
こんにちは、ヤフーで社内向けCaaS(Kubernetes)環境を提供している岸本です。
アプリケーションを継続的にリリースするためには、CI/CDは欠かせない物となっており、ヤフーでもCI/CDを用いたデプロイを行っております。
社内ではCI/CDツールとして、ヤフーとVerizon Mediaが共同開発しているScrewdriver.cdを利用し、アプリケーションのビルドやテスト(Continuous Integration/継続的インテグレーション、Continuous Delivery/継続的デリバリー)に限らず、さまざまな環境へのリリース(Continuous Deployment/継続的デプロイ)も行っています。
今回はインフラにおけるCI/CD pipelineのワークフロー構築の遷移や得られた知見についてお話します。
管理するKubernetesクラスタ数が増えても運用コストは抑えたい
ヤフーでは、社内一般向けのCaaS環境としてZCPを提供していますが、一部特殊な要件に対応するため、独立したKubernetes環境も提供しています。
私が所属するチームでは、Kubernetesクラスタのカスタマイズを容易にするため、クラスタの構築はansibleを用い、クラスタへのデプロイはScrewdriver.cdを用いて運用を行っています。プロダクトの成長と需要拡大に合わせて、pipelineを拡張してきましたが、システムを拡張していく過程で、pipelineは次第に巨大化し、運用が複雑化し、運用にかかるコストが肥大化しました。
運用コストを下げつつ品質は維持するために、どのようなCD piplineを構築し改善したか、その時感じた課題と得られた知見などをまじえつつご紹介します。
Kubernetesを構築するjobを分割し、コンポーネントの構築順序をpipelineに反映する
課題
Kubernetesの構築を1つのJobとして行う場合、ジョブが途中で失敗した場合は最初から実行することになり、実行時間が長くなってしまう問題があります。ひと目で失敗した箇所がわかりにくく、調査に掛かる時間コストも軽視できません。
解決方法
そこで、1つのクラスタを構築する手順を最適な大きさのJobに分離し、並行してJobを実行することで、pipeline全体の処理時間を短くしました。Kubernetesクラスタを構成するコンポーネントは多く、依存関係も存在するため、etcd,apiserver,kubeletなどの要素をおおまかに分割し、pipelineに反映していきます。
大きく分けて、etcd,control plane,workerの3つのロールに分離することができ、workerの構築にはcontrol planeが、control planeの構築にはetcdクラスタが依存するため、依存関係をそのままpipelineに反映した形にしました。
また、想定された構成になっているかのテストを行うジョブを最後に追加し、クラスタが正常に構築できているかをシステムで確認できるようにしています。
(クラスタ名はイメージです)
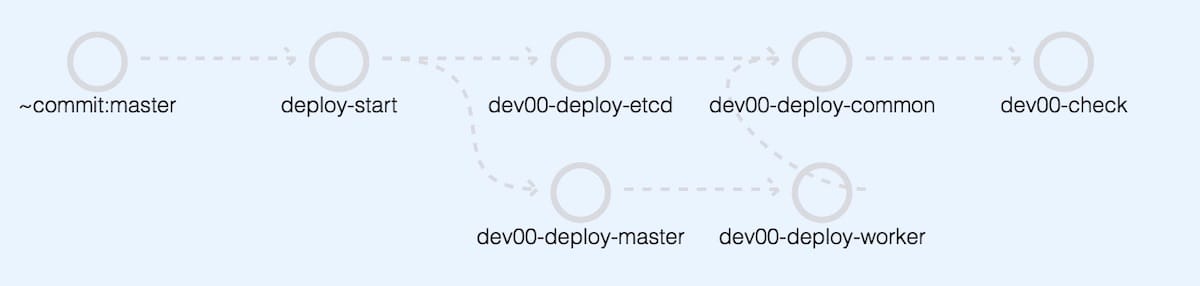
複数のクラスタを1つのpipelineで実行する
ヤフーではサービスが多数存在するため、特殊な要件を持つサービスは1つではありません。また、社内のネットワーク要件にも対応するため複数のKubernetesクラスタを複数管理する必要があります。
前項のpipelineを1つのクラスタセットとし、管理対象のクラスタをpipelineに組み込んでいきます。
「開発環境→検証環境→本番環境」という流れでpipelineを構築していきます。本番環境を最後にすることで、開発環境では発現しなかったバグを検証環境で確認し、バグを本番に反映してしまうことを防ぎます。
また、冗長化の観点から2つのコロケーションにクラスタが存在するため、かなり複雑になってきました。
さらに、リリースするタイミングを運用者がコントロールできるようにgit-flowを採用し、developブランチで開発・バグ修正などを行い、masterブランチにマージされたときにリリースが実行されるように設計しました。
