
本セッションの登壇者
セッション動画
GMOペパボの伊藤洋也です。2007年からGMOペパボにて勤務しており、ホスティングサービスや技術基盤チームを経て現在はセキュリティ対策室に所属しております。オンラインではTwitterおよびGithubのアカウントとブログで活動しています。今回は実際のサービス環境でのLinuxカーネルのトラブルシューティング事例とともに、カーネルの詳細調査やコードリーディングの方法をご紹介します。
私はLinuxカーネルのコミッターをしているわけではなく、またLinuxカーネルの開発業務もさほど行ってはいないのですが、ときどきLinuxカーネルのトラブルシューティングをすることがあるので今回はそのお話をします。
2007年からGMOペパボのサービスに関わっていますが、Linuxカーネルの問題に遭遇することはときどきあります。一般的に「Linuxカーネルのトラブルにはどのようなものがあるか」をChatGPTに質問すると、このようなリストがでてきます。
- パフォーマンスの劣化
- カーネルパニック
- メモリリーク
- レースコンディション
- デッドロック
- 脆弱性
- ハードウェアとの互換性問題
- …etc

トラブルシューティングの際にLinuxカーネルのコードまで潜り込むには、次のような動機があります。
- 問題を解決(緩和)してサービス/システムの安定性を確保するため
- 問題を再現する/再現のヒントを得るため
- 問題を理解し、同僚に説明するため
- 問題の再発防止のため (監視に使えるデータがないか探すため)
- 単純に実装に興味がある

トラブルシューティング事例
ここからは過去(数年前を含む)に遭遇したトラブルシューティング事例をご紹介します。これらの事例はGMOペパボのSaaSサービス/ホスティングサービスを提供する下記いずれかのLinuxサーバで発生したものです。
- オンプレミス環境のカーネル
- プライベートクラウド(OpenStack/KVM)環境
- ゲストVMのカーネル
- ホストマシンのカーネル
- パブリッククラウド環境のカーネル

事例1 ‐ CPUのシステム時間(%system)のスパイクによるパフォーマンスの低下

「CPU %systemのスパイク」はよく遭遇するものですが、一例として下記の環境で発生したトラブルをご紹介します。OpenStack環境でvCPU(仮想CPU)をたくさん持つゲストVMがあり、内部では比較的大きなmysqldを動作させていました。また、ホストではwazuhというセキュリティ関連のプロセスが動作しており、セキュリティチェックのためにさまざまなファイルをread(2)していました。
トラブルの症状は、ゲストVM内のmysqldの監視で接続断を知らせるアラートが発生したり、同時にホストのCPU %systemがスパイクしていたというものです。

問題を調査したところ、ゲストVMのページフォルトとホストのslab回収処理が並行し、スピンロックが競合していることがわかりました。ゲストVMでページフォルトが発生したときに、ホストのカーネルモードで処理されるtdp_page_fault()関数とホストのslab回収処理から呼び出されるmmu_shrink_scan()関数の両方がstruct kvmのmmu_lockというスピンロックを取得しようとして競合していました。
ワークアラウンドとしてwazuhプロセスをcgroupのメモリ制限下に入れることで、slab回収処理とVMのページフォルト処理でスピンロックが競合しないようにして問題は解決しました。

