概要
3GBを越えるcsvファイルの前処理のトレーニング備忘録
3GBを越えるcsvファイルは、Excelで開くことができない。
これをデータサイエンティストが分析に使えるようデータを整理し、300行のcsvファイルとして出力する。
前提知識
・SELECTやテーブルといったSQLの基礎知識が僅かにある
・MAMPなどでSQLにログインができる
使用する技術
- データベースの作成
- テーブルの作成
- csvファイルを読み込み
- 欠損値のあるレコード(行)の削除
- 文字列に存在する邪魔な文字を指定して削除
- varchar型からfloat型へ変換
- varchar型からDate型へ変換 ('04/01/1998'という順序で記録されている文字列を、'1998-04-01' の順に変えて変換)
- データを並べ替えてcsvファイルに出力
使用するcsvファイル
kaggleのこちらからiowa-liquor-sales.csvをダウンロード
実践内容
ファイルのカラム(列)名の取得
SQLでは、テーブルのカラムを先に指定する必要がある。
今回はRを用いてカラム名と型を取得。
## R
# check colmn name
# ファイルのカラム名を調べる
library(tidyverse)
Iowa <- read_csv("Iowa_Liquor_Sales.csv")
str(Iowa)
出力結果末尾
- attr(*, "spec")=
.. cols(
.. Invoice/Item Number = col_character(),
.. Date = col_character(),
.. Store Number = col_double(),
.. Store Name = col_character(),
.. Address = col_character(),
.. City = col_character(),
.. Zip Code = col_character(),
.. Store Location = col_character(),
.. County Number = col_character(),
.. County = col_character(),
.. Category = col_double(),
.. Category Name = col_character(),
.. Vendor Number = col_double(),
.. Vendor Name = col_character(),
.. Item Number = col_double(),
.. Item Description = col_character(),
.. Pack = col_double(),
.. Bottle Volume (ml) = col_double(),
.. State Bottle Cost = col_character(),
.. State Bottle Retail = col_character(),
.. Bottles Sold = col_double(),
.. Sale (Dollars) = col_character(),
