本セッションの登壇者
セッション動画
では、「Jamstackとそのコツ」というテーマで発表させてもらいます。
まずはじめに、簡単な自己紹介をさせてください。株式会社ピクセルグリッドで、Jamstackエンジニアとして働いているNakano Yutoと申します。TwitterをこのIDでやっていたり、Codegridにいろいろ記事を書いていたりするので、できればそちらも見ていただけると嬉しいです。

ではさっそく本題ですが、
- Jamstackとはどのようなアーキテクチャなのか
- 実務でやってみて感じたコツ
の話を今日はしたいと思っています。

Jamstackとは
まずはじめに「Jamstackとは?」についてです。この英文は、jamstack.orgというJamstackの公式の「What is Jamstack?」からの抜粋なのですが、和訳すると、Jamstackとは「Webサイトをデータやビジネスロジックから切り離し、パフォーマンス、スケーラビリティ、柔軟性、保守性を高めるアーキテクチャ」となっています。

とはいえ、これだけでは抽象的でよくわからないので、これまでのWebアーキテクチャと、Jamstackアーキテクチャを比較しながら見ていきたいと思います。
まずはじめに、JamstackではなくレガシーなWebアーキテクチャはこのような図になります。
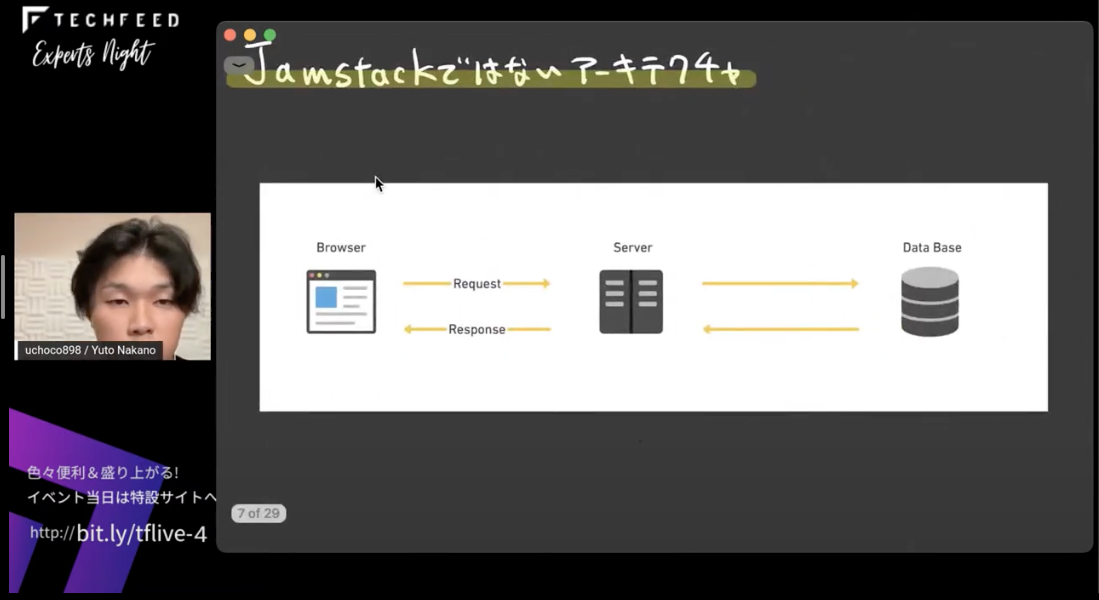
ブラウザからWebサーバにアクセスがあり、Webサーバが適宜データベースにアクセスし、そこで処理が行われて、その結果をブラウザに返すという仕組みです。これには次のような課題があります。

アクセスが増加すると、その分サーバに負荷がかかってレスポンスに時間がかかるようになってしまったり、表示する速度が遅くなったり…という問題が挙げられます。
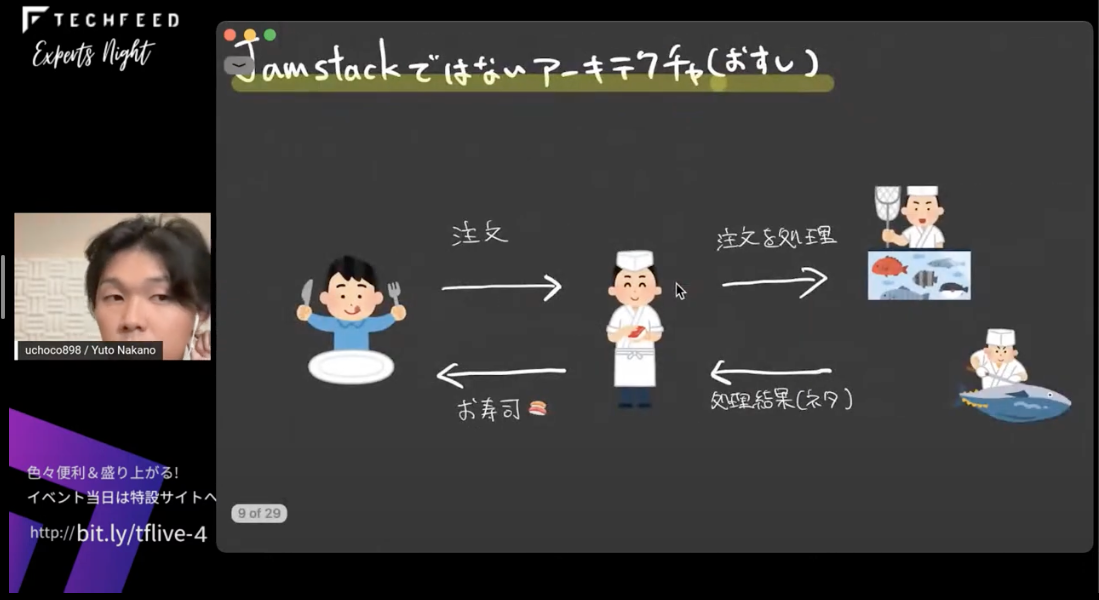
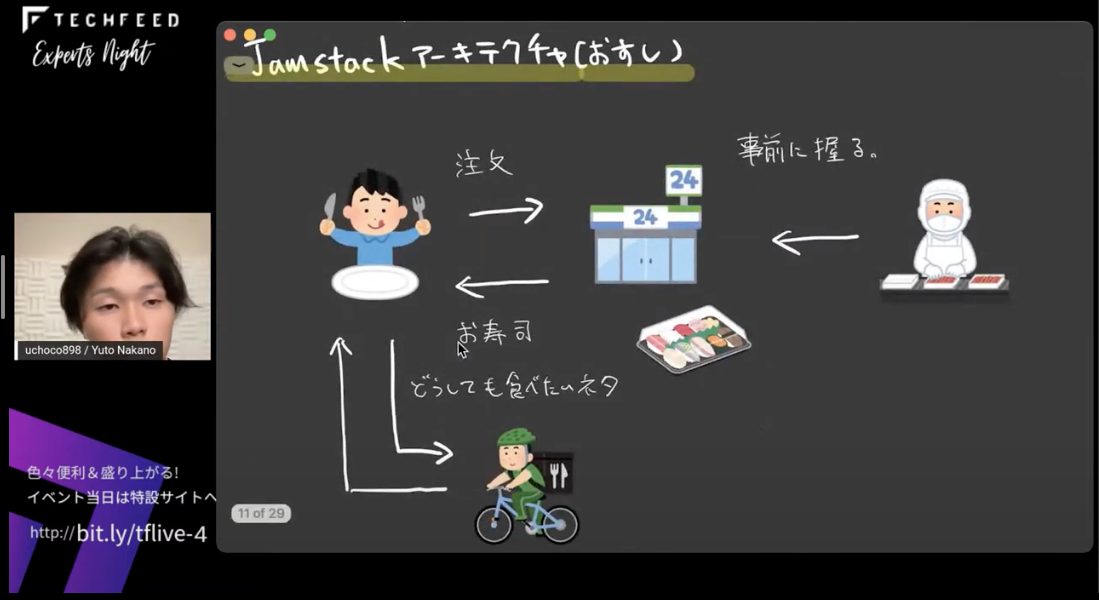
これを直感的に理解できるようにお寿司を例に説明すると、次のようになります。
(お客さんが)お寿司を注文すると、注文を受けた板前さんは、生簀に魚を取りに行ったり、魚を捌いたりしてネタを用意して、結果としてお寿司を返すというような感じです。この構成であれば、大量の注文が来たときにとても忙しくなってしまって…というのが実感できるかと思います。