(一回のデプロイで全てのjobがpassするととてもうれしい)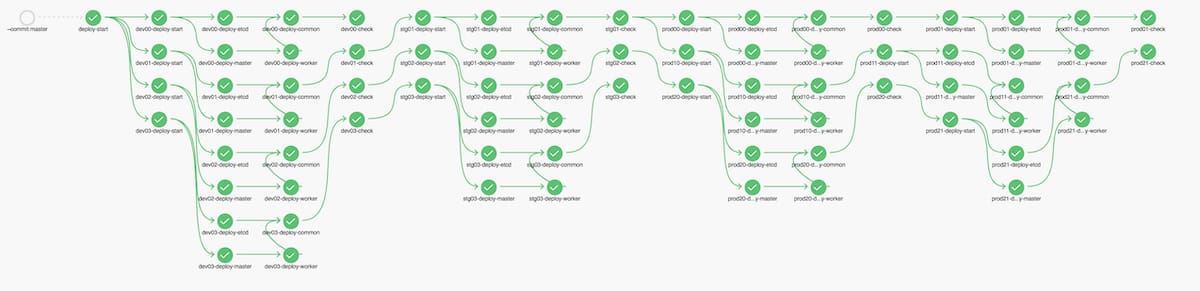
巨大化していくCD pipelineの設定を自動生成する
課題
ジョブが増え、クラスタの数が増えていくと、pipelineに1つ修正を行うだけでとても大きなコストが発生してしまいます。また、クラスタの構築手順はすべて同じで、環境変数だけが違うだけという内容になっていたため、共通化できる部分も数多くありました。
解決方法
修正コストを下げる取り組みとして、Screwdriver.cdのconfigであるscrewdriver.yamlをpythonで生成し、簡単にpiplelineを修正できるようにしました。クラスタレベルの依存関係などもpython側で定義することで、jobの修正だけでなく管理するKubernetesクラスタの増減にも容易に対応できるようになりました。
今になって振り返るとscrewdriver.yamlを自動生成しないと修正が容易ではないほどの巨大なpipelineは組むべきではないという結論に至ってます。
あくまでケアレスミスを回避したり、修正・変更の容易さを目的としたコード化をおすすめします。
デプロイ目的別のpipelineを作成し、デプロイにかかる時間を短縮した
課題
ansibleでは冪等性を担保しながら構築を行っており、クラスタに関係するリリースはアプリケーションのレイヤーであっても、必ずOSの設定やKubernetesクラスタの構築なども含めてデプロイを行っていました。
これにより、必ずmasterブランチの内容が全体に反映されていることを保証できるため、「一部環境だけ設定が反映されていない」というようなオペレーションミスを防げた反面、pipelineが肥大化すると、「kubernetesアプリケーションの小さい修正なのに、全体のリリースで1日かかってしまう」という課題も発生しました。
自動化しているとはいえ、1日中リリースが行われているというのは、運用チームにとって心理的負荷でもありました。
解決方法
そのため、Kubernetesの構築と、Kubernetesアプリケーションのデプロイのpipelineを分離し、目的に合わせてデプロイを行うようにしました。

これにより、Kubernetesアプリケーションは「yamlの修正をapplyし、動作チェックを行う」だけのpipelineとなり、クラスタ全体に反映する時間が1時間未満となりました。
更新がない環境へもデプロイが走ることは、品質が保証できる反面、少なからずnodeを操作してしまうこととなるため、利用者への影響も回避することができました。
monorepo化をやめ、インフラレイヤーとアプリケーションレイヤーでリポジトリを分離する
課題
目的にあわせてpipelineを複数運用することで、全体的なデプロイ時間の短縮は達成できましたが、pipeline自体が減ったわけではありません。肥大化していることで、UI上からデプロイ状況を追うのが難しく、また1リポジトリが抱えるジョブ数としては多すぎるため、slack通知などで追うのが困難となっていました。
解決方法
そこで、目的別で分かれていたpipelineを基準にリポジトリを分離し、疎結合にしました。
分離することで、リポジトリが担う責務が明確化され、運用者がコードの修正を行うことも容易になりました。また、ソースコードも分離されたため、修正による影響範囲を小さくすることができました。Microserviceアーキテクチャと似ている気がしますが、それぞれの責務をシンプルに全うし関心事を極小化して疎結合性が増したと思います。
また、ansibleでdeployしていたKubernetesアプリケーションリソースをkustomizeを用いた管理に移行し、アプリケーション自体の運用コストの低減も行いました。
結果として、インフラレイヤーではKubernetesクラスタを構築することだけに注力し、アプリケーションレイヤーでは、kustomizeによる環境設定差分の管理だけを行えばよいという状態になり、デプロイにかかるコストを削減できました。
