連載「Technology Company Internals」では、テックカンパニーの内側で働くエンジニアに、技術に精通したエキスパートが対面で話を聞き、テックカンパニーとは何か?を探るだけでなく、テックカンパニーを目指す企業の指針となることを目指します。
ゲーム・アニメ事業、メタバース事業、コマース事業、DX事業、マンガ事業、投資・インキュベーション事業などを展開するグリーには、それぞれの専門分野に長けた凄腕エキスパートが数多く在籍しています。今回はそんな超スペシャリストの中から、グリーの大規模インフラを支えるモニタリングを担当する2人のエキスパート - インフラチーム マネージャー 黒木誠士氏とモニタリングユニット リードエンジニア 反田光洋氏に、大規模ゲームインフラにおけるモニタリングの重要性、そしてモニタリングエンジニアという仕事の醍醐味について、TechFeed CEOの白石俊平がお話を伺いました。
マルチクラウドで数千台のサーバを24/365で監視
--まず、お二人の自己紹介からお願いします。
黒木: 私は事業横断でインフラを支援するチームのマネージャーとして、チームとメンバーのマネジメントや、新規のプロダクトにおけるインフラ導入の計画と実行、あとはAWSやGoogle Cloudなど外部の協力会社との調整業務などを担当しています。さまざまな事業を横断して、技術的な支援を行うチームだと思っていただければ。
反田: 私はグリーにモニタリングの専門ユニットができた初期から所属していて、現在もモニタリングに特化した業務を行っています。モニタリングツールとしてはおもにGrafanaとPrometheusを利用しているのですが、それらを導入したサーバの構築や機能選定なども担当しているほか、Grafana自体の開発にもコミットしていてGitHubでプルリクエストを送ったりもしています。
--グリーはモニタリング専門のユニットチームを設置するほど大規模なインフラ組織ということですが、具体的にはサーバ台数などはどれくらいの規模なのでしょうか。
黒木: (クラウドとオンプレあわせて)トータルで数千台規模、といったところでしょうか。その中でもAWSが一番多くEC2インスタンスは数千台、AWSアカウントも50以上あります。最近はGoogle Cloudの利用も増えてきて、とくにKubernetesを利用する環境はGoogle Cloudが多いですね。あとオンプレミスもまだ1000台くらいはあります。
反田: サーバの台数も重要なんですが、たとえばセールスランキング1位のゲームなどは、アクセス数もユーザ数も膨大になります。加えていくつかのゲームではリアルタイム性が非常に重要で、少しでも遅延が発生するとユーザエクスペリエンスを大きく損ねてしまう。また24時間365日つねにアクセスがあり、その一方で休日や月初にはアクセスが集中し、負荷が高くなりやすい傾向があります。つまり、グリーのインフラはあらゆる変動に耐えうる構成でなければならないんです。

--なるほど。そのあたりが御社におけるモニタリングの重要性と関係しているのでしょうか。
反田: たとえば話題作の公開など、大規模なリリースのときはインフラに負荷がかかることがあらかじめ予測できるので、負荷試験やレビューもある程度日程に余裕をもたせながら、それこそ大量のリクエストを発生させたり、大規模なトラフィックを用意して相応の負荷をかけたりして、「これなら大丈夫なのでは」と思えるところまで入念に行います。でもどんなに事前にテストをしても、リリースしてから発生する問題が出てくる。そんなときにモニタリングの存在が非常に重要になってきます。
黒木: 極論をいうと、モニタリングがなくてもサービスは提供できるんです。でもモニタリングを徹底することで、ボトルネックの特定を迅速に行うことが可能になります。あと、我々は負荷試験の段階でもモニタリングを駆使していて、ゲームのリリース前に可能な限りボトルネックを潰すようにしています。
反田: 新規のゲームをリリースすると、初日にはかなりのリクエストが集中します。なのでリリース直後はかなり余裕をもたせたシステム構成にすることが多いのですが、しばらく経つとアクセスも落ち着いてくるので、サーバの台数を減らしたりスペックを下げたりする必要が出てきます。
このとき、モニタリングのデータがあれば、費用最適化の観点からも「どのサーバを何台くらい減らすべき」と自信を持って言うことができる。先ほど、グリーのインフラの規模について触れましたが、(新規タイトルリリースや大型アップデートなど)イベントの前後ではサーバの負荷を適切に管理する作業が欠かせません。また、効率の悪いコードが紛れ込んでいることで、無駄な負荷がかかっていることもある。そうしたボトルネックを日々のモニタリングデータで分析することで、振れ幅が大きい環境でもデータに裏付けられた的確なシステム構成を提案することができます。

モニタリングをエンジニアリングしてOSSにコミットする
--モニタリングがリリースの前後で大きな役割を果たしていることがよくわかります。その重要なモニタリングという仕事に、何名くらいの方が関わっていて、具体的にどんな業務を行っているんでしょうか。
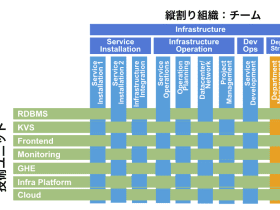
黒木: インフラ部内には組織上のチームとは別に、個々の専門知識に特化したメンバーから成る”ユニット”をいくつか作っていて、モニタリングに関してもモニタリングユニットを設けています。メンバーの数は十数名くらいですね。AWS、Google Cloud、それにオンプレミスでそれぞれ詳しい担当者がいて、いちばんサーバ台数が多いAWSに関しては反田がおもに担当しています。メインの業務としてはモニタリングのためのツールを作り、それを提供/メンテしていくことですね。
反田: たとえば稼働中のMySQLになにかトラブルが発生した場合、その問題を分析するのはMySQL専門のユニットの仕事で、我々モニタリングユニットはそのためのツールを提供します。先ほどの話にもあったように、グリーのAWSアカウントはゲームプロダクトごとに50くらいあるんですが、それらのサーバを起動して、きちんとツールが動くか確認する、また、新しいサービスを使うときに必要なツールを揃えていくのも我々の仕事です。最近だとGoogle Cloudの分散データベース 「Cloud Spanner」の利用を開始したのですが、そのモニタリングに必要なツールも作成しました。
--ツールを「作る」というところがグリーならではの凄さというか、技術的な強みに聞こえます。
反田: 最初にもお話したように、モニタリングの基本ツールとしてはオープンソースのPrometheus(各サーバからメトリクスデータを収集する)とGrafana(収集したデータをダッシュボードで表示する)を使っています。でもそれだけじゃどうしても足りない。モニタリングシステムを構築するとき、グリーの場合は超大規模なゲームや長期間に渡るゲームなどが展開されているので、アラートの振り分けを工夫したり、1年前のデータを参照する必要が出てきます。こういった独自の要件が多くなってくると、どうしても既存のツールだけだと厳しいですね。
たとえば、AWS上のモニタリングシステムで動いているアラート通知の「Yusura」はまさにグリーの要件に合わせるために作成したツールです。
あと、Grafanaを使い始めた当初はPrometheusのデータを表示できなかったので、Prometheus標準のビジュアライズツールを使ったりしていたのですが、機能は足りないし、使いにくい。「GrafanaとPrometheusが一緒に使えたら便利なはず」と思って、自分でコードを書いてGrafanaの開発チームに送ったりしました。
ほかにも 「Amazon CloudWatch」のメトリクスをGrafanaで表示できるようにしたこともあります。こういうふうに、既存のサービスや提供されたツールを、自社のニーズにあわせて作り変え、更にはOSSにコミットすることもできる。こういうスキルは我々の強みであり、楽しいところでもありますね。
エンジニアが圧倒的に成長する環境
--ということは、現在は世界中のPrometheus/Grafanaユーザが反田さんたちが修正したコードを使っているわけですね。それはすごい…!
黒木: そうですね、仕事で書いたコードが、世界中のエンジニアに使われるというのは非常に嬉しい経験です。モニタリングユニットも含め、グリーのインフラ部門のエンジニアはめちゃくちゃ問題解決能力が高いんです。それぞれの専門に対して深くコミットしているというか、たとえばMySQLのユニットならMySQLのソースコードを深く読み込んでいるエンジニアが揃っている。新しい情報のキャッチアップもすごく速くて、クラウドベンダの技術担当者の方から驚かれることもあります。
高い専門スキルをもったエンジニアが、大規模な本番環境の現場で経験を積み重ねているわけですから、エンジニアとしての力量を上げやすいのだと思います。
反田: 中途のエンジニアもそうですが、新卒で入ってきても1年くらいですごく成長しますね。私ももう追い抜かれてしまいそうで、ちょっと心配しています(笑)
--スキルを向上させたいインフラエンジニアにとっては、まさに理想の環境ですね。ちなみに、モニタリングという仕事をしていて、いつも気をつけていることはなにかありますか?
反田: メトリクスの「意味を考える」ということはすごく意識しています。OSレベル、というかカーネルレベルで今何が起こっているのか、どういう計算がなされていて何が実行されているのか、そしてそれにどんな意味があるのか - これらをつねに考えていないとメトリクスを適切に活用することが難しくなります。
また、カーネルもつねに変化していくものなので、バージョンが変わればロードアベレージやディスクI/Oの負荷を計測する方法も変わってきます。このカーネルで動いているこのシステムのこのメトリクスは何を意味しているのか - メトリクスの意味を正しく理解することはすごく難しいですが、つねに頭に置いて作業をするようにしています。
カーネルが提供するメトリクスの、更に「意味」まで考える…すごいレベルです。
エンジニアドリブンな企業で働きたいインフラエンジニア、大募集!
--最後になりますが、お二人からそれぞれ、エンジニアに向けてメッセージをお願いできますか。
反田: グリーにはたくさんのエンジニアが所属していますが、自分たちで決められる裁量が大きい組織です。またオープンソースの開発をしている/したい人にも向いています。自分で決めて、動いて、どんどん改善していきたいと思っているエンジニアにぜひ来てもらいたいですね。
黒木: インフラ部門も含めて、グリーという会社はエンジニアにとってとても自由で風通しが良い環境が揃っていると思います。エンジニアドリブンなので、さまざまなチャレンジをしやすいところも特徴ですね。技術的なチャレンジを望んでいる方や、自分の得意な技術を追求していきたいエンジニアにとって働きやすい場所なので、そういう方とこれから一緒に働いていくことができれば嬉しいです。