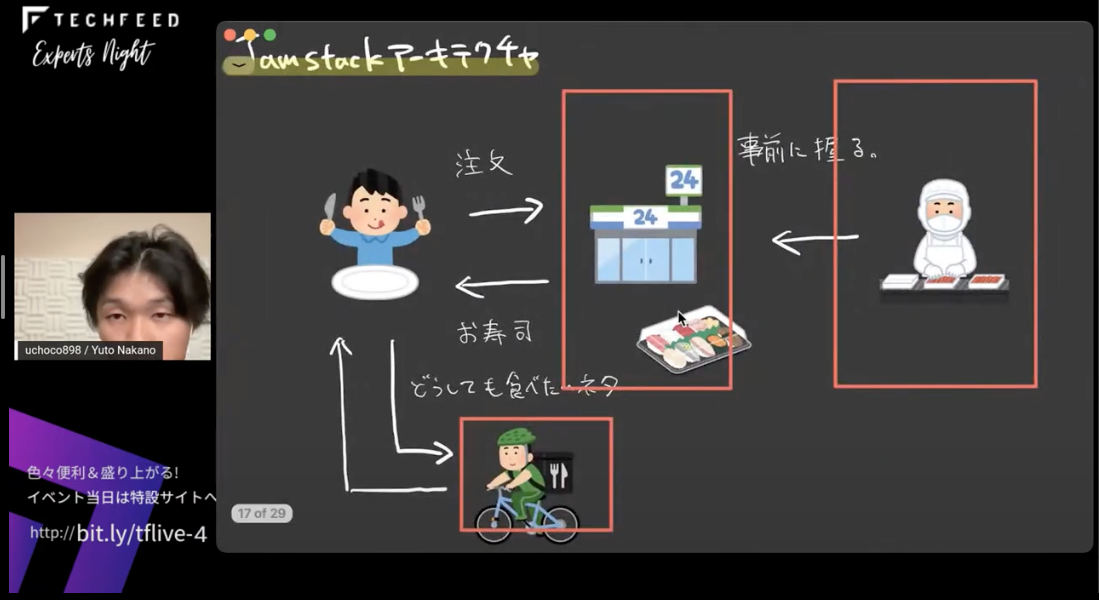
これに対してJamstackアーキテクチャはどういうものかというと、このような図になります。
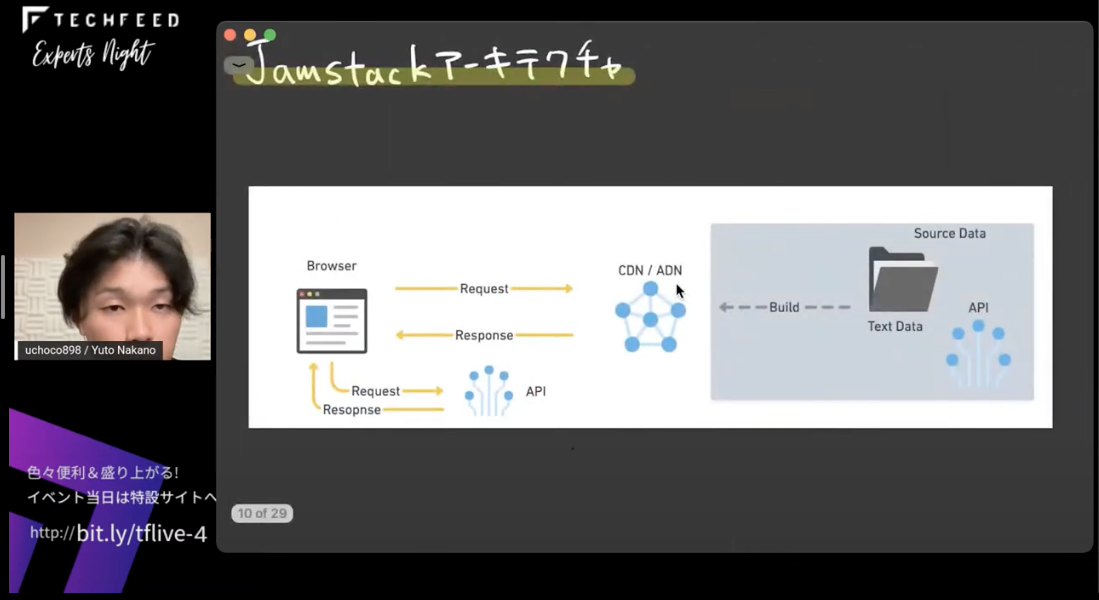
ブラウザがCDNやADNといった配信プラットフォームにリクエストを投げて、そこからレスポンスが返ってくるという形です。そのCDNやADNには、テキストデータやAPIをもとにビルドしたものが配信されていて、どうしても動的に取得しなければならないデータなどはクライアントサイドでAPIを通じて取得している、という構成です。
これもお寿司に例えると、コンビニ(CDN/ADN)にパックされたお寿司(ビルド済みのデータ)を買いに行くようなものです。そのお寿司は、工場という場所で握られていて、それがコンビニに配送されているという感じですね。それとは別にどうしても食べたいお寿司やネタ(どうしても動的に取得したいデータ)がある場合は、お客さんが別にデリバリーしてもらう(クライアントサイドでAPIで取得)というような構成です。
