概要
ElixirConf JP 2019用にコードを書いていた時の学びのまとめ
TL;DR
- 構造体はなるべく使わない(データ構造のモジュールでも!)
- mixとdoctestでTest-Driven Development(TDD)
- Comparatorを使う場合、Enum.sortのように引数変えたパターンマッチが良さげ
- パフォーマンス計測にBenchfellaが有用
- 品質管理にCIツールを導入しよう
ElixirConf JP 2019 Kokurajo
2019/09/07に開催されたElixirConf JPで"Data Structure in Elixir"というタイトルでLTをしてきました。時間の都合上、準備したもののほとんどが発表できなかったので、Qiitaで学びを共有しようと思うのですが、全体的な学びとしてTipsを最初に持ってくることにしました。この方針に従って(軌道修正したりして)コードを書いているのが一番の理由です。
TIPS
では本題です。
構造体はなるべく使わない
以前、Elixirでレイトレーサーの記事を書いたのですが、思いっきり構造体ベースでした…。自分の過去のコードが恥ずかしく感じるのは成長の証なので、ポジティブにいきましょう。ちなみに、すごいE本とかでレイトレーサーとかは対象領域だけど向いていないようなことがありますが、pythonに余裕で勝てたという意味ではありだと思っています。しかし、やっぱりC系の言語と比べるとそのままのpure-Elixirでは実用的でないのは確かです。
言語特性を考えよう
Elixirは、というかErlangもだと思いますが、データの扱いに関してはリストに特化して最適化されている用に思えます(要確認)。Enumerableのプロトコルを実装する際、基本的にリストを返さないと繋がらなかったり、リストベースでデータを扱う利点は大きいようです。
プログラミングElixirでも8.9項で「構造体は特に、闇に招かれやすい」「パラダイムを混在させて、関数型アプローチによって得られる利点を薄めてしまう」とあります。
この落とし穴(闇)から救ってくれたのは@zacky1972 先生でした。
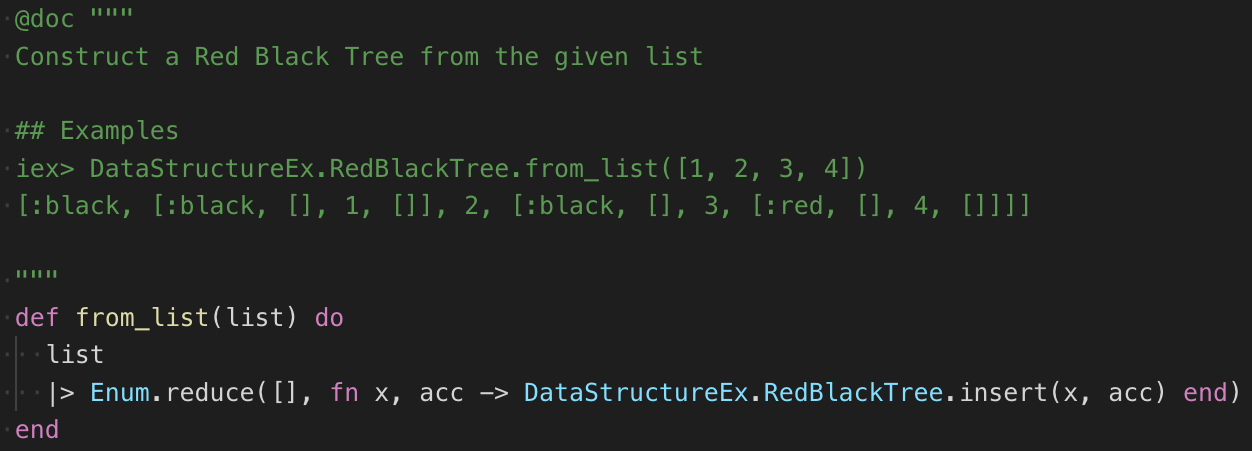
というわけで、構造体でデータを保持する作りから、リストやタプルを処理するモジュールとしてデータ構造を作成しました。この方針はErlangでも取られているようで、stdlibにいるデータ構造は大抵がリストやタプルで表現されたデータを処理するモジュールとなっています。
それにしても、データ構造を作って、中にデータを持たないという発想はなかった。
厳密にはデータ構造処理モジュールとでもいうのだろうか。OOPの呪いだ…。
TDDでいこう
テストのないコードはレガシーコードとレガシーコード改善ガイドで言われていますが、テストのカバレージの低いプログラムはほぼ趣味で1人でいじるコードです。他人に見せる状態になっていないと思います。例えCIツールが導入されていてもテストのカバレージが低いと正しく動いている保証はありません。最後のコミットで壊れているかも知れない。そんなパッケージを使いたいと思うでしょうか?