こちらのスクリーンショットは、調査の際にperf top というツールでプロファイルを取得したもので、_raw_spin_lockという表示が見えます。

事例2 ‐ カーネルのバグによるCPU %userのスパイク

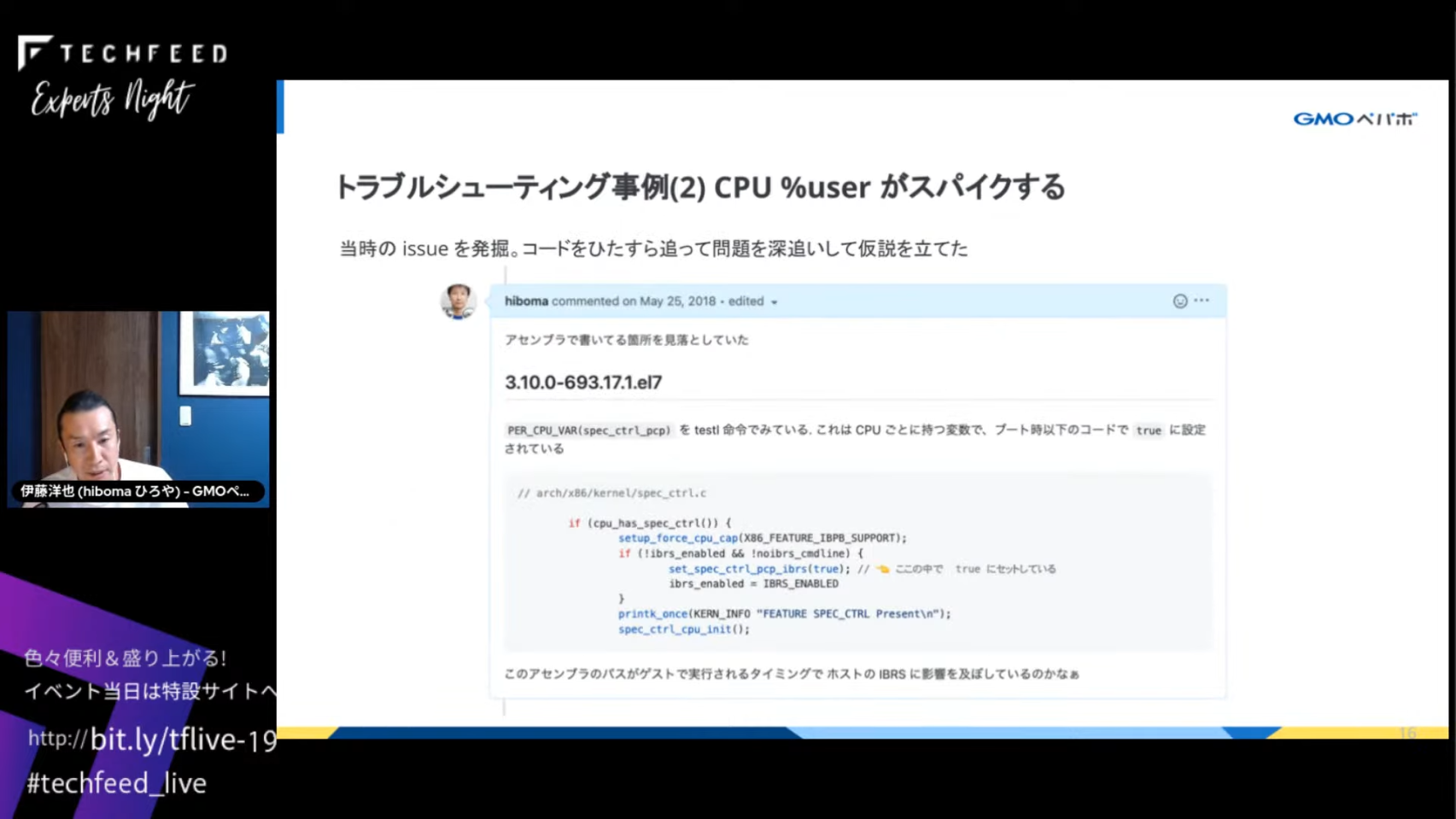
こちらは比較的珍しい問題ですが、2018年ごろのSpectre/Meltdown脆弱性対応の修正カーネルが続々と出ていたころの事例です。OpenStack環境で、ゲストではCentOS 3.10.0-693.17.1.el7.x86_64、ホストではUbuntu 4.4.0-119-genericカーネルが動作していました。
トラブルの症状は、問題のカーネル(3.10.0-693.17.1.el7.x86_64)が動作しているCentOSのVMでなぜかCPU %userが高くなるというものでした。Webサービスのロールで冗長構成をとっていたため、複数のカーネルバージョンが混在していましたが、このバージョンのみ異常を示していることに監視データを見て気づきました。さらに、このカーネルのVMが起動すると、なぜか同じホストの他のVMでもCPU %userが高くなるという症状もありました。

ソースコードにも踏み込んで調査したところ、問題のカーネルではIBRS(Indirect Branch Restricted Speculation: Spectre脆弱性を緩和するためのレジスタ処理)にバグがあり、意図せずホストのIBRS機能を有効**にしていました。IBRSはSpectre V2の脆弱性を緩和できましたが、同時にCPUパフォーマンスを著しく低下させるという副作用がありました。
解決策として、問題のカーネルを利用しているVMをすべて洗い出し、カーネルをアップデートして対応しました。1台でも問題のカーネルを利用するVMが起動すると他のVMに影響を与え、またVMを別のホストにlive-migrationすると症状が伝染してしまうため、根絶する必要がありました。

当時はレジスタ周りを調べる方法がわからなかったため、IBRSに関連しそうなソースコードをひたすら読んで問題を突き止めました。
事例3 ‐ sysfsファイルのリーク
コンテナ環境を提供するGMOペパボのホスティングサービスで、メモリcgroupを作成するとslab cacheのsysfsファイルが生成されますが、その後cgroupを削除してもsysfsファイルが残るというバグに遭遇したことがあります。

興味深いバグだったため、詳細や修正パッチを調査してコンテナ技術の情報交換会で発表しましたので、詳細は資料をご覧ください。

事例4 ‐ TCP: out of memory
トラブルシューティングではdmesgに出力されるログを調査することがよくありますが、「TCP: out of memory – consider tuning tcp_mem」(以下、TCP OOM)というログを調査した事例をご紹介します。

TCP OOMが発生していたのはOpenStack環境で、haproxyを載せたVMです。haproxyはOpenStackのL7ロードバランサーサービスOctaviaとして動作していました。トラブルの症状は、haproxyを介してのTCPデータ送受信が極端に遅く、同時にdmesgにTCP OOMメッセージが出力されていました。

問題そのものはsysctl net.ipv4.tcp_memをチューニングして解決できましたが、net.ipv4.tcp_memやTCP OOMについて調査してもカーネル内部まで踏み込んで十分に説明されているサイト/文献が見当たりませんでした。また、再発防止のためにどのように監視するべきかも課題でした。

そこで、TCPスタックに関連するソースコードを調査し、弊社のテックブログにまとめました。TCP OOMについて日本語でもっとも詳しくまとめられたと思いますので、興味がある方はご覧ください。

Linuxカーネルのトラブルシューティングで使うもの
私がLinuxカーネルのトラブルシューティングを行う際には、まずこれらのデータやツールを利用します。
dmesgのログperfコマンド/proc/$pid/wchanや/proc/$pid/stack/proc/*や/sys/*のファイルsysrq-triggerでダンプstrace・gdb- メトリクス

これらのツールでプロファイルを取ったり、ファイルを確認したりしてコードを探るためのログ、カーネルの関数、統計を探していきます。ただし、症状によってどの方法が適しているかは異なります。
トラブルシューティングでLinuxカーネルコードリーディングのコツ
コードを読むときは、問題のありそうな関数やログを端緒にgrep *(パターンマッチさせて検索)したり、GNU Globalを使っています。出てきたコードをすべて理解しようとすると大変なので、細部は読み飛ばして問題がありそうなところを読んでいくことが重要です(読み飛ばした部分が問題の核心である場合もたまにありますが)。

コードを読みながらWeb/書籍などさまざまな情報を収集し、解決の糸口を探したり問題の理解を深めます。2023年現在ではChatGPTを利用するのも選択肢としてありえます。

トラブルシューティングの難しさとやりがい
いろいろな情報を集めても確信を得られないときもあります。とくに問題が手元で再現できない場合は、仮説や推測をはっきり固めなければいけないので大変です。Web上で見つけた解決方法やパッチが本当に自分たちの問題を解決できるのかを確かめる必要があり、時間がかかってしまいます。

もちろんやりがいもあり、問題解決に導けるとうれしいということに加えて、教科書的ではない角度からLinuxカーネルの理解を深められるというおもしろさもあります。また、自分の問題としてトラブルシューティングで調べたり試したりしたことは記憶にも残りやすく、メンタルモデルとしてしっかり定着します。

まとめ
私が行っているトラブルシューティングは、既知の解決策やワークアラウンドを探し当てるのが精一杯です。パッチも書いてupstreamにコミットして解決している人たちは本当の達人で尊敬しますし、いつかは自分もチャレンジしたいと思っています。

ご清聴ありがとうございました。