Jamstackは何がいいのか - 「事前レンダリング」と「分離」という2つの原則
ここまでがJamstackの構成で、これのどこがいいのかという話なんですが、注目してほしい点は2つあって、ひとつはこのスライドの赤い枠の部分です。
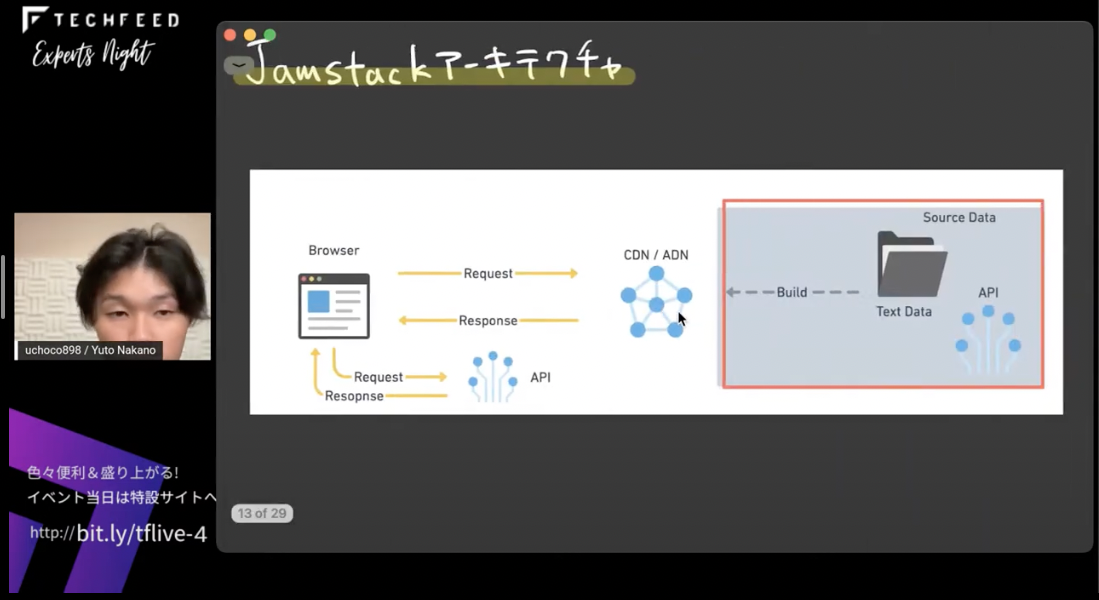
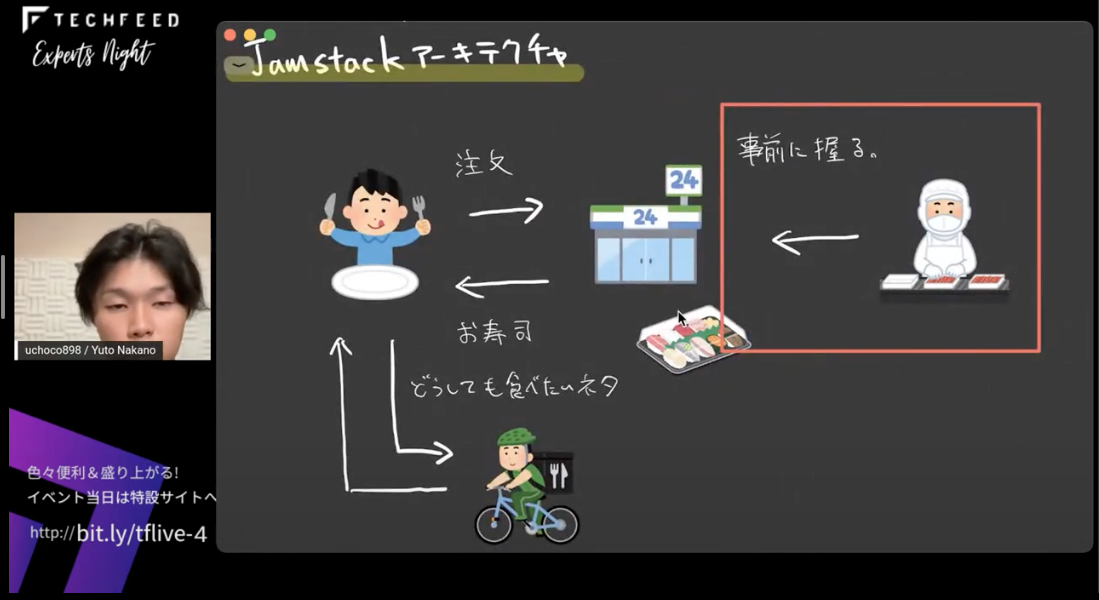
これは、CDNやADNプロバイダにデータソースからビルドしたものを配信している部分ですね。この”ビルド”が何をしているかというと、事前にHTMLを生成しています。これにより、CDN/ADNで配信できるようになってスケーラブルになったり、CDNエッジに乗ることでレスポンスも向上するといったことが期待できるようになります。

このビルド時にHTMLを生成してしまうということをJamstackでは原則のひとつとしていて、「Pre-rendering(事前レンダリング)」と呼んでいます。
