モチベーション
ファッション画像検索サービス funnel でテキスト検索したくて入れてみました。
https://funnel-service.com/
Elasticsearchに大量のドキュメントを入れることは得意なんだけど検索するとなるとまったく素人だったのでやってみたら、結構難しかった。
専用の検索エンジンを作るって楽しい。
DSLを投げて思ったように検索できるようにすることを目標にする。
思ったようにとは・・
「PLST女性ノースリーブ」
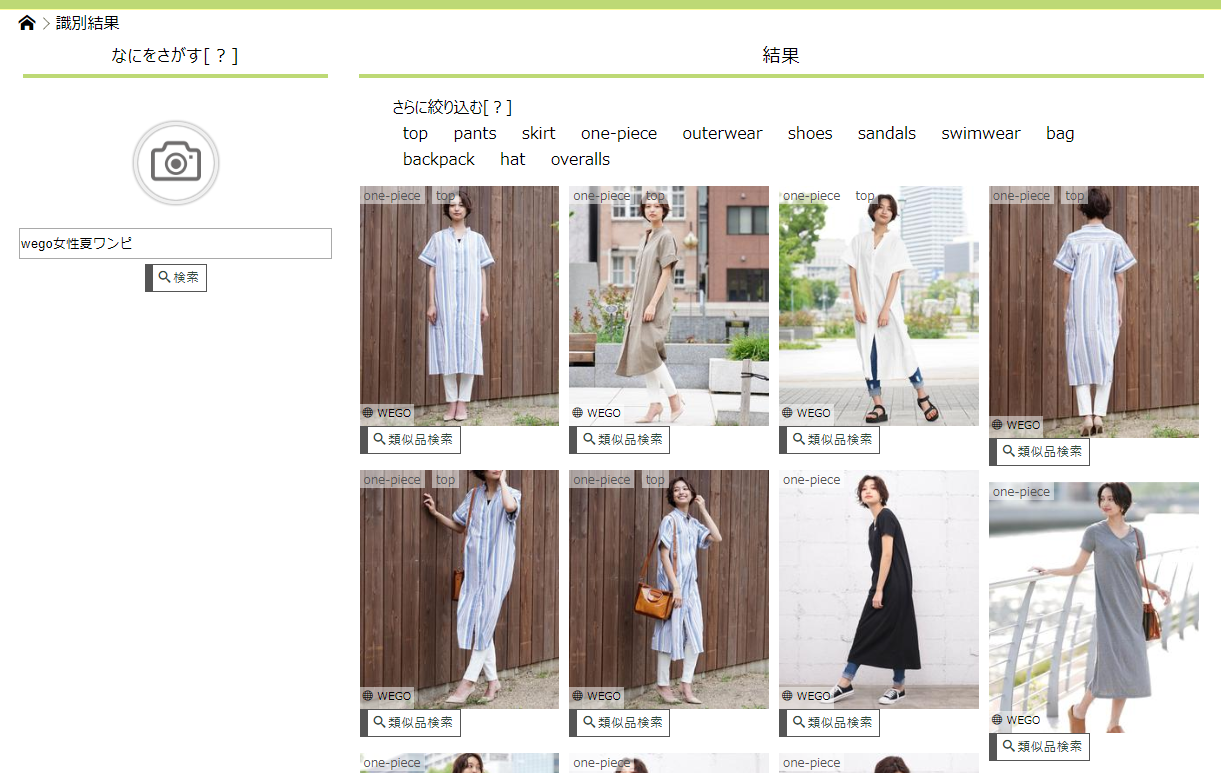
「wego女性夏ワンピ」
ブランド+性別+種類などでしっかり検索できること。
前提
元のドキュメントの構成
スクレイピングしたデータを以下のようなJSONで保管しときます。
{
"name": "【WEB限定】ブラウス",
"price": "4860",
"description": "オフィスにぴったり!",
"gender": "woman",
"age_bucket": "adult",
"main_objects": [
"top"
],
"url": "http://abcdefghijklmn1234567890.com/top/blouse/123456.html",
"item_category": "トップページ\nトップス\nブラウス",
"site_name": "ブランド名",
"DetailInfo": "発売日 2019/07/10\n品番 847825\nタイプ トップス\n",
"got_at": "2019-07-28 19:59:48"
}
こんな感じのデータをインデックスする前提で説明します。
main_objectsはスクレイピング後に、人間が「これはスカートやな」と判断していれている項目です。
(実際は・・・main_objects、genderの値は機械学習で推論させてます![]() )
)
セラーの検索機能で「スカート」を検索してもスカート以外も出てくるんですよね。
めんどい。
「wego女性夏ワンピ」で検索する場合
商品によっては
「女性」がgenderにだけ
「夏」はdescriptionにだけ
「ワンピ」はnameにだけ
と言うことがよくあります。
さらに「ワンピース」「ワンピ」とドキュメントで違ったりします。
「女性、woman」「ワンピース、ワンピ」どっちで検索しても同じ検索結果が出てほしいですね。
スキーマー
長いです。。
{
"settings": {
"index": {
"number_of_shards": 8,
"number_of_replicas": 0,
"refresh_interval": "1s",
"analysis": {
"analyzer": {
"analyzer_kuromoji_search": {
"type": "custom",
"char_filter": [
"icu_normalizer",
"kuromoji_ipadic_neologd_iteration_mark"
],
"tokenizer": "kuromoji",
"filter": [
"kuromoji_ipadic_neologd_baseform",
"jreadingform",
"kuromoji_ipadic_neologd_stemmer",
"stoptags",
"custom_synonyms"
]
},
"analyzer_kuromoji_index": {
"type": "custom",
"char_filter": [
"icu_normalizer",
"kuromoji_ipadic_neologd_iteration_mark"
],
"tokenizer": "kuromoji",
"filter": [
"kuromoji_ipadic_neologd_baseform",
"jreadingform",
"kuromoji_ipadic_neologd_stemmer",
"stoptags",
"custom_synonyms"
]
},
"analyzer_n_gram_search": {
"type": "custom",
"char_filter": [
"icu_normalizer"
],
"tokenizer": "ja_ngram_tokenizer",
"filter": [
"jreadingform",
"jstemmer",
"readingform_synonyms"
]
},
"analyzer_n_gram_index": {
"type": "custom",
"char_filter": [
"icu_normalizer"
],
"tokenizer": "ja_ngram_tokenizer",
