
本セッションの登壇者
セッション動画
よろしくお願いいたします。今日は「OpenAIのSDKとEmbedding APIのご紹介」ということでお話しします。
APIとSDKはAzureとOpenAIで同じ
今日は時間もないので自己紹介を飛ばしまして、早速APIのあたりからご紹介していきたいと思います。まずSDKは本家のOpenAIのdocs/librariesにPython、Node.jsやコミュニティの方々が作ってくださったライブラリがありますので、こちらをご利用いただくとよいかと思います。

また、私が所属しているマイクロソフトでもOpenAIに関するSDKを提供しておりまして、素のREST APIを使った呼び出しからC#用のライブラリ、Java用のライブラリ、JavaScript用のライブラリといったさまざまな言語に対応したライブラリを商用サポート付きで提供しておりますので、ご利用ください。こちらのAPIを使用してマイクロソフトのAzureのOpenAIにも通常のOpenAIにも接続できますので、同じSDKを使って、必要に応じて使い分けができます。

今日は、細かい部分についてのお話は時間の関係上できないんですけれども、ブログでいろいろなAPIを使ったサンプルのコードや技術的な紹介を行っております。私はJavaの人間なので、Javaのサンプルをお届けしているんですけれども、もちろんJava以外にC#やJavaScriptのサンプルもいろいろなマイクロソフト社員が作っておりますのでご覧ください。

ベクトル化して関連度を評価するEmbeddingモデル
今日のメイントピックは、Embeddingです。組み込み、埋め込みとも言われます。
こちらもQuitaブログに細かい内容を書いておりますので、今日の私の発表ではちょっと物足りない、もう少し詳しく知りたいという方がいらっしゃいましたら、こちらのブログもご参照いただけると嬉しいです。今日はかいつまんでご紹介していきます。そもそもEmbeddingが提供されているのには理由があります。

こちらのブラウザをご覧いただきたいんですが、AzureのOpenAIのプレイグラウンドのサイトです。ここでたとえば「Azure OpenAIについて教えて下さい」というふうに質問すると、GPT-4を使ってこういった回答が返ってくるんですけれども、これがどういったデータをもとに返しているかというと、すでにOpenAIが学習した情報をもとに答えを作り上げています。ただ、今世の中に公開されている情報だけを使いたいかというと、決してそうではないですよね。社内の情報や蓄積した情報でGPT-4を活用できるようにするために、このEmbeddingというテクノロジーを利用します。

Embeddingとは具体的にどういうものなのかというと、たとえば今回、「Azureについて教えて下さい」という文字列でGPTに対して問い合わせを行いたいと思います。実際にはこのように文字列を多次元の配列に置き換えて、これをベクトル表現として表します。ベクトルというのは、高校時代に習ったベクトルと一緒で、向きと長さが非常に重要です。ここでは簡単に2次元のベクトルを表しているんですけれども、実際にはこれが1500次元といったもう人間には想像もつかないような次元のベクトルで内部的には表されています。わかりやすいように2次元で表すならば、まったく同じ向きで、まったく同じ長さのものというのは、すべてが一致したものになるんですね。似たようなドキュメントとか、テキストを探し出したいという場合には、この青い線に一番近いところの線と傾きを探せば、それが最も類似したドキュメントになります。こういった概念をもとに、配列を比較して類似のドキュメントを探すというのがEmbeddingの考え方になります。

実際にこの中でどういった計算をするのかというと、先ほどすごい多次元の配列がありますよと言いましたが、これをコサイン類似度みたいな計算式に比較する2つの配列を代入します。結果でマイナス1というのはもう真逆のまったく違う内容ですが、1に近づいてくるほど、より近い値になってきます。

これをたとえばJavaで表すならば、こういった関数を使ってコサイン類似度みたいなものを計算することもできます。多次元のベクトルを引数に入れて、コサイン類似度の計算をして、その結果が1に近いものを探すというものになっています。

わかりやすいように今回、入力されたオリジナルのテキストが2行目にある文字列だったとします。この文字列に一番近い文字列は何かを探すときに、実際にコサイン類似度で計算をさせると、下から3行目に0.99429というのが出ています。表している文字列はJが1個抜けただけですので、これが一番類似度が高いですよね。このように1に一番近いものを探し出す手法を取っています。実際のコーディングや本番環境では、先ほどご覧いただいたようなコサイン類似度というのを毎回皆様が書く必要はなくて、検索エンジンやデータベースといった裏側の部分で自動的に計算してくれます。

クエリを超多次元配列に変換
実際に私が試したものとして、PostgreSQLのpgvectorというものを使ってこういったクエリを投げると、embedding <-> の処理で、入力した多次元の配列ARRAYの上位5つを取ってきます。

