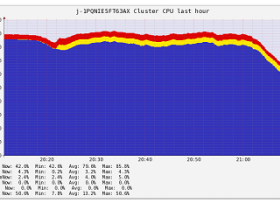
Best practices for successfully managing memory for Apache Spark applications on Amazon EMR
DRANK
In the world of big data, a common use case is performing extract, transform (ET) and data analytics on huge amounts of data from a variety of data sources. Often, you then analyze the data to get insights. One of the most popular cloud-based solutions to process such vast amounts of data is Amazon EMR. […]