"filter": [
"jreadingform",
"jstemmer"
]
},
"standardAnalyzer": {
"tokenizer": "standard",
"filter": [
"standard",
"lowercase"
]
}
},
"tokenizer": {
"kuromoji": {
"type": "kuromoji_ipadic_neologd_tokenizer",
"mode": "search",
"user_dictionary": "configs/userdict_ja.txt"
},
"ja_ngram_tokenizer": {
"type": "nGram",
"min_gram": "2",
"max_gram": "3",
"token_chars": [
"letter",
"digit"
]
}
},
"filter": {
"stoptags": {
"type": "kuromoji_ipadic_neologd_part_of_speech",
"enable_position_increment": false,
"stoptags_path": "configs/filters/stoptags.txt"
},
"hira2kata": {
"type": "icu_transform",
"id": "Hiragana-Katakana"
},
"jreadingform": {
"type": "kuromoji_ipadic_neologd_readingform",
"use_romaji": false
},
"jstemmer": {
"type": "kuromoji_ipadic_neologd_stemmer",
"minimum_length": 4
},
"readingform_synonyms": {
"type": "synonym",
"synonyms_path": "configs/filters/readingform_synonyms.txt"
},
"custom_synonyms": {
"type": "synonym",
"synonyms_path": "configs/filters/custom_synonyms.txt"
}
}
},
"similarity": {
"default": {
"type": "BM25"
}
}
}
},
"mappings": {
"dynamic": false,
"properties": {
"item_id": {"type": "keyword"},
"name": {
"type": "keyword",
"fields": {
"gram": {
"type": "text",
"search_analyzer": "analyzer_n_gram_search",
"analyzer": "analyzer_n_gram_index"
},
"kuromoji": {
"type": "text",
"search_analyzer": "analyzer_kuromoji_search",
"analyzer": "analyzer_kuromoji_index"
}
}
},
"price": {
"type": "integer"
},
"description": {
"type": "keyword",
"fields": {
"gram": {
"type": "text",
"search_analyzer": "analyzer_n_gram_search",
"analyzer": "analyzer_n_gram_index"
},
"kuromoji": {
"type": "text",
"search_analyzer": "analyzer_kuromoji_search",
"analyzer": "analyzer_kuromoji_index"
}
}
},
"gender": {
"type": "keyword",
"fields": {
"keyword": {
"type": "keyword"
},
"kuromoji": {
"type": "text",
"search_analyzer": "analyzer_kuromoji_search",
"analyzer": "analyzer_kuromoji_index"
}
}
},
"age_bucket": {
"type": "keyword",
"fields": {
"keyword": {
"type": "keyword"
},
"kuromoji": {
"type": "text",
"search_analyzer": "analyzer_kuromoji_search",