お寿司に例えると、事前に握る(事前レンダリング)ことによって、たくさん注文があった際も板前さんが忙しくなることなく、お寿司が食べたい人は最寄りのコンビニで買えるようになります。
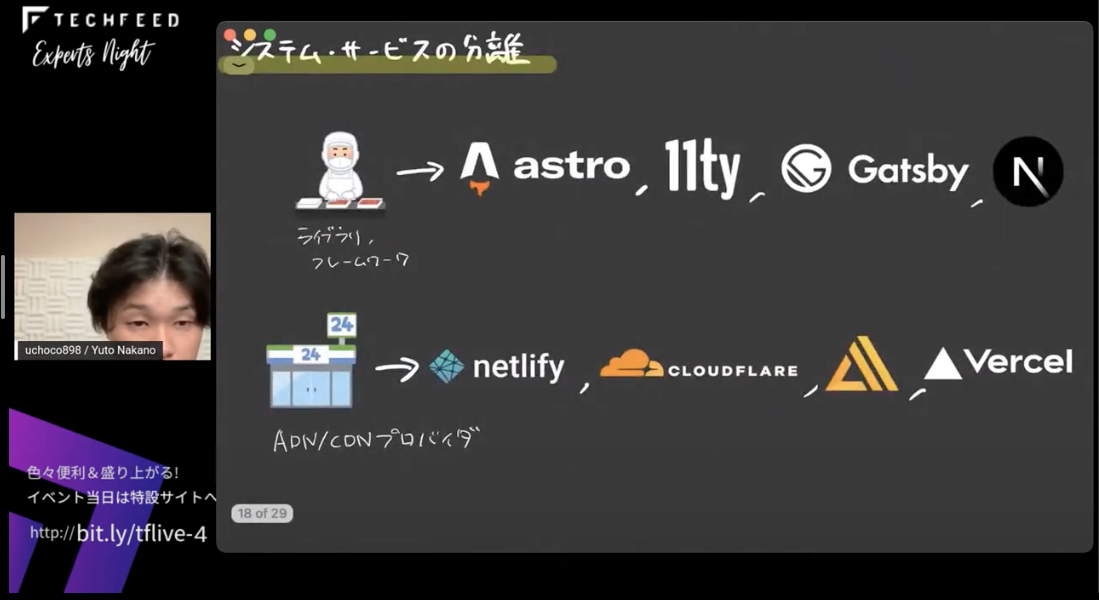
次に注目してほしいのが、この画像の部分 - CDN/ADNプロパイダ、ソースをビルドする部分、クライアントから取得する際に使うAPI部分 - これらはお互いに依存せずに自立しているということです。
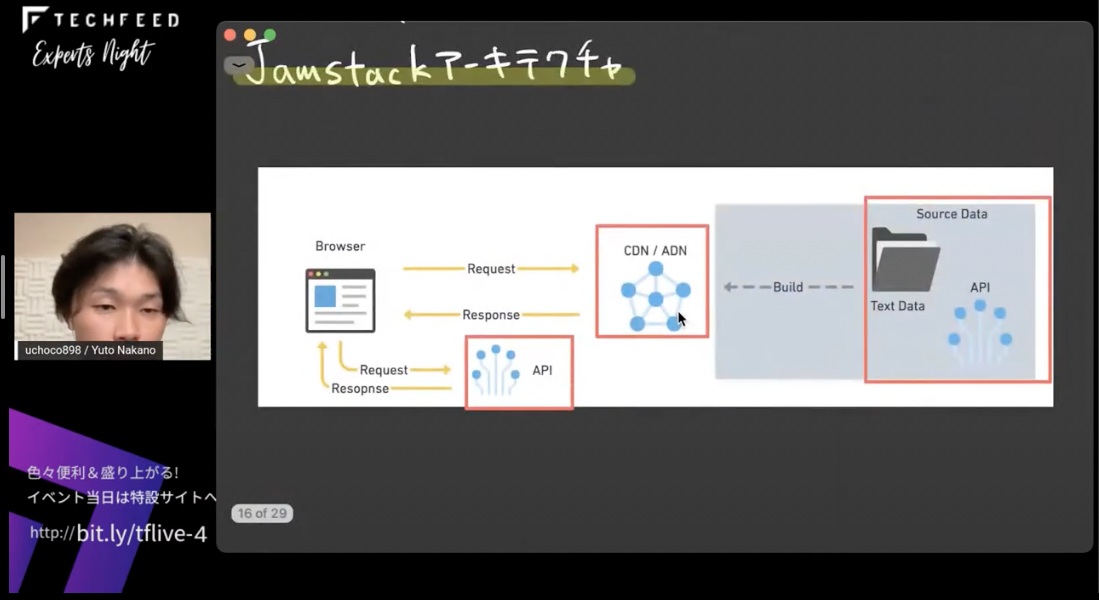
たとえばCDNプロパイダを変更することになっても、ソースをビルドしている部分には影響がないですし、逆にデータベース部分を変更してもCDNプロパイダには影響がないというような構成です。
これをお寿司で言い換えると、工場が変わってもコンビニで売れるということは変わらないし、逆にこのコンビニでなくても、ローソンやセブンイレブンで販売しても工場には影響がないということになります。