
本セッションの登壇者
セッション動画
では、「LLMをファインチューニングして対話用のLLMを作成する」というタイトルで、株式会社ACESの久保が発表させていただきます。
まず、自己紹介なんですけれども、改めまして久保と申します。現在、株式会社ACESという会社で働いておりまして、会社としては行動属性のデジタル再現だったり、車両の内外データの活用、特にLLMに関わってくるコミュニケーションの科学など、画像認識や音声認識の領域で幅広くやっています。Twitter等もやっているので、よろしければフォローしてください。

LLMはこうやって活用できる
LLMの活用ではたとえば、ACES Meetというプロダクトを開発しています。この発表のように、オンラインで会話することも増えてきているご時世です。特に営業の分野で、音声認識で動画内の会話を書き起こして、LLMを使ってAIまとめを自動生成するという機能を開発してプロダクトに搭載しています。詳細はブログにも書いていて「ACES AIまとめ」などで検索すると出てくると思いますので、ぜひ見ていただければと思います。

あとは、ACES ChatHubと銘打ってチャットボットの開発も行っております。社内に溜まっているデータやいろいろなファイルがあると思いますので、それを登録して、そのデータを元にしたチャットのやり取りができるプロダクトになっておりまして、ChatGPTをイメージすればわかりやすいかと思うんですけれども、文書を参照しながら回答してくれるチャットボットも作成していて、ここでもLLMを活用しています。

このようにいろいろ活用しているというお話もしたいところではあるんですけれども、今回はファインチューニングして対話用のLLMを作成するお話をします。

事前学習モデルを学習したら対話用にチューニングが必要
ここでは、皆さんご存知のChatGPTのように何か聞いたら答えてくれるものを対話用LLMと呼んでいます。

ChatGPTは、OpenAIによって開発されたLLMで対話用にチューニングされています。私がAIに関わりだしたのは2015年くらいで、その時も結構AIブームとは言われていましたけれど、最近はCNNやRNNからTransformer、BERTやGPTが出てきてといったように、いろいろと発展してきた中でChatGPTが去年の11月にリリースされて、そこから公開2ヶ月でユーザーが1億人を超えるという、これまでのAIブームよりまた一段と強いブームになっています。そういったChatGPTなどが対話のモデルにあたります。

このChatGPTですが、どういうふうに学習されているのかを簡単に示すと、GPT-3のような事前学習モデルをまず学習して、それを事後学習という、後で説明しますけれども、人間の好みに合った出力文の調整、対話用のチューニングを行って、ChatGPTのような対話モデルができます。今回焦点を当てたいところは、この事後学習のところです。