.. Volume Sold (Liters) = col_double(),
.. Volume Sold (Gallons) = col_double()
.. )
ほとんどのカラムが文字列だと分かる。
(DateやState Bottle Costなども)
SQLへ移動
コマンドプロンプトを起動してSQLへ。
## cmd
# Mysqlのあるディレクトリに移動
cd C:\MAMP\bin\mysql\bin
# Mysqlにログイン
mysql -u root -proot
1. データベースの作成
trainという名のデータベースの作成
# trainという名のデータベースを作成
CREATE DATABASE train;
# 使用するデータベース'train'の指定
USE train;
# 使用するテーブル'iowa_liquor_2'が既にある場合は削除(無ければ以下の命令は無視)
DROP TABLE iowa_liquor_2
2. テーブルの作成
先程Rで判明したカラム名と型を用いて、テーブル'iowa_liquor_2'を作成する
欠損値を正確に処理するために一旦すべてのデータはvarchar型で定義する。
# 使用するテーブル'iowa_liquor_2'を作成
CREATE TABLE iowa_liquor_2 (
InvoiceItemNumber varchar(255),
Date varchar(20),
StoreNumber varchar(255),
StoreName varchar(255),
Address varchar(255),
City varchar(255),
ZipCode varchar(255),
StoreLocation varchar(255),
CountyNumber varchar(255),
County varchar(255),
Category varchar(20),
CategoryName varchar(255),
VendorNumber varchar(255),
VendorName varchar(255),
ItemNumber varchar(255),
ItemDescription varchar(255),
Pack varchar(255),
BottleVolume varchar(255),
StateBottleCost varchar(255),
StateBottleRetail varchar(255),
BottlesSold varchar(255),
Sale varchar(255),
VolumeSoldLiters varchar(255),
VolumeSoldGallons varchar(255)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
3. csvファイルをインポート
テーブル'iowa_liquor_2'にインポートする
INFILEの後ろに先程Kaggleでダウンロードした'Iowa_Liquor_Sales.csv'が保存されている場所を指定