要は、事前にお寿司を握っている部分はライブラリやフレームワークのことを示していて、そこに変更があっても、CDNやADNには変更がないのです。コンビニ部分はnetlifyやCloudflareやVercelであったり、AWS Amplifyという部分を示しているんですが、これらを変更しても、ビルド部分には影響がないです。
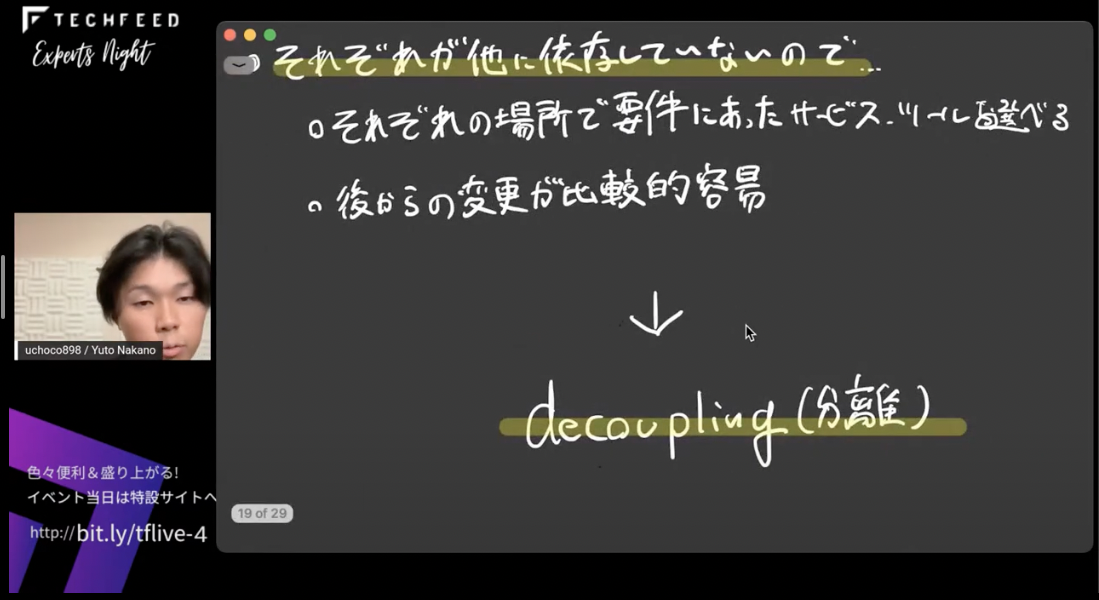
これによって、それぞれの場所で要件にあったサービスが選べたり、これらはそれぞれが取り替え可能なものなので、変更も比較的容易にすることができます。
これを、Jamstackの原則の2つ目の「decoupling(分離)」と呼んでいます。
以上が、Jamstackとはどういったアーキテクチャなのかという説明でした。
最後に軽くまとめると、Jamstackの原則には、
- Pre-rendering(事前レンダリング)
- decoupling(分離)
という2つがあります。

それぞれどのような利点があるかというと、まずPre-renderingは、CDN/やADNによって配信されることでスケーラブルになり、レスポンスも表示速度の向上が期待できます。基本的には静的なサイトを配信するものなので、セキュリティ的にも攻撃する余地が少なくなってくるという利点もあります。