事前学習は非常に高価、事後学習が勝負を分ける
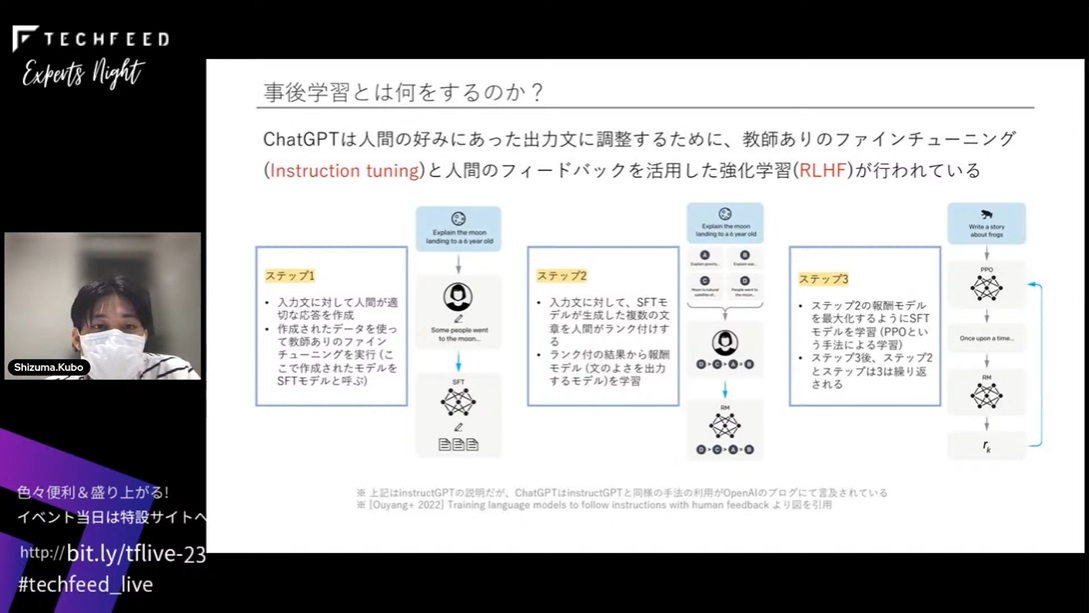
事後学習とは何をするかと言いますと、大きく2つあります。教師ありのファインチューニング(Instruction tuning)と、人間のフィードバックを活用した強化学習(RLHF)です。
図のステップ1からステップ3に書かれているようなことをやっているんですけど、雰囲気だけ伝わればよいのでそのつもりで聞いてください。
一番左のステップ1では、事前学習済みのLLMに対して、人間が作った入力文とその答えを学習データにして学習させます。それによって、人間が生成したような応答ができるものを作るというのがInstruction tuningにあたります。その後のステップ2では、人間が正解データを作るだけじゃなくて、LLMに質問を投げていくつか回答を生成します。その中でどの回答がいいか手動で順序付けを行って、その順序によって文章を評価するモデルを作成します。ここでは、報酬モデルと書いていますけれども、報酬モデルとは文章を入れたら10点とか5点とか点数を返してくれるようなモデルです。ステップ3では、この報酬モデルを使って強化学習をして、高い点数が出る文章を生成するようモデルを学習させます。このステップ2からステップ3がRLHFの領域です。ChatGPTは事前学習モデルを前提にしつつ、こういう形でInstruction tuningとRLHFという事後学習を行っています。
今までの話をまとめますと、LLMの学習は事前学習とInstruction tuningとRLHFという3つのステップです。特に、この事前学習はすごいコストがかかるところで、その後のInstruction tuningやRLHFが現実的に学習ができるところになってきます。
事前学習は学習にかなり大量のデータや計算リソースが必要になり、このフェーズで知識が獲得されると言われているんですけど、学習自体は大量の文書を用意して次の単語を予測するものです。OpenAIがGPT-3を作る時に5億円かけたという話もあるように、それぐらいお金がかかるのが事前学習です。今ならもっとパラメータ数やデータ数が増えているのでもっと高額になると思います。Instruction tuningやRLHFは比較的少ないデータ量であっても効果があって、数千件や1万件でも効果がけっこう現れてくる領域です。事前学習のところもファインチューニングできることはできますが、ここではInstruction tuningとRLHFに着目していきます。

チューニングをやってみよう
実際にファインチューニングを行うためのステップとしては、事前学習で公開されているものに対して、Instruction tuningやRLHFを行っていくというステップになります。

公開されている事前学習済みのモデルから、日本語のLLMとして有望な言語モデルを抜粋しました。CyberAgent社が出しているOpenCALM、Rinna社が出しているjapanese-gptモデルがあります。70億パラメータ、36億パラメータという、日本語のLLMとしてはかなり大きいものになっています。オープンソースで公開されているモデルは英語で学習されているものが多くて、日本語の出力の能力が必ずしも高いと言えない傾向にはあります。一方、日本語で学習されたモデルは、いずれも英語のモデルに対してはデータセットのサイズも小さいですし、物足りないところはあるんですけれども、ファインチューニングをすることによって、精度感を高めることができます。

具体的に何をやるかと言うと、ここに先ほどの各モデルを割り当てています。CyberAgent社が出しているOpenCALMは、先ほどの事前学習を行ったモデルにあたります。Rinna社も事前学習済みのモデルを出していますが、Instruction tuningやRLHFをすでに行ったようなモデルも公開しているので、この辺りは自分で学習しなくても触ることができます。今回やるものとしては、パラメータ数もRinna社のモデルと比べても大きいOpenCALMの事前学習済みのモデルを使って、Instruction tuningをやってみます。