リリースのコストを下げ、リリース頻度を上げる
課題
リリースタイミングをコントロールする目的でgit-flowを採用していたため、リリースを行うごとにreleaseブランチの作成と、masterへのマージなどの作業を行う必要がありました。複数の修正をまとめてリリースするため、masterとdevelopブランチの差分が大きくなりがちです。追加した機能や修正した機能に内容によっては、差分が大きすぎる場合に意図しないバグが発生し、クラスタの構築が行えなくなる事が課題となりました。
解決方法
そこで、ブランチ運用をgit-flowからgithub-flowに変更し、リリースにかかる運用チームの負荷を低減し、またリリースの頻度を上げて本番環境との差分を小さくし全体的な品質を上げることを図りました。
以前は、変更による障害やユーザーへの影響に対する不安によりリリースタイミングをコントロールする意味でgit-flowを採用していました。Kubernetes運用者や利用者のKubernetesに対する知見が広がったこともあり、立ち上げ当時と比べ、チームが比較的安全に変更を加えられるレベルに達したため、git-flowのようにリリースフローにコストを掛けて安全を目指すより、小さくリリースするgithub-flowのほうが全体的に最適であると判断しました。
この変更により、リリースコストを下げることができ、リリースの頻度を向上させることができました。また、利用者への価値提供のサイクルも短くなり、よりリアルタイムに近い形で、Kubernetes利用者の要望を取り込むこともできるようになりました。
リリース頻度を上げるためには、品質を保証する必要がある
課題
github-flowを採用し、PRのマージとともに本番に反映される状態は理想ですが、品質を保証する必要があります。バグが残ったままのソースコードをmasterブランチにマージすると、本番のクラスタに影響を及ぼすためです。運用チームは気軽にPRをマージできず、品質を保証するために大きなコストが発生しスピード感が失われてしまいました。
解決方法
コストは下げつつ品質を保証するため、テスト環境のクラスタを作成し、受け入れテストを行った後に本番環境に反映するようにしました。
これにより、masterブランチに反映された内容が、クラスタに悪影響がないかをチェックすることができ、また動作が保証された変更だけが本番環境に反映されるようになりました。これで、運用チームのスピード感の維持、リリース頻度の向上、品質の保証が行われた状態となりました。
最終的なpipeline構成
これまでの課題と解決手段を取り込んだ最終的なパイプラインは以下の形となりました。
インフラレイヤー
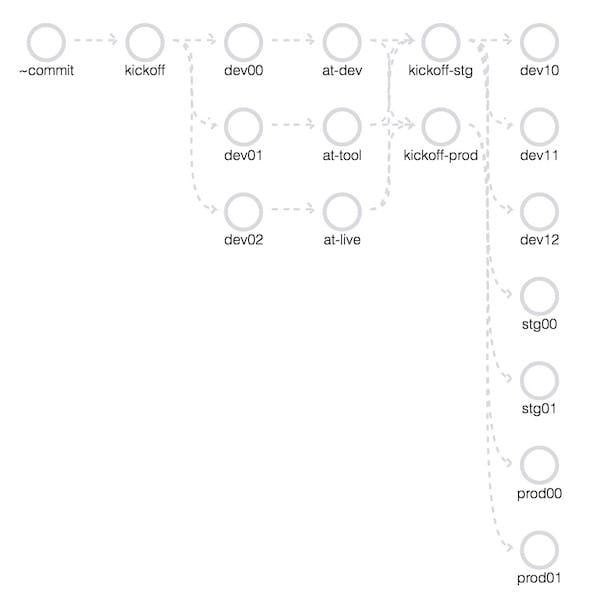
アプリケーションレイヤー
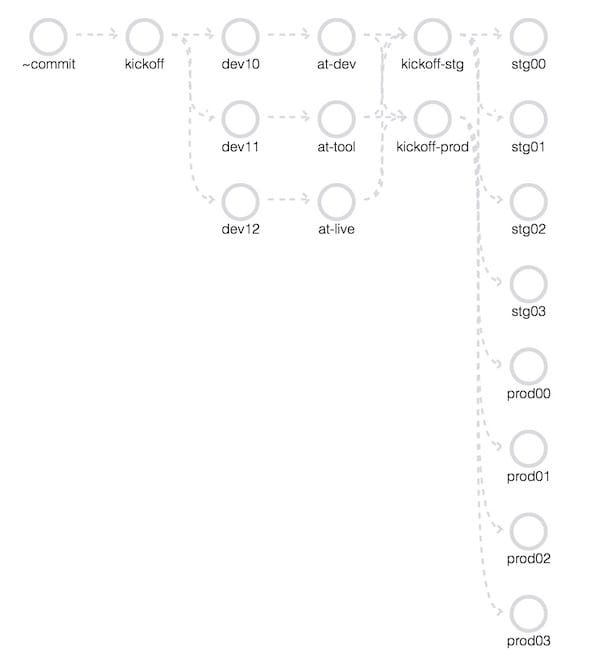
おわりに
monorepo化を行うことで、大規模なアプリなどでは修正コストが下がる・管理コストが下がるなどのメリットが挙げられます。その反面、pipelineの肥大化も避けては通れず、上記で挙げたような課題に直面することもあります。
今回は、責務の分離とスピード感を意識したためmonorepo化をやめるという判断を行いましたが、monorepoの中でももちろん解決策はあると思います。
大事なのは、「スピード感を失わず、なおかつ品質をどのように担保し、開発・運用を行っていくか」だと思います。課題と解決するための方針がずれなければ、どのような形であれより良いものが生まれると思います。
こちらの記事のご感想を聞かせください。
- 学びがある
- わかりやすい
- 新しい視点
ご感想ありがとうございました
- 岸本 涼
- CaaSエンジニア
- 社内向けCaaS環境を提供しています

- 村川 恒一郎
- CaaSエンジニア
- Kubernetesをベースとした社内向けプラットフォームの検討や構築を担当しています。