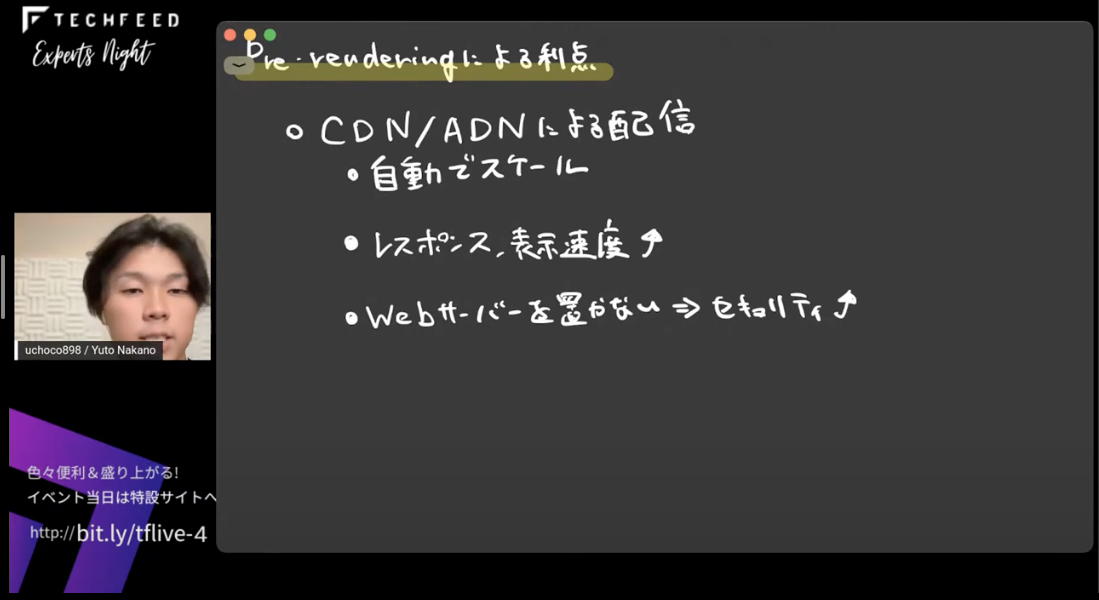
そしてもうひとつのdecouplingですが、要件にあったツールやサービスを選択できることや、変更も比較的容易にできることなどが利点として挙げられます。

Jamstackを実際に動かすコツ
以上が、Jamstackはどんなアーキテクチャなのかという話だったのですが、次に、実際にJamstackを動かすためのコツを紹介したいと思います。
そのコツとは「ビルド時間に気を付ける」ことです。Jamstackでは、ページごとにfetch()する処理を書いてビルド時に何回も走るようになっていたり、取得したデータをフロントで加工する処理がたくさん入っていたりすると、ビルド時間が長くなってしまいます。ビルド時間が長くなるのは、DX(デベロッパーエクスペリエンス)的にも良くないですし、デプロイにかかる時間はできるだけ短くしたいと思います。
これらの対策として、ページごとにfetch()するのではなく、最初にまとめてfetch()するようにコードを変えたり、あらかじめ加工したデータを用意しておくという対策を取ると良いと思っています。

ビルド時間を削減するその他のアプローチとして、CDN/ADNプロバイダや、フレームワーク側などツール側の機能としてもあって、少し紹介すると、たとえばGatsbyのIncremental Buildsだったり、NetlifyのDPRと呼ばれる機能がそれに当たります。これらはどちらもビルド時にすべてをビルドするのではなくて、たとえばGatsbyのIncremental Buildであれば、差分だけビルドしたり、初回アクセス時にビルドしたりするという機能です。
これらを使うのもひとつの手段ではあるのですが、この場合、プラットフォームに依存してしまい、CDNやADNにロックインすることにつながってしまうので、基本的にはあまりお勧めできない選択肢かなと思っています。

なので、Jamstackで作る際は、まずこのような機能を使う前に、ビルド時間をできるだけ短縮できる手立てがないかを考えるのが良いと思います。
以上です。ご清聴ありがとうございました。