では、実際にやってみましょう。こちらが今、Postgreに接続しているんですけれども、先ほどご覧いただいたクエリでPostgreで配列を当て込んだ例を実行します。これは何を聞いているかというと「AzureのOpenAIについて教えて下さい」です。
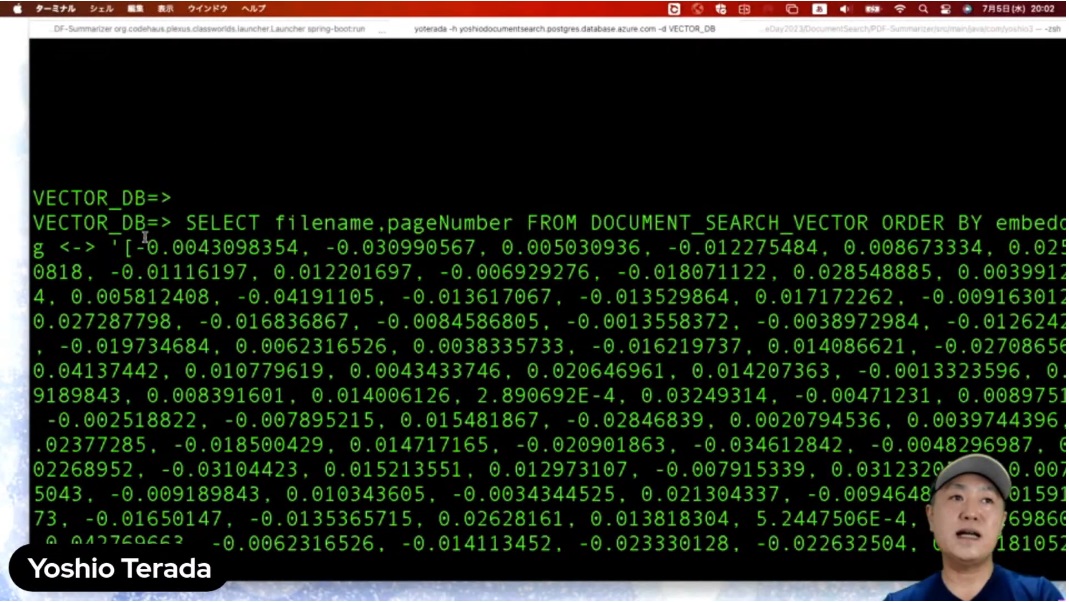
結果がこのような形で返ってきます。

実際にこれをもう少しソースコードレベルで紹介します。入力された文字列をembeddingoptionsという変数に入れて、それに対してtext-embedding-ada-002というEmbeddingモデルを使って呼び出しを行います。その結果が変数 embeddingで、返ってくるのは下にある配列になります。この配列に対して比較を行います。今なんとなくこのソースコードを見て、text-embedding-adaを呼び出すとこんな配列が返ってくるんだなというのは、皆さんちょっとイメージできたかと思うんですけれども、それが実際にどうやって使えるのかというあたりを最後にご紹介したいと思います。

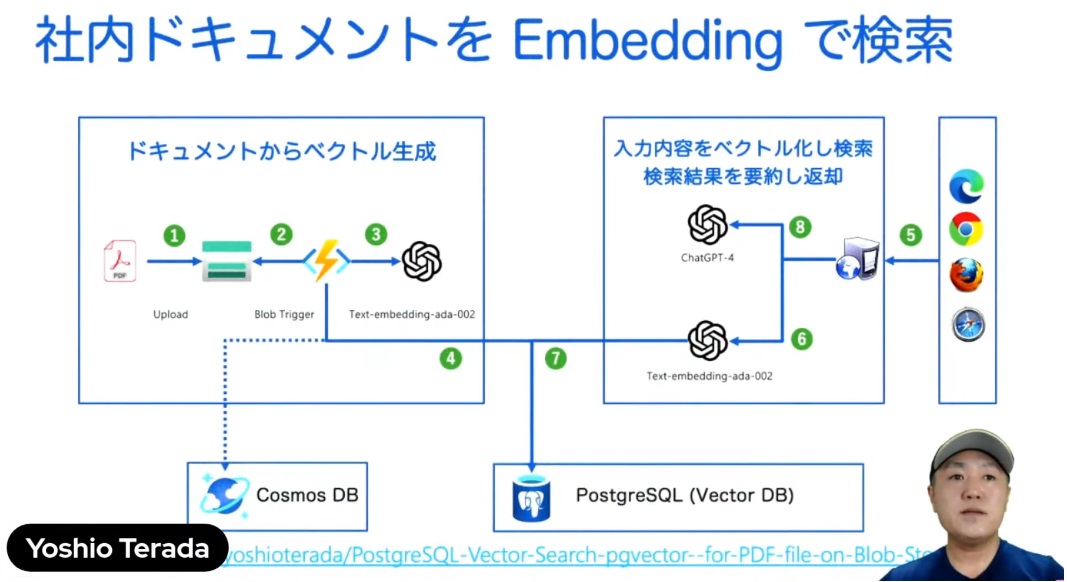
たとえばこんなことができます。皆様の社内にある大量のPDFドキュメントをAzureのストレージにアップロードすると、自動的にそれをトリガーにして内部的にPDFを解析してテキストにします。テキストにした後に、embedding-adaを呼び出して、配列化します。先ほどの多次元配列を作ったら、各ページごとにPostgreSQLに入れます。この状態でユーザー側からたとえば「OpenAIについて教えて下さい」って入ってくると、もう一度text-embedding-adaを呼び出して、同じように問い合わせに対する配列を作るんですね。この入力された配列とデータベースに保存されている配列を比べて、1に一番近いものを返すということで、社内文章の検索なども非常に簡単にできるようになります。
こちらの部分は下のURLにソースコードもすべて公開しています。
AIと組み合わせて複合処理も可能に
実際にちょっと動かしてみたいと思うんですけれども、「AzureのOpenAIについて教えて下さい」と、今、問い合わせを行いました。そうすると似たようなドキュメントはこういったものですよというのが出てきました。その結果から、さらにGPT-4に「これをサマライズして下さい」とサマライズさせた結果を今ご覧いただいています。

このように、「AzureのOpenAIについて教えて下さい」という文字列を配列化して、配列の中で比較して、一番類似したドキュメントを探して、それに対してサマライズをして出力する例をご紹介しました。皆様の社内の情報やデータをうまく使って、さらにGPT-4を組み合わせて、より良いサービスを作っていくといったことが、このEmbeddingの機能を使って実現できるようになります。
以上で私の発表を終わりにしたいと思います。どうもありがとうございました。