク越しにマウントしていることに着目します。


1台の物理サーバー上では多数のVMが動作しているため、VM起動用に非常に多くのディスクが接続されています。このような環境でkubeletがホスト上のディスクに関するメトリクスを取得すると、ディスク数に比例してメトリクス取得にかかる時間が増大してしまいます。
さらに、当時の状況(特にネットワーク的な要因)でcgroupの動作が遅延していたのもあり、kubeletの処理時間が長くなり、CPU利用率も増加していました。

なお、同様の問題は2016年5月に報告されているのですが、現在もopenのままなので奥が深い問題だと思っています。

正しいモニタリングが重要
Kubernetesを使って管理しているプライベートクラウド環境での過去の事象をご紹介しました。
Kubernetesはかなり広く使われている著名なプロダクトですが、パブリッククラウド上で使う場合もあれば、われわれのようにプライベートクラウドで使う場合もあり、さまざまなユースケースが存在します。そして、ユースケースが多様化すると、起こるトラブルも多様化します。
多様なユースケースでどんなトラブルが起きるかを予測することはできないので、問題が起きたときにはいち早く発生に気づいて要因を調べられるように、正しくモニタリングしていくことが重要です。
モニタリングに関してはISUCON本の第2章でも詳しく解説していますので、気になる方はぜひご覧ください。

ご清聴ありがとうございました。