# 作成したテーブル'iowa_liquor_2'に'Iowa_Liquor_Sales.csv'をインポート
LOAD DATA LOCAL INFILE 'C:/~~~~~~~~~~~~~~/Iowa_Liquor_Sales.csv'
into table iowa_liquor_2
fields terminated BY ','
OPTIONALLY ENCLOSED BY '"'
IGNORE 1 LINES;
出力結果
Query OK, 12591077 rows affected, 65535 warnings (4 min 8.84 sec)
Records: 12591077 Deleted: 0 Skipped: 0 Warnings: 89541
読み込みに4分以上掛かかった。
データ数は12591077と判明
上手くインポートできたか確認
# テーブルの列を確認
DESC iowa_liquor_2;
# テーブルの1行目を確認
SELECT *
FROM iowa_liquor_2
LIMIT 1;
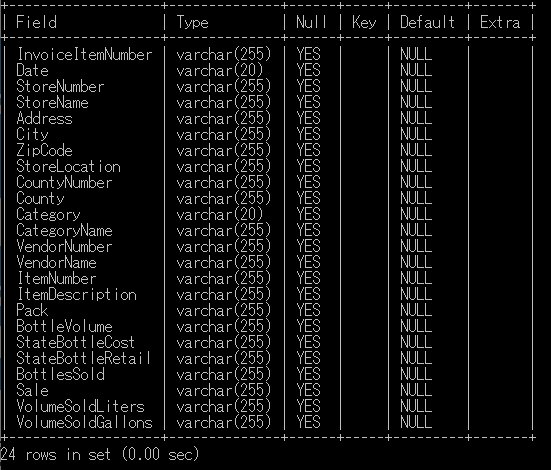
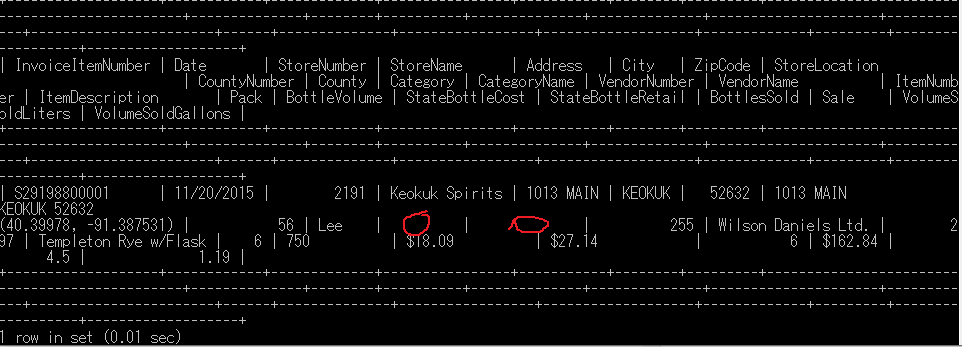
インポートはできたが、欠損値を発見。
4. 欠損値があるレコード(列)を削除してデータを整える。
# 欠損値があるレコード(行)を削除
DELETE
FROM iowa_liquor_2
WHERE
InvoiceItemNumber = ''
OR Date = ''
OR StoreNumber = ''
OR StoreName = ''
OR Address = ''
OR City = ''
OR ZipCode = ''
OR StoreLocation = ''
OR CountyNumber = ''
OR County = ''
OR Category = ''
OR CategoryName = ''
OR VendorNumber = ''
OR VendorName = ''
OR ItemNumber = ''
OR ItemDescription = ''
OR Pack = ''
OR BottleVolume = ''
OR StateBottleCost = ''
OR StateBottleRetail = ''
OR BottlesSold = ''
OR Sale = ''
OR VolumeSoldLiters = ''
OR VolumeSoldGallons = ''
;
5~7. varchara型のカラムを別の型に変換
数字で表されているものは文字でなく数字として分析で使用したいので、数字型に変換する。
下記の8つのカラムのデータの型を変更する
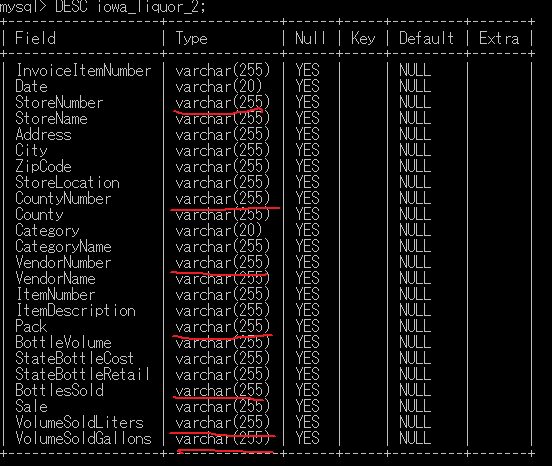
# データの型を変更できるものは変更する
# カラムStoreNumber, CountyNumber, VendorNumber, ItemNumber, Pack, BottlesSoldをINT型に変更
ALTER TABLE
iowa_liquor_2
MODIFY StoreNumber INT
, MODIFY CountyNumber INT
, MODIFY VendorNumber INT
, MODIFY ItemNumber INT
, MODIFY Pack INT
, MODIFY BottlesSold INT
;
# カラムVolumeSoldLiters float, VolumeSoldGallonsをfloat型に変更
ALTER TABLE
iowa_liquor_2
MODIFY VolumeSoldLiters FLOAT
, MODIFY VolumeSoldGallons FLOAT
;
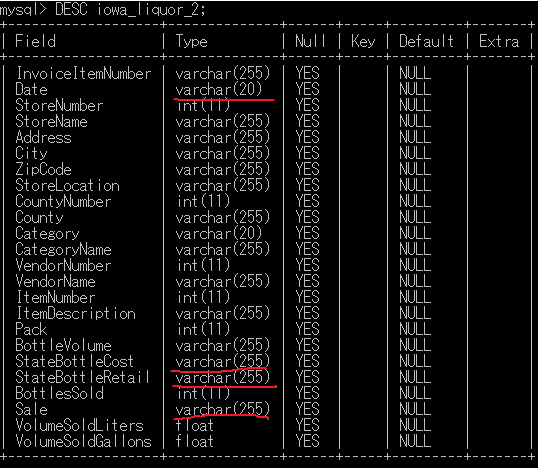
# テーブルの列の型を確認
DESC iowa_liquor_2;
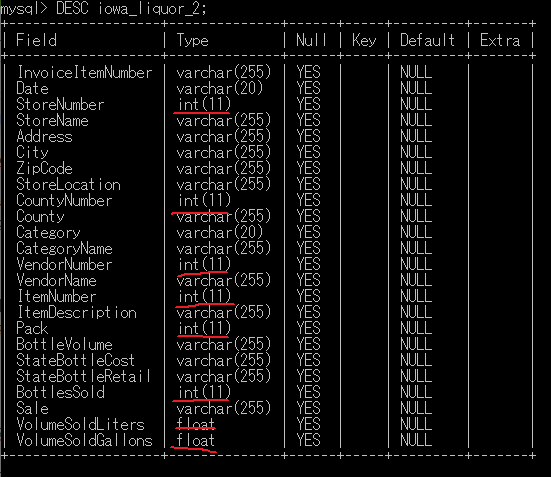
上記7つのカラムのデータの型を変更できた。
単純な変換ができない変換
カラム(列)'StateBottleCost','StateBottleRetail','Sale'は文字'$'が数字の前に存在しているため、変換ができない。
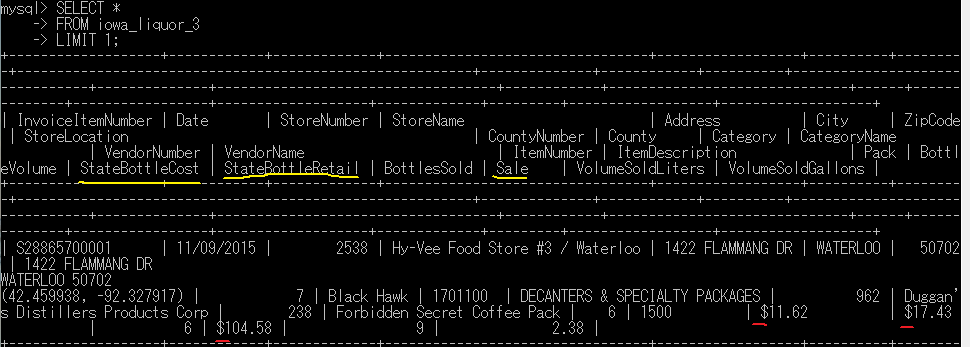
また、日付を表すであろうカラムDateも文字列として扱われているので変換したい。
以下の4カラムは一工夫施してから型変換が行うことができる。
5. 文字列に存在する邪魔な文字を指定して削除
値段のカラムは数字として扱いたいので、文字'$'を除去し、float型へ変換できるようにする。
# カラム(列)'StateBottleCost','StateBottleRetail','Sale'の文字'$'を除去
UPDATE `iowa_liquor_2` SET StateBottleCost=REPLACE(StateBottleCost, "$", "");
# remove $ StateBottleRetail & Sale
UPDATE `iowa_liquor_2` SET StateBottleRetail=REPLACE(StateBottleRetail, "$", "");
UPDATE `iowa_liquor_2` SET Sale=REPLACE(Sale, "$", "");
# テーブルの1行目を確認
SELECT *
FROM iowa_liquor_2
LIMIT 1;
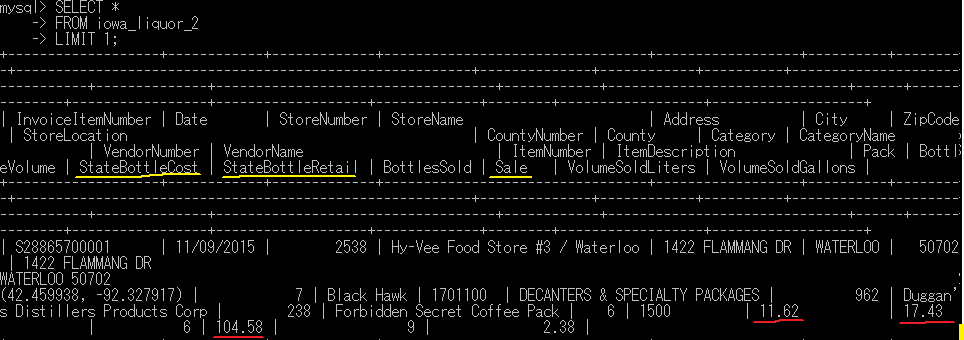
無事'$'を全て消せたことを確認。
6. varchar型からFLOAT型へ変換
'$'を除去した3列の型をvrchar型からFLOAT型に変更し、数値として扱えるようにする。
# 先程、文字'$'を除去した3列の型をvrchar型からFLOAT型に変更
/* 列の型を変える */
ALTER TABLE
iowa_liquor_2
MODIFY StateBottleCost FLOAT
, MODIFY StateBottleRetail FLOAT
, MODIFY Sale FLOAT
;
# テーブルの列の型を確認
DESC iowa_liquor_2;
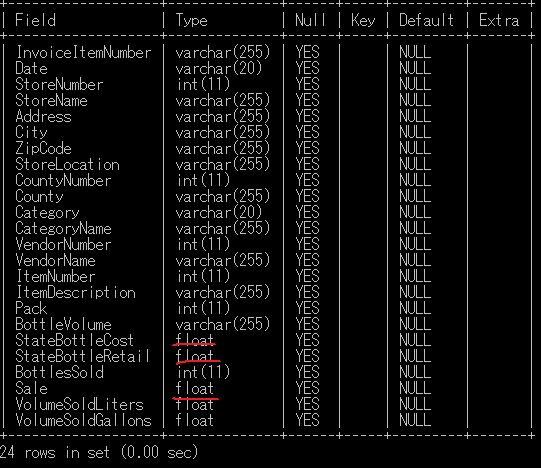
3列の型をFLOAT型に変更できた。
7. DATA型に変換
文字として扱われているカラム'Date'を、日付として扱えるようにDATE型に変換。
'MM/DD/YYYY'という順序で記録されているため、'YYYY-MM-DD' に変える。
# DATA型に変換できるように'MM/DD/YYYY'から'YYYY-MM-DD' に変える
UPDATE `iowa_liquor_2` SET Date=STR_TO_DATE(Date,'%m/%d/%Y');
# テーブルの1行目を確認
SELECT *
FROM iowa_liquor_2
LIMIT 1;
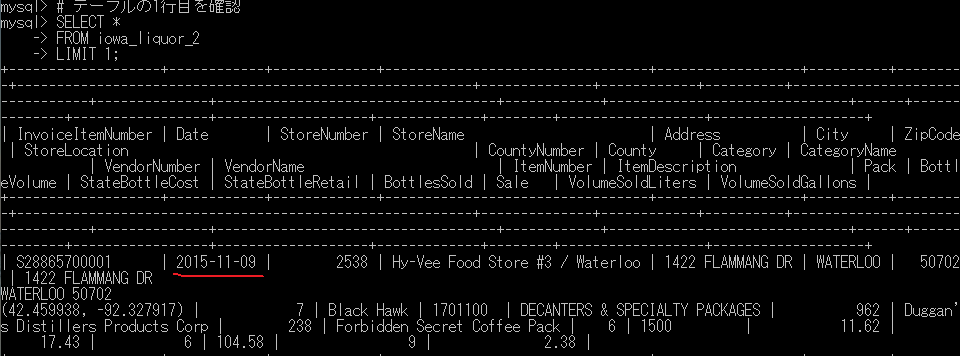
Dateが'YYYY-MM-DD'の順番に変更された。
# 列'Date'をvrchar型からDATA型に変更
ALTER TABLE iowa_liquor_2 MODIFY DATE DATE;
# テーブルの列の型を確認
DESC iowa_liquor_2;
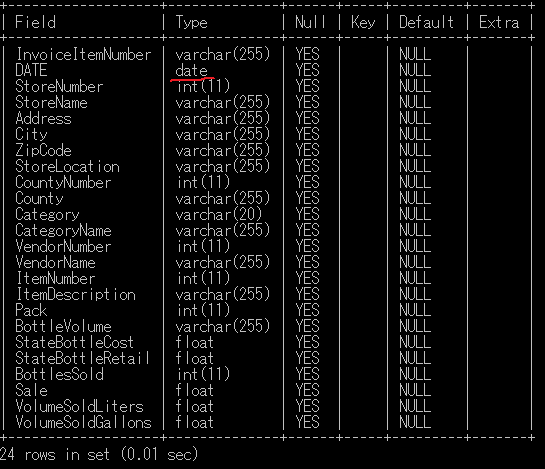
カラムDATEの型がdate型に変更された。
8. csvファイルにエクスポート
StoreName, InvoiceItemNumber, Dateの順に優先して列を昇順に並び替えた最初の300行をcsvファイルへ書き出し
# sort by StoreName, InvoiceItemNumber, Date
/*
StoreName, InvoiceItemNumber, Dateの順に優先して列を昇順に並び替えて、
300行まで取ってきたものをiowa_liquor_2.csvとして書き出し
*/
# 最初のSELECT文で、出力するCSVファイルの列名を支持
(SELECT
'InvoiceItemNumber',
'Date',
'StoreNumber',
'StoreName',
'Address',
'City',
'ZipCode',
'StoreLocation',
'CountyNumber',
'County',
'Category',
'CategoryName',
'VendorNumber',
'VendorName',
'ItemNumber',
'ItemDescription',
'Pack',
'BottleVolume',
'StateBottleCost',
'StateBottleRetail',
'BottlesSold',
'Sale',
'VolumeSoldLiters',
'VolumeSoldGallons'
)
UNION(SELECT *
INTO OUTFILE 'iowa_liquor_2.csv'
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
ESCAPED BY '"'
LINES TERMINATED BY '\r\n'
FROM iowa_liquor_2
ORDER BY StoreName, InvoiceItemNumber, Date
LIMIT 300
);
# C:\MAMP\db\mysql\trainにできる