実際に行った結果はこちらです。ここで1個目の実験としてはdatabricksが出している、人手で作成した15000件のデータセットを使っています。もともとの英語を日本語に翻訳したものです。70億パラメータのOpenCALM-7Bを使って、LoRAチューニングで学習させました。結果だけ見ると、皆さんGPT-3、GPT-4に慣れてしまっていると思うので「当たり前じゃないか」みたいな感じだとは思うんですけれども、「人工知能って何?」と聞いても「広島の世界遺産を教えて」と聞いても、しっかりと回答してくれます。Instruction tuningをしないと、日本語に対してちゃんと日本語で返ってくるというところはなかなか難しいんです。Instruction tuningをしっかりやることで、みなさんが使っているChatGPTと同じような出力が返ってくるというのは、なかなかすごいことではあります。

意図する回答ができるようにチューニングする
2個目の実験として、社内ドキュメントを使った学習もしました。データセットとして社内のドキュメントを活用して、QAデータセットというものをLLMで生成しました。学習は同じような形で行いますが、社内規定などのPDFで書かれたデータをコンテキストとして入力して、そのドキュメントの内容に書かれているものを質問するということを行っています。知っている知識じゃなくて、問題設定として与えられたコンテキストを理解して質問に回答するのが先ほどとは違う形ですね。
例として「正社員と時短正社員の違いは何ですか?」と質問しています。これは弊社の時短正社員というのが結構特殊なので、何も情報を与えられないと答えられない質問ですが、「正社員と時短正社員の違いは勤務時間です」とちゃんと返してくれます。「時短」と付いているので、何も知らなくても勤務時間に関係する答えを返せそうな気もするんですけれども、他のモデルだとかなり崩壊したり、全然違うことを言ったりします。たとえば、ファインチューニングしないモデルの場合は、コンテキストに含めたドキュメントの内容をただオウム返しにそのまま返すだけだったり、1枚前のdatabricksのデータで学習したようなモデルであっても、なかなか返答がうまくいきませんでした。データセットやコンテキストを含めて学習させることで、入力に対して意図する生成、回答ができるようになってくるというところが、ファインチューニングの良さですね。

ファインチューニングをすると何が嬉しいのかというと、ちゃんと喋るようになるのもそうですけれども、プライベートな環境でLLMを動作させられることがあります。ChatGPTやGTP4ではセキュリティ的な要件が厳しい、オフライン環境で利用したいというときは、手元で活用できるオープンソースで商用利用可能なLLMをファインチューニングして、活用できる精度にして使うことができます。ただ、高い性能で日本語ができる対話用チューニング済みモデルなら、ファインチューニングしなくても、そのまま使えます。一方、特定の領域の専門用語や独特な言い回しを反映させたい場合や、用意したデータセットに沿う形で出力させたい場合は、ファインチューニングするといいかと思います。汎用的な文脈のLLMのデータ量が増えているので、対応するプロンプトのチューニングでも十分対応できる範囲も広がっています。局所的に活用したい、学習させたいケースなど一定の活用の幅はあるかと思います。

LLMはオープンソース化の流れ
LLMのファインチューニングの話ではあったんですけど、事前学習済みのモデルの精度が、やはりファインチューニング後の結果にも大きく影響をしているというところで、LLMがどう公開されるかというのは重要です。Meta社のLlama2や、日本語のLLMは比較的少ないですが、動きはいくつか存在しています。商用利用可能でチャット用にチューニングされたモデル、かつChatGPTを上回るスコアのLlama2が公開されたのはすごく嬉しく思いますし、活用の幅が広がるかなと思います。ただ、ちょっと私の試し方が良くなかったかもしれないですけど、日本語性能が高いかは微妙だったので、このあたりはアップデートが来るのが楽しみというか、何かやってくれるかなというのを期待しているところではあります。

まとめです。

以上になります。ありがとうございました。
※ 登壇者様の登壇レポートも合わせてご覧ください。