以前「データモデリング基本」という記事でER図を作りました。
そこで今回はPostgreSQLを使い、ER図からデータベースを作り、テーブルの結合などを行なっていきたいと思います。
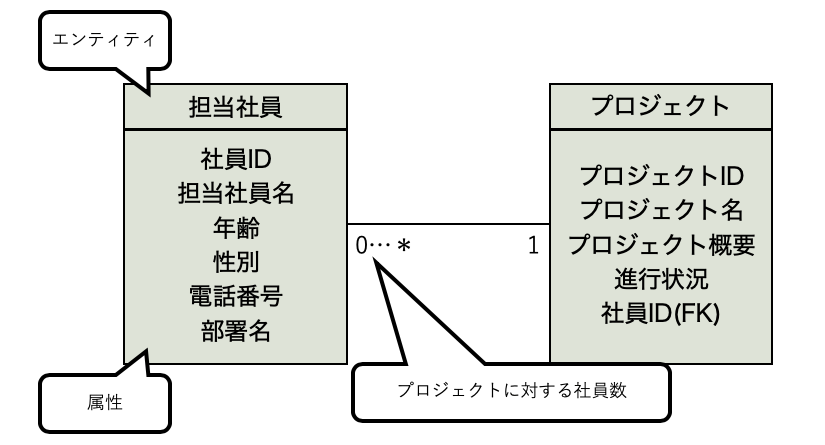
1. ER図の用意
今回は以下のようなER図を用意しましょう。
2. テーブルの準備
RDBMSのインストールを含めたSQLの基礎はこちらのURLをご覧ください。
まずは、以下のコマンドでPostgreSQLにログインします。
$ sudo su - postgres
$ psql
テーブルを入れるデーターベースを以下のコマンドで用意します。
今回は、プロジェクトのデータベースを作りたいのでproject_exというデータベース名にします。
postgres=# create database project_ex;
>
CREATE DATABASE
最後に
;をつけることを忘れないでください。
CREATE DATABASEと表示されたらデータベースの作成は成功です。
続いて、project_exデータベースに接続します。
postgres=# \c project_ex
>
You are now connected to database "project_ex" as user "postgres".
以上のように接続コマンドを入力し、You are now connected to database "project_ex" as user "postgres".と表示されたらデータベースへの接続は完了です。
続いて、このデータベースの中にテーブルを作成していきます。
用意したER図をみてください。
ER図のエンティティがテーブル名となり、
属性が列(カラム)となります。
それでは、担当社員テーブルとプロジェクトテーブルを作成していきます。
まずは、担当社員テーブルからつくるので以下のSQLを入力してください。
project_ex=# CREATE TABLE employee_list (em_id SERIAL PRIMARY KEY, em_name VARCHAR(10), age INTEGER, gender CHAR(1), phone_number INTEGER, department VARCHAR(6));
>
CREATE TABLE
CREATE TABLE employee_listで担当社員テーブルを作成しています。
社員IDをem_idとし、データ型を自動的に連続した数字が割り当てられるSERIAL、主キーに設定しました。
社員名をem_nameとし、データ型を10字以内の文字VARCHAR(10)に設定しました。
年齢をageとし、データ型を数字INTEGERに設定しました。
性別をgenderとし、データ型を1文字の文字CHAR(1)に設定しました。
電話番号をphone_numberとし、データ型を数字INTEGERに設定しました。
部署名をdepartmentとし、データ型を6字以内の文字VARCHAR(6)に設定しました。
CREATE TABLEと表示されたら、テーブルの作成は成功です。
念の為以下のように入力し、テーブルが作成できているか確認しましよう。
project_ex=# SELECT * FROM employee_list;
>
em_id | em_name | age | gender | phone_number | department
-------+---------+-----+--------+--------------+------------
(0 rows)
(0 rows)とは列が0という意味です。
続いて、プロジェクトテーブルを作成していきます。
以下のように入力してください。
project_ex=# CREATE TABLE project_list (pro_id SERIAL PRIMARY KEY, pro_name VARCHAR(16), overview TEXT, progress TEXT, em_id INTEGER);
>
CREATE TABLE
CREATE TABLE project_listでプロジェクトテーブルを作成しています。
プロジェクトIDをpro_idとし、データ型を「自動的に連続した数字が割り当てられる」SERIAL、主キーに設定しました。
プロジェクト名をpro_nameとし、データ型を16字以内の文字VARCHAR(16)に設定しました。
プロジェクト概要をoverviewとし、データ型を長い文字TEXTに設定しました。
進行状況をprogressとし、データ型を長い文字TEXTに設定しました。
社員IDをem_idとし、データ型を数字INTEGERに設定しました。
こちらも確認を行います。
project_ex=# SELECT * FROM project_list;
>
pro_id | pro_name | overview | progress | em_id
--------+----------+----------+----------+-------
(0 rows)
これでテーブルの用意は完了しました。
しかし、テーブルの中のデータが用意されていないので、以下のSQL文で各テーブルにデータを入れます。