Elixirでのテストは簡単
おそらく大抵の人がmix newコマンドでプロジェクトの雛形を作っていると思います。mix phx.newとかかも知れません。mixの管理によるプロジェクト生成では基本的にテストフレームワーク、ExUnitが含まれています。これを使わない手はないでしょう。
Test-Driven Development(TDD)とは
提唱者はKent Beckですかね。アンクル・ボブことRobert C. Martinの著書の「Clean Code」や「Clean Coder」でもよく出てきます。
基本的な手法としては、想定される結果で先にテストを書いて、それが全て通るように実装していきます。具体的には関数のシグネチャが決まった時点でdoctestを書くのが良いと思います。書いたら一旦 mix testを実行します。当然ですが、空のケース等以外は失敗するはずです。そこから全てが通るように実装しつつmix testをこまめに実行していきます。1つ目,2つ目のケースが通って3つ目に着手していて、通るようになったら1ケース目が通らなくなる、というようなことも起きうるので、こまめに実行した方が原因の特定が容易になります。
doctestを書く際、@docで足すと思うので、ついでに関数の説明も書くと親切だと思います。同様に@moduledocも書くとしっかりしたコードに見えます。見た目は大事です。
あまりdoctestが多くなると煩雑になるので、どこかのタイミングでtest配下に移したほうがいいかも知れませんが、documentが立派になる面もありますし、使い方がコードを読んでてすぐわかるのも利点です。よっぽどでなければdoctestでいいと思います。
protocolの実装のdoctest
defprotocolに対してdefimplで実装を書いた場合、@docでのdoctestはそのままでは実行されないのでdoctest protocolname.modulenameのようにプロトコル名.モジュール名と指定します。
doctestに書くべきでないケース
- 副作用のある場合
副作用のある場合、doctestを書いてもあまり意味はありません。エラーが出ない確認程度になります。副作用があるというのは、例えば乱数を生成したり、標準入力を受け入れるものです。外のスコープの影響の場合もあります。基本的に、関数の引数のみで結果が一意に確定する場合は副作用がないと言います。副作用がない関数はなるべくdoctestでカバーするのが良いと思います。
忘れずに
"greets the world"テストが残ってるとかっこ悪いので必ず消しましょう。
Comparatorの設定
Comparatorとは
Comparatorとは比較演算を指定するものです。これを使うことで数値型以外のデータも比較が必要なデータ構造(例えば二分木やヒープ)に適用できるようになります。
Elixir内の実装を見てみる
例えばEnum.sort/1は
def sort(enumerable) when is_list(enumerable) do
:lists.sort(enumerable)
end
def sort(enumerable) do
sort(enumerable, &(&1 <= &2))
end
となっています。1つ目はリストの場合、Erlangのlistsモジュールに移譲していますが、2つ目は比較演算子を使った無名関数を渡しています。
ではEnum.sort/2も見てみましょう。
def sort(enumerable, fun) when is_list(enumerable) do
:lists.sort(fun, enumerable)
end
def sort(enumerable, fun) do
reduce(enumerable, [], &sort_reducer(&1, &2, fun))
|> sort_terminator(fun)
end
1つ目はlistsに渡していますが、funパラメータを渡しています。降順にしたい場合は

という風に適用でき、同じ用に2つ目でもsort_reducerの中でfunが実行されて比較されています。
自前のデータ構造でもこの感じで引数が1つなら&(&1 <= &2)を適用した引数2つの関数を呼び、指定したい場合は最初から引数2つの方に関数を渡せばOKです。
Pros and Cons
メリットはもちろん、任意の型に対して、また昇順・降順を変えたり自由な並び方ができることですが、デメリットはガード節でわかりやすく簡潔に関数が書けないことです。ガード節では基本的にKernelのコードで@doc guard: trueのものしか使えないので(自分のコードにこれを書いてみましたが当然無理です)、引数に渡した比較関数は論外です。
末尾再帰は再帰より速いとは限らない
スプレーヒープの実装時に、リストとスプレーヒープの比較だけでなく、末尾再帰と普通の再帰でのパフォーマンスの比較をしたところ、通常の再帰の方が僅かに速い計測結果が出たりしました。
末尾再帰を使う一番の理由はスタックの問題の解決のための最適化(関数呼び出しは処理が戻ったときに再現できるように状態をスタックに積むので、再帰が深くなるとスタック領域があふれる、いわゆるスタックオーバーフローが起きるため、スタックに積まないで結果を返せばいいように最後に関数呼び出しの結果をそのまま返すようにすればスタックを積まないでよい)が目的ですが、スタックを出してレジスタに詰めながら戻っていくと考えると同じ速度で動作しても末尾再帰の方が全然速いように思えます。
Erlangのパフォーマンスに関する8つの都市伝説でも触れていますが、最適化の工場により末尾再帰の方がメモリ量(スタック)も速度でもメリットがあるとは限らなくなっているようです。ただ、最適化が上手く機能しない可能性もあると思いますので、末尾再帰にしておいた方がコンピューターに確実に優しいとは思います。
Benchfellaでパフォーマンス測定
記事の単位が大きくなったので、別の記事に分けました。
Elixirのパフォーマンス測定にBenchfellaを使ってみたをご覧下さい。
CircleCIを動かす
こちらも記事を分けました。
ElixirでCircleCI(GitHub連携も)をご覧下さい。
まとめ
- 色々新しいライブラリとか出てるのでフォローするの大変
- CI入れましょう