
本セッションの登壇者
セッション動画
今から**kube-state-metricsに使われているシャーディング(Sharding)**について話していきます。発表者は黒澤といいます。今はZ Labという会社でKubernetesプラットフォームの開発をしたりしています。

kube-state-metricsとシャーディング
kube-state-metricsについて改めておさらいなんですが、KubernetesのAPIサーバを監視して各種オブジェクトの状態のメトリクスを提供してくれるコンポーネントです。Kubernetesを運用されている方ならお馴染みのコンポーネントかと思います。

シャーディングについてですが、一般的なシャーディングはデータをシャード(shard)と呼ばれる小さなチャンク単位に分割して、分割したデータを複数のマシンに分けて保存することで大規模なデータセットを管理する手法です。これは応答速度の向上のためによく用いられています。

これはAWSのブログから拝借してきた画像なんですが、よくあるデータベースのシャーディングの一例です。1つの大きなテーブルをシャーディングして分割する用途でよく使われます。

これをKubernetes controllerでシャーディングする方法に置き換えてみるとどうなるでしょうか。まずcontrollerですが、通常はリーダー選出でリーダーとなったPodのみがreconcileを行うというアプローチになっています。たとえばcontrollerのreplica podを3などにしても、実際に処理が行われているのは1台のみで、スケールしないような実装になっています。これについては過去に登壇している資料があるので興味のある方は参照してみてください。

ちょっと前に話題になった話なのですが、「Kubernetes controllerでシャーディングを試みる」というリポジトリを開発されている方がいて、Sharderと呼ばれるコンポーネントがラベルをオブジェクトに割り振って、どのシャードを処理するかを決定する処理を行っています。

今回はこちらの話はしませんが、kube-state-metricsにもシャーディングの実装が入っています。controllerではないですが、controllerも使用できるアプローチでシャーディングを行う機能が実装されているので、その紹介をしたいと思います。

kube-state-metricsの実装
具体的にkube-state-metricsのシャーディングがどういうことをやっているかというと、たとえば左側のAPIサーバにConfigMapが4つ登録されたとして、それぞれのPodがkube-state-metricsのレプリカです。合計4つのメトリクスが出るのですが、それぞれのPodで2分割されて出力されるのがkube-state-metricsがやっているシャーディングになります。

この機能は2018年12月に作られたプルリクエストが元になっていて、かなり前に実装されたんですが、導入の目的としてはkube-state-metricsでシャーディングすることで、処理するオブジェクトが減ってレイテンシを少なくするためだそうです。

ここからは実装を深掘りしていきたいんですけど、大きく分けて2つのことをやっています。
まず最初に、kube-state-metricsをStatefulSetで動かして、レプリカ数とPodの末尾の番号から何番目のシャードなのかを検出しています。
その次に、処理するKubernetesのオブジェクトのUIDを用いて、Consistent Hashすることで、処理するシャードを決定するという実装になっています。

kube-state-metricsをStatefulSetで動かす
まず最初の実装から見ていきます。これはStatefulSetでkube-state-metricsを動かす際のマニュフェストなのですが、引数にPodの名前とPodのネームスペースを取っています。

それから、実装側でPod名とネームスペースからAPIを叩いてPodオブジェクトを取ってきて、今度はOwnerReferencesを参照して、親のStatefulSetの情報を持ってきています。

StatefulSetのレプリカの数がシャード数の合計になっています。今度はPod名をパースして末尾の番号を取ることで、今自分が動いているシャードの番号が何かという情報を取得しています。

さらに、このStatefulSetはInformerでウォッチしていて、EventHandlerでアップデートとか起きたときにシャードの再設定とメトリクスのリセットが行われるようになっているので、HPAなどでStatefulSetがスケールした際にシャードの再割り当てを自動で行うことができるようになっています。


KubernetesのオブジェクトのUIDでConsistent Hashする
次の実装はKubernetesのオブジェクトのUIDを用いてConsistent Hashしているのですが、まずよく見るclient-goのアーキテクチャの部分をkube-state-metricsでも使用していて、主にReflectorというものを使用しています。

通常のCustom controllerだと、ReflectorはKubernetesのオブジェクトをlistやwatchした後にキューに突っ込んでいるのですが、kube-state-metricsではキューに突っ込むのではなく、メトリクスを格納するMetricsStoreというものを実装していて、そこにメトリクスを放り込むという実装になっています。