project_ex=# INSERT INTO employee_list (em_name, age, gender, phone_number, department) VALUES ('太郎', '25', '男', '1234', '情報戦略部');
project_ex=# INSERT INTO employee_list (em_name, age, gender, phone_number, department) VALUES ('一郎', '39', '男', '2345', '事業開発部');
project_ex=# INSERT INTO employee_list (em_name, age, gender, phone_number, department) VALUES ('三郎', '33', '男', '3456', '情報戦略部');
project_ex=# INSERT INTO employee_list (em_name, age, gender, phone_number, department) VALUES ('よしこ', '24', '女', '4567', '情報戦略部');
project_ex=# INSERT INTO employee_list (em_name, age, gender, phone_number, department) VALUES ('ノブオ', '21', '男', '5678', '経理部');
project_ex=# INSERT INTO employee_list (em_name, age, gender, phone_number, department) VALUES ('イチコ', '45', '女', '6789', '社長室');
project_ex=# INSERT INTO project_list (pro_name, overview, progress, em_id) VALUES ('わくわく自動化', 'すべての事務作業を自動化する', '経理部自動化完了', '3');
project_ex=# INSERT INTO project_list (pro_name, overview, progress, em_id) VALUES ('わくわく自動化', 'すべての事務作業を自動化する', '経理部自動化完了', '4');
project_ex=# INSERT INTO project_list (pro_name, overview, progress, em_id) VALUES ('わくわく自動化', 'すべての事務作業を自動化する', '経理部自動化完了', '5');
project_ex=# INSERT INTO project_list (pro_name, overview, progress, em_id) VALUES ('炎上収束プロジェクト', 'サーバーの負担を軽減', '未着手', '1');
project_ex=# INSERT INTO project_list (pro_name, overview, progress, em_id) VALUES ('炎上収束プロジェクト', 'サーバーの負担を軽減', '未着手', '6');
project_ex=# INSERT INTO project_list (pro_name, overview, progress, em_id) VALUES ('RPGゲーム開発', 'ドラクエを超える!', 'ストーリー考案完了', '2');
社員IDとプロジェクトIDはSERIALなので、自動的に付与されます。
完了したら、以下のコマンドとSQLで各テーブルの確認などを行なってください。
project_ex=# \dt
project_ex=# SELECT * FROM project_list;
project_ex=# SELECT * FROM employee_list;
/dtはSQLではなく、PostgreSQLのコマンドです。
接続中データベースのテーブル一覧を見ることができます。
データの正規化
ちなみに今回のようにエンティティをテーブルで分割することで、データの管理がしやすくなりました。このような分割をデータの正規化と言います。
「データの正規化」とは、データの重複がないようにテーブルを適切に分割することです。 正規化されたテーブルを「正規形」、正規化されていないテーブルを 「非正規形」といいます。 非正規形のテーブルでは、データの重複があるため、データの矛盾や不整合が起こりやすく、正しく管理することが難しくなります。
引用:データの正規化
3. テーブルの結合
テーブルの結合は、SELECT文を使い、複数のテーブルを結合することで、複数のテーブルのデータを取得する方法です。
しかし、正しいデータモデリングが行われていなければいけません。
なぜならば、外部キーとなっている列の値を使って行う結合もあるからです。
外部キーを元にした結合
SELECT * FROM project_list JOIN employee_list ON project_list.em_id = employee_list.em_id;
>
pro_id | pro_name | overview | progress | em_id | em_id | em_name | age | gender | phone_number | department
--------+----------------------+------------------------------+--------------------+-------+-------+---------+-----+--------+--------------+------------
1 | わくわく自動化 | すべての事務作業を自動化する | 経理部自動化完了 | 3 | 3 | 三郎 | 33 | 男 | 3456 | 情報戦略部
2 | わくわく自動化 | すべての事務作業を自動化する | 経理部自動化完了 | 4 | 4 | よしこ | 24 | 女 | 4567 | 情報戦略部
3 | わくわく自動化 | すべての事務作業を自動化する | 経理部自動化完了 | 5 | 5 | ノブオ | 21 | 男 | 5678 | 経理部
4 | 炎上収束プロジェクト | サーバーの負担を軽減 | 未着手 | 1 | 1 | 太郎 | 25 | 男 | 1234 | 情報戦略部
5 | 炎上収束プロジェクト | サーバーの負担を軽減 | 未着手 | 6 | 6 | イチコ | 45 | 女 | 6789 | 社長室
6 | RPGゲーム開発 | ドラクエを超える! | ストーリー考案完了 | 2 | 2 | 一郎 | 39 | 男 | 2345 | 事業開発部
(6 rows)
JOINでproject_listとemployee_listを結合しています。
ONで条件がproject_list.em_id = employee_list.em_idであることを指定しています。テーブル名.列名ということを意味しています。
WHEREで条件を指定した結合
SELECT * FROM project_list JOIN employee_list ON project_list.em_id = employee_list.em_id WHERE department = '情報戦略部';
>
pro_id | pro_name | overview | progress | em_id | em_id | em_name | age | gender | phone_number | department
--------+----------------------+------------------------------+------------------+-------+-------+---------+-----+--------+--------------+------------
1 | わくわく自動化 | すべての事務作業を自動化する | 経理部自動化完了 | 3 | 3 | 三郎 | 33 | 男 | 3456 | 情報戦略部
2 | わくわく自動化 | すべての事務作業を自動化する | 経理部自動化完了 | 4 | 4 | よしこ | 24 | 女 | 4567 | 情報戦略部
4 | 炎上収束プロジェクト | サーバーの負担を軽減 | 未着手 | 1 | 1 | 太郎 | 25 | 男 | 1234 | 情報戦略部
(3 rows)
WHEREでdepartment = '情報戦略部'つまり情報戦略部の社員だけを抜き出したいます。
ORDER BYで並び替え
SELECT * FROM project_list JOIN employee_list ON project_list.em_id = employee_list.em_id ORDER BY employee_list.em_id;
>
pro_id | pro_name | overview | progress | em_id | em_id | em_name | age | gender | phone_number | department
--------+----------------------+------------------------------+--------------------+-------+-------+---------+-----+--------+--------------+------------
4 | 炎上収束プロジェクト | サーバーの負担を軽減 | 未着手 | 1 | 1 | 太郎 | 25 | 男 | 1234 | 情報戦略部
6 | RPGゲーム開発 | ドラクエを超える! | ストーリー考案完了 | 2 | 2 | 一郎 | 39 | 男 | 2345 | 事業開発部
1 | わくわく自動化 | すべての事務作業を自動化する | 経理部自動化完了 | 3 | 3 | 三郎 | 33 | 男 | 3456 | 情報戦略部
2 | わくわく自動化 | すべての事務作業を自動化する | 経理部自動化完了 | 4 | 4 | よしこ | 24 | 女 | 4567 | 情報戦略部
3 | わくわく自動化 | すべての事務作業を自動化する | 経理部自動化完了 | 5 | 5 | ノブオ | 21 | 男 | 5678 | 経理部
5 | 炎上収束プロジェクト | サーバーの負担を軽減 | 未着手 | 6 | 6 | イチコ | 45 | 女 | 6789 | 社長室
(6 rows)
ORDER BY employee_list.em_idで社員ID順に並び替えます。
以上で基礎的なデータの結合は終わりです。
次は外部結合と内部結合について扱いたいと思います。