"analyzer": "analyzer_kuromoji_index"
}
}
},
"main_objects": {
"type": "keyword"
},
"cut_objects": {
"type": "keyword"
},
"url": {
"type": "keyword"
},
"item_category": {
"type": "keyword",
"fields": {
"gram": {
"type": "text",
"search_analyzer": "analyzer_n_gram_search",
"analyzer": "analyzer_n_gram_index"
},
"kuromoji": {
"type": "text",
"search_analyzer": "analyzer_kuromoji_search",
"analyzer": "analyzer_kuromoji_index"
}
}
},
"site_name": {
"type": "keyword",
"fields": {
"keyword": {
"type": "keyword"
},
"kuromoji": {
"type": "text",
"search_analyzer": "analyzer_kuromoji_search",
"analyzer": "analyzer_kuromoji_index"
}
}
},
"DetailInfo": {
"type": "keyword",
"fields": {
"gram": {
"type": "text",
"search_analyzer": "analyzer_n_gram_search",
"analyzer": "analyzer_n_gram_index"
},
"kuromoji": {
"type": "text",
"search_analyzer": "analyzer_kuromoji_search",
"analyzer": "analyzer_kuromoji_index"
}
}
},
"images_data": {
"type": "nested",
"properties":{
"file_name":{"type": "keyword"},
"image_id":{"type": "keyword"}
}
},
"search_fields": {
"type":"text",
"search_analyzer": "analyzer_kuromoji_search",
"analyzer": "analyzer_kuromoji_index"
},
"got_at": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ssZ",
"ignore_malformed": true
}
}
}
}
settingsの説明はここではしません。
元のドキュメントからsearch_fieldsが追加されてます。あとで説明します。
最初は余計なfieldを持っておいたほうがいいです。
たとえばマルチフィールドなど。
検索速度、インデンキシング速度に影響するので最終的にはとっちゃいますが、なにが必要でなにが不要かすぐに判断できませんし、
専用検索エンジンってことは大量ドキュメントにもならないでしょう。
"search_fields"の結合は、「copy_to 」をつかうとインデクサーで結合せずに、Elasticsearchがやってくれるらしいです。
got_atはそのままだと上記スキーマーで格納されますが、検索に使えません。
+0900をたして'got_at': '2019-10-29 01:06:29+0900'でインデックスする。
辞書とsynonym
辞書とsynonym(同義語)は合わせておきましょう。
シノニムにあって単語として認識されない場合は精度がわるくなります。
必ず_analyzerで確認します。
確認をしないでメンドクサイ思いをしました。
絶対確認しましょう!
DSL
{
"size": 10,
"query": {
"bool": {
"must": [
{
"simple_query_string": {
"query": "red",
"default_operator": "and",
"fields": [
"name.kuromoji",
"site_name.kuromoji",
"DetailInfo.kuromoji",
"item_category.kuromoji",
"gender.kuromoji",
"description.kuromoji",
"search_fields^0.8"
],
"minimum_should_match": 0
}
}
]
}
},
"highlight": {
"fields": {
"name.kuromoji": {},
"site_name.kuromoji": {},
"DetailInfo.kuromoji": {},
"item_category.kuromoji": {},
"gender.kuromoji": {},
"description.kuromoji": {},
"search_fields": {}
}
}
}
simple_query_stringを使って検索します。
検索エンジンの基本は「引っかけて」「上げる」ですが、専用ってこともあり入力された語がすべて満足するdocumentを引っかけます。
そのため「 "default_operator": "and"」にします。
「 "minimum_should_match": 0」がよくわかりません。1を指定してたら検索できないことがよくあるので、0にします。
「fields」には検索対象のfieldを列挙します「^n」はスコアの倍率を指定します。
「"search_fields^0.8"」で指定してます0.8の理由は・・・あとで説明します。
search_fieldsには検索させたい項目(name、site_name、DetailInfo・・・・)をスペースで結合した文字をいれます。
要は「search_fields」さえ検索すればなんでも引っかかるようにします。
だめだったパターン
search_fieldsがないとき・・・
{
"size": 10,
"query": {
"bool": {
"must": [
{
"simple_query_string": {
"query": "red",
"default_operator": "and",
"fields": [
"name.kuromoji",
"site_name.kuromoji",
"DetailInfo.kuromoji",
"item_category.kuromoji",
"gender.kuromoji",
"description.kuromoji"
],
"minimum_should_match": 0
}
}
]
}
},
"highlight": {
"fields": {
"name.kuromoji": {},
"site_name.kuromoji": {},
"DetailInfo.kuromoji": {},
"item_category.kuromoji": {},
"gender.kuromoji": {},
"description.kuromoji": {}
}
}
}
このパターンには"search_fields"がありません。
各fieldsごとには単一単語が存在するけどAND条件を満たさない場合はヒットしないです。
たとえば
"query": "赤 ワンピ"で検索し
"name.kuromoji"で、「赤」だけが含まれ
"item_category.kuromoji"で「ワンピ」だけがふくまれて
ほかの項目には検索ワードが含まれない場合、このドキュメントはヒットしません。
"search_fields"なら「赤」「ワンピ」の両方がヒットします。
しかし・・scoreをそのまま適応するのもの変な感じなので0.8倍にしておくといいです。
苦労したこと
synonymsで
女性,女,ウイメンズ,ウィメンズ,レディース,ladies,woman
を登録したのですが、どうしても変な言葉がsynonymで出てきて検索精度が落ちます。
「女性」で検索すると「エルエ」「ダイズ」がでてくるんです。
これはよくわからんので放置していたのですが、
そもそも検索されない言葉の組み合わせとか出てきたりして困りました。
原因は、「ladies」が「la→エルエー→エルエ」「dies→ダイズ」に分けられてしまい変な動作をしていました。
結果
↓こんな感じで「wego女性夏ワンピ」を検索(ワンピース、ワンピがシノニムです)
https://funnel-service.com/predictor.html?searchText=wego%E5%A5%B3%E6%80%A7%E5%A4%8F%E3%83%AF%E3%83%B3%E3%83%94&command=textSearch
↓こんな感じで「フリル」を「フリフリ」で検索
https://funnel-service.com/predictor.html?searchText=%E3%83%95%E3%83%AA%E3%83%95%E3%83%AA&command=textSearch&key=&id=&image_hash_code=
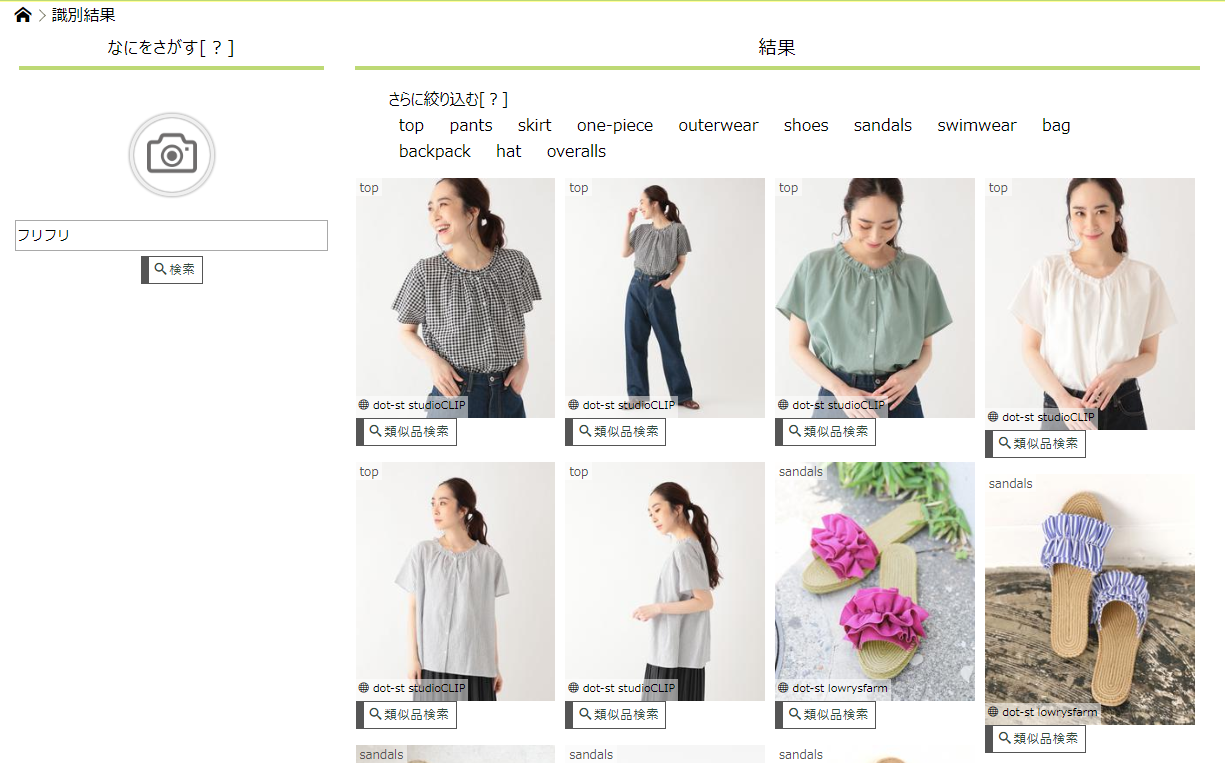
いい感じ!