これが実際のListとWatchの実装になるのですが、この中でどのシャードで処理するかの判定を行っています。この赤い部分ですね。
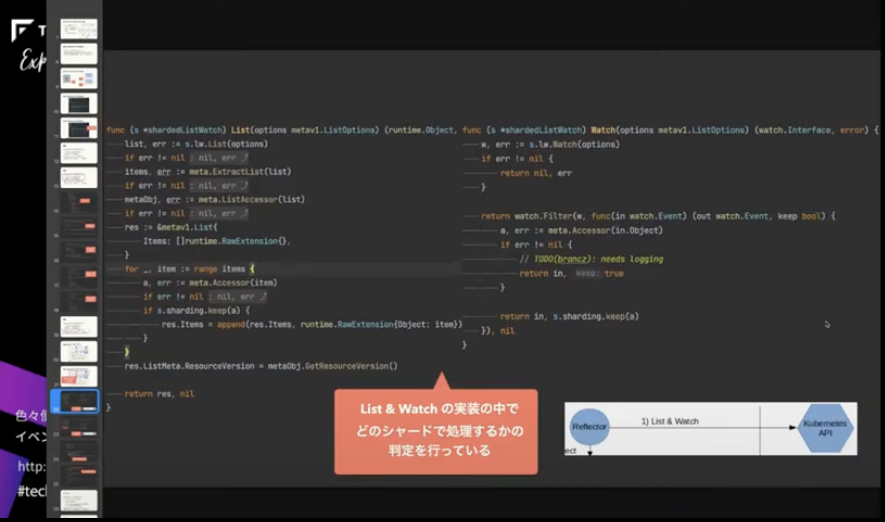
シャーディングの keep() というメソッドがあるのですが、この実装を見ていくとオブジェクトのUIDを取ってきて、それをConsistent Hashingして、処理するシャードを決定して自シャードと一致する場合のみ処理を行っています。


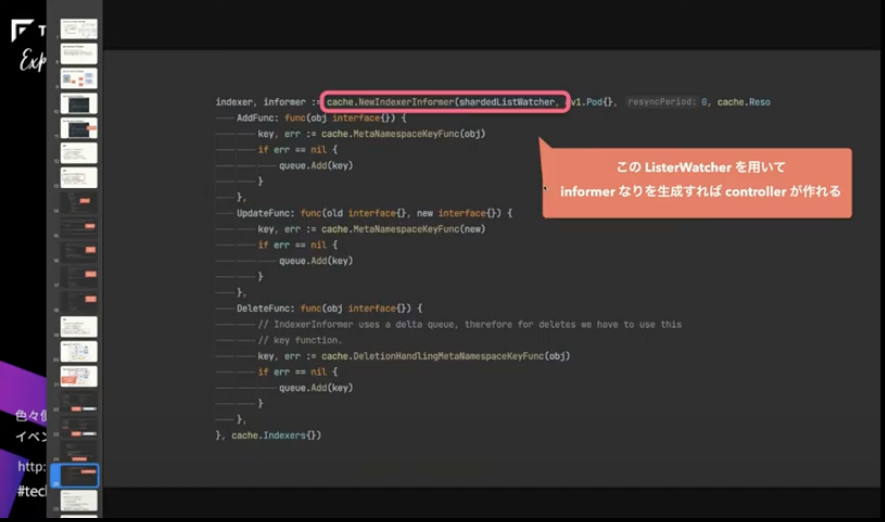
このListerWatcherを使ってInformerなどを作ればcontrollerが作れるようになっています。
この手法にもデメリットが存在していて、大きく分けて2つあります。
まず最初は、StatefulSetを用いているので、そのロールアウトに起因するデメリットはあります。StatefulSetは1台ずつロールアウトされるため、何かあったときのアップデートが非常に遅いです。さらに、Podの削除が先に行われてから、再作成されるという動きをするので、Podが死んだタイミングでPrometheusのスクレイプが発生すると、メトリクスの欠損につながる可能性があります。
もう1個ですが、ListとWatchの部分がシャーディングできていないため、基本的にはAPIサーバに問い合わせて、全オブジェクトを取得し、精査する分のリソースが必要になります。

その代わり、メトリクス部分の格納やシャーディングがしっかりされているので、その分、メモリなどの使用率が通常より低くなるといった効果が期待できます。
まとめ
まとめです。今回はcontrollerのシャーディングに使えそうなkube-state-metricsのシャーディングを紹介しました。
特徴は主に2つあります。
- StatefulSetの特性を上手く使っている
- オブジェクトのUIDでConsistent Hashingしている

最後に宣伝なのですが、Z LabではYahoo!Japan向けにプラットフォームを作りたいエンジニアを絶賛募集中です。KubernetesのControllerなどもバリバリ書いていくので、興味のある方は応募していただけると嬉しいです。

ご清聴いただき、